1. 了解计算机辅助翻译工具(CAT工具)
如果你不是小白啦!如果你已经很熟悉CAT啦,那很好,这一节你可以略过。
1.1 为什么要使用CAT工具?
首先我们先来看两组数据,其中
第一组数据:
- 图1 是来源于2021年CSA的数据,数据显示:受疫情影响,2020年全球语言服务产值为484.0亿美元,较2019年出现小幅下降。在经济重启的背景下,2021年全球语言服务产值呈现回暖趋势,预测达到516亿美元。(来源:Common Sense Advisory,2021)
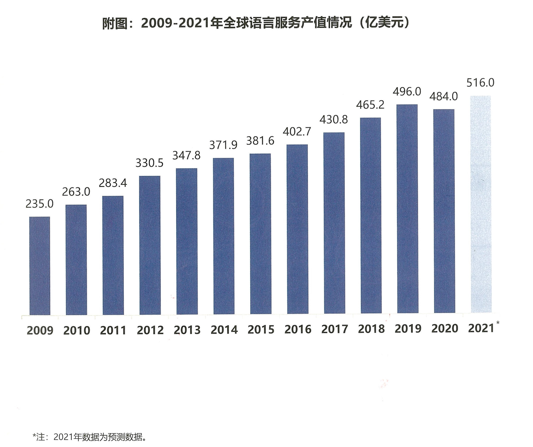
图1-2009至2021全球语言服务器产值情况(亿美元)
- 图2 对比了2015至2021年国内行业产值,以亿元为单位。数据显示:近年来,国内语言服务行业产值持良好增长态势,从2015年的282.2亿元稳步上升到2021年的554.5亿元,涨幅达50.9%。(来源:2022年中国翻译及语言服务行业发展报告,2022)
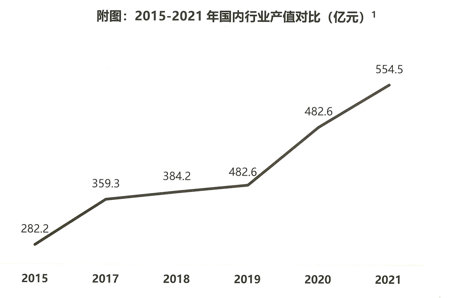
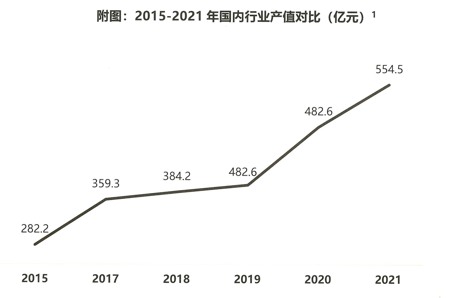
图2-2015至2021年国内行业产值对比(亿元)
第二组数据:
- 图3为截至2021年底,国内语言服务行业在营企业数及规模统计情况。统计显示:
- 截至2021年12月31日,中国含有语言服务企业423,547家,相较于2019年底增加了20452家;语言服务为主营业务的企业9656家,相较于2019年底增加了806家。
- 语言服务为主营业务的企业全年总产值为554.48亿元,相较于2019年年均增长85.24亿元,年均增长率为11.1%。(来源:2022年中国翻译及语言服务行业发展报告,2022)
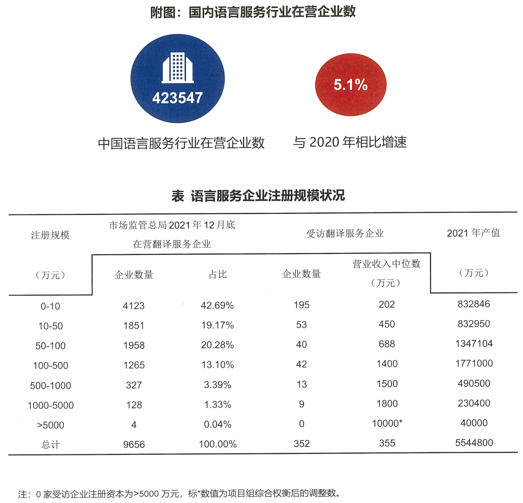
图3-国内语言服务行业在营企业数及规模统计
以上皆出自于2021年语言服务行业发展报告。
请大家试想一下,
- 若按照传统的翻译,以上工作能否完成呢?
- 如果可实现,需要多久呢?
在我看来,若按照当下的发展要求,传统的翻译工作“费时低效”,仅凭人力和简单的组织是无法高效高质量完成翻译工作的。
所以,在这个时候,我们就需要一个工具来解决“费时低效低质量”的问题,也就是帮助我们提高质量、提高效率。
那,这样一款工具到底是什么呢?就是计算机辅助翻译工具,英文名Computer-Assisted Translation Tool,缩写CAT tool。
随着翻译技术的发展,越来越多企业开始应用翻译技术,认为翻译技术可以帮助提高翻译效率、提高翻译质量,降低翻译成本。
根据2020年中国语言服务行业发展报告显示,从语言服务需求方的角度来看,有92.9%的翻译语言服务需求方受访者认同翻译技术的使用能够提高翻译质量,86.1%的需求方受访者认同翻译技术的使用能够降低翻译成本并提高效率。
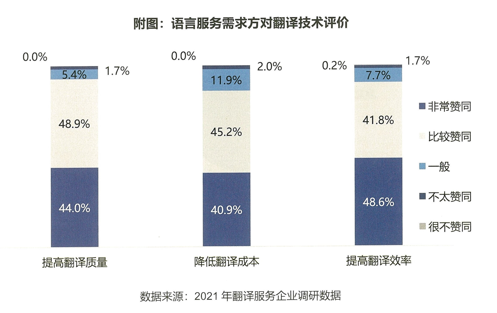
图4-语言服务需求方对翻译技术评价
所以,CAT可以:
- 提高翻译效率;
- 提高翻译质量;
- 降低翻译成本。
咦,细心的宝宝们也会发现,这是不是就是我们项目管理的“铁三角”嘛!是的!
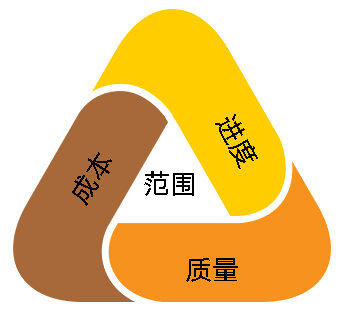
图5-项目管理铁三角
但是今天项目管理不是我的重点,我们的重点是:CAT好用,好就对了!用就对了!
可是,刚刚我只是讲了CAT的好处,那”什么是CAT工具呢?“
1.2 什么是CAT工具
对于CAT的定义有很多,但是我个人偏向的是徐彬老师在2007年提出的,CAT工具有狭义和广义之分:
- 狭义的CAT工具专指为提高翻译效率、优化翻译流程而设计的专门计算机辅助翻译软件,如翻译记忆软件等;
- 广义的CAT工具包括所有服务翻译流程的软硬件工具,如常用文字处理软件、光学字符识别(OCR)软件、电子词典、电子百科全书、搜索引擎及桌面搜索等。(徐彬,2007)
所以说,按照狭义CAT的概念,memoQ是一款CAT工具;
而按照广义CAT的概念,其实word也可以是一款CAT工具。因为word本身就是一款计算机工具,也是服务翻译流程的,对不对。再比如我们现在用的语音识别,也是广义的CAT工具。所以我们发现,其实我们也是很早就开始接触计算机辅助翻译工具了,它对我们也并不是很陌生。
——现在你知道大家常常说的CAT是什么了吧!
1.3 CAT和MT的区别
之前,经常有小伙伴问我,CAT=MT吗?奥夫考斯闹特呀!
——其实通过英文也不难发现,CAT可不是是MT,CAT=Computer-Assisted Translation=计算机辅助的人工翻译,所以,CAT的主体是人,是人在做翻译。
而MT呢?如图5所示,MT=Machine Translation=机器翻译,是用计算机把一种语言翻译成另一种语言。所以,MT的主体是machine,是计算机,是计算机在做翻译。
所以,MT就可以在很大程度上提高翻译效率!
图6-机器翻译
咦,有了这个认识,那我们发现,是不是就可以将MT+CAT结合呀?是的是的!
如图6显示,根据2022年语言服务行业发展报告,91%的语言服务企业认为采用“机器翻译+译后编辑”模式提高了效率,其中有25%的受访者认为“极大提高了效率”;有66%的受访者认为“提高了一些效率”。

图7-MT+CAT的效率统计
如果你看到这里,你已经发现,CAT可以帮到你。
那它是怎么帮助到你的呢?其实是通过以下的技术。
(但今天我只讲简单的技术,你跟着我的思路,慢慢来,你会慢慢越来越棒!)
2. 以memoQ为例,了解CAT的基本技术
推荐你购买这本书:《计算机辅助翻译概率》,是华树老师编的,很详细地跟大家讲解了CAT的各个技术。
都给我买!!!

2.1 CAT如何帮助提高翻译效率
在提高翻译翻译效率方面,CAT具有:
- 2.1.1 翻译记忆技术;
- 2.1.2 匹配率;
- 2.1.3 语词检索(一致性检索);
- 2.1.4 解析器(简化翻译格式);
- 2.1.5 语料对齐;
- 预翻译、X-翻译等译前处理操作;
- 复制原文至译文、等快速编辑操作;
2.1.1 翻译记忆技术
关于memoQ中的翻译记忆库,详见memoQ三种类型的记忆库如何帮助提高翻译质量/什么是工作记忆库、什么是主记忆库、什么是参考记忆库。
什么是翻译记忆技术呢?
- 译员在翻译过程中,将翻译句对(匹配源句段和目标句段)存储至的数据库(Translation Memory,简称TM)。
- 换句话说,翻译记忆技术是翻译技术的核心,有助于保持翻译的一致性,提高译员的本地化效率,同时提高翻译质量。
翻译记忆是如何工作的?
- 翻译记忆在CAT工具后台工作。
- 译员每翻译一句话,会把这句话的原文和译文(即句对)存储在TM中;
- 下次再遇到相同或类似的句对时,系统会自动给译员提供记忆库中的翻译建议,实现“翻译过的内容无需再次翻译”。——这个原理有一点像,我们以前高考的时候老师让背范文。只有先背过在脑子里(记忆库),然后才能在写作文时从脑子里搬出来用(从记忆库中在翻译中用)。
使用翻译记忆有什么好处?
- 加快翻译速度:如图8所示,TM根据翻译过的句段为当前相同的译文提供参考建议,仅在数字,标记,格式,标点符号或间距等方面存在差异。
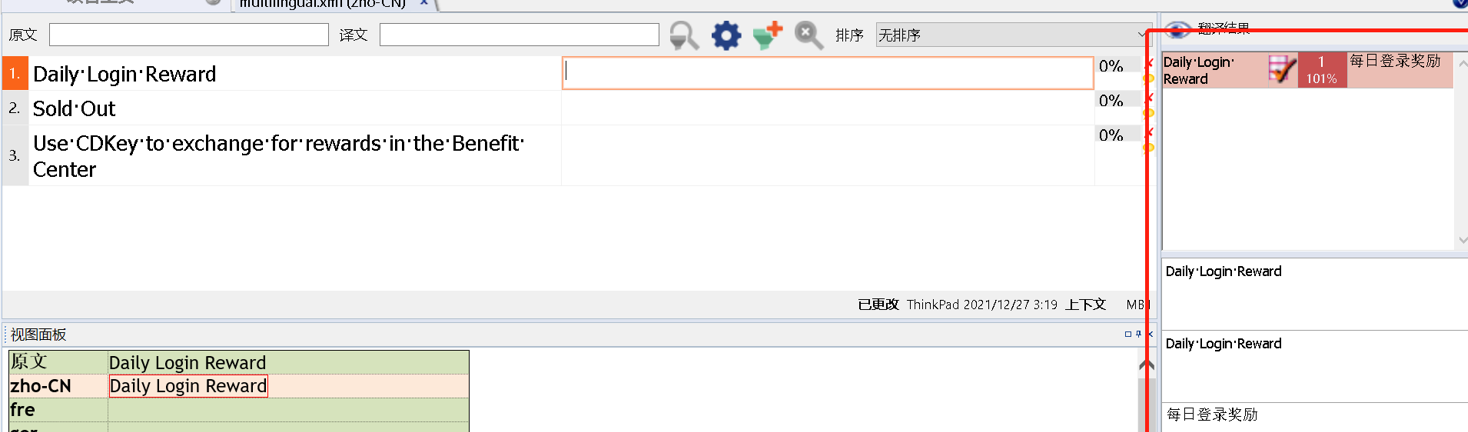
图8-TM加快翻译速度
- 降低翻译成本:若源文档中有许多重复性文档,如:网站、游戏、合同、产品手册等,可以根据记忆库计算重复率,要求供应商降低计费或者设置加权计费,如图9所示。
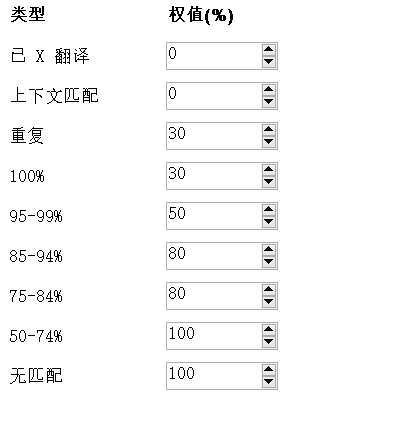
图9-TM降低翻译成本
- 提高翻译质量:其实通过翻译记忆库也可以提高翻译质量:通过存储正确的表达和句子,防止出现译文不一致的现象,尤其是在进行多人协作翻译一篇文档或一个项目时,非常有用,比如图10.

图10-TM提高翻译质量
翻译记忆库的交换格式
记忆库的交换格式是*.tmx格式,如果我们用文本编辑器打开的话,会发现它也是xml格式的一种。
如果你不知道XML格式是什么,你可以先放放,或者你也可以看我之前写的认识XML文档(一)什么是XML文档?
在这个文档中会标注原文的id,创建者,英文的句段,中文的句段等,通过TMX标准可以实现不同CAT之间翻译记忆库的互换。
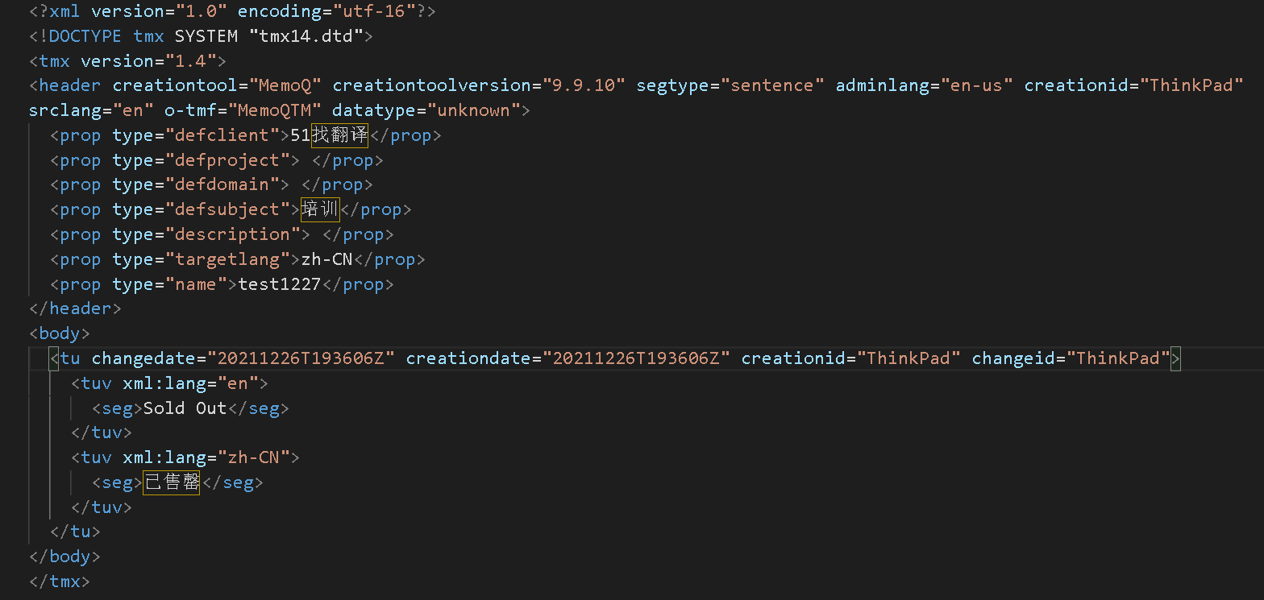
图11-翻译记忆库tmx格式
如果这个文档在memoQ中打开,你看到的就不是代码,而是左列原文,右列译文的句对。
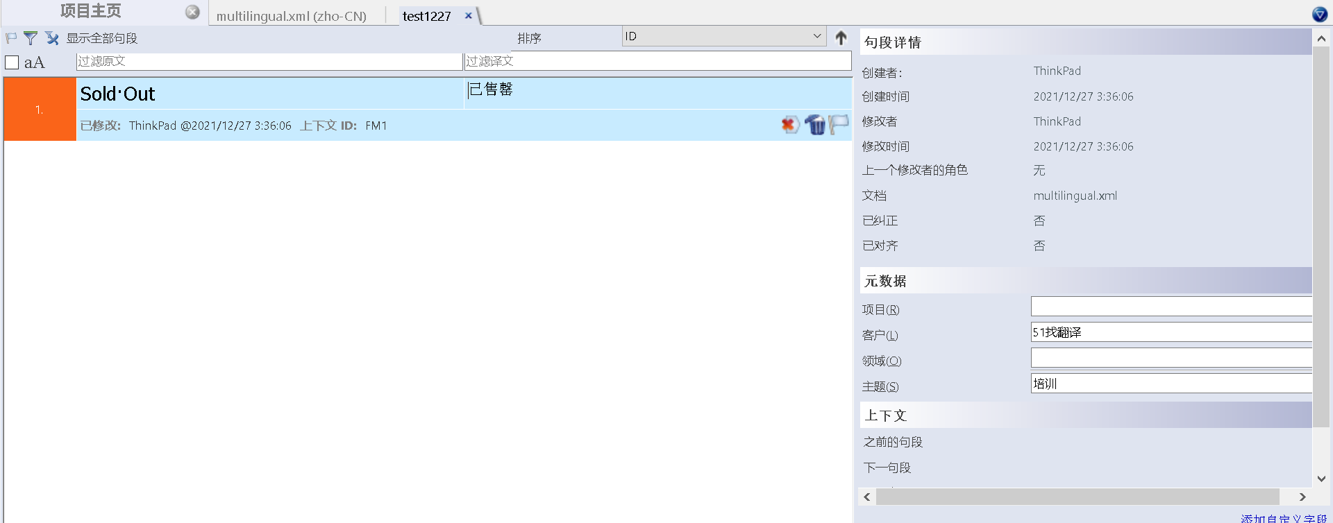
图12-在memoQ中打开翻译记忆库
2.1.2 匹配率
如果有重复的句段,记忆库会给参考建议,甚至自动沿用。那这个技术其实原理就来源于匹配率。
匹配率是什么呢?
判断记忆库中已有句段与待译句段的匹配度有三种结果:
- 完全匹配
- 模糊匹配
- 上下文匹配
完全匹配指已有句段与待译句段在拼写、标点、句型变化上完全相同,也就是100%匹配,即perfect match。
比如我们看图13中,当前翻译的第四句和前面的第2句是一样的,所以第4句这里,右侧记忆库中就是100%匹配,包括大小写。

图13-完全匹配
模糊匹配指已有句段与待译句段在拼写、标点、句型变化上存在变化,是不完全匹配,即1-99%匹配,即fuzzy match。
我们看图14的第4句,记忆库匹配就是99%匹配,为什么呢?因为大小写不一致。
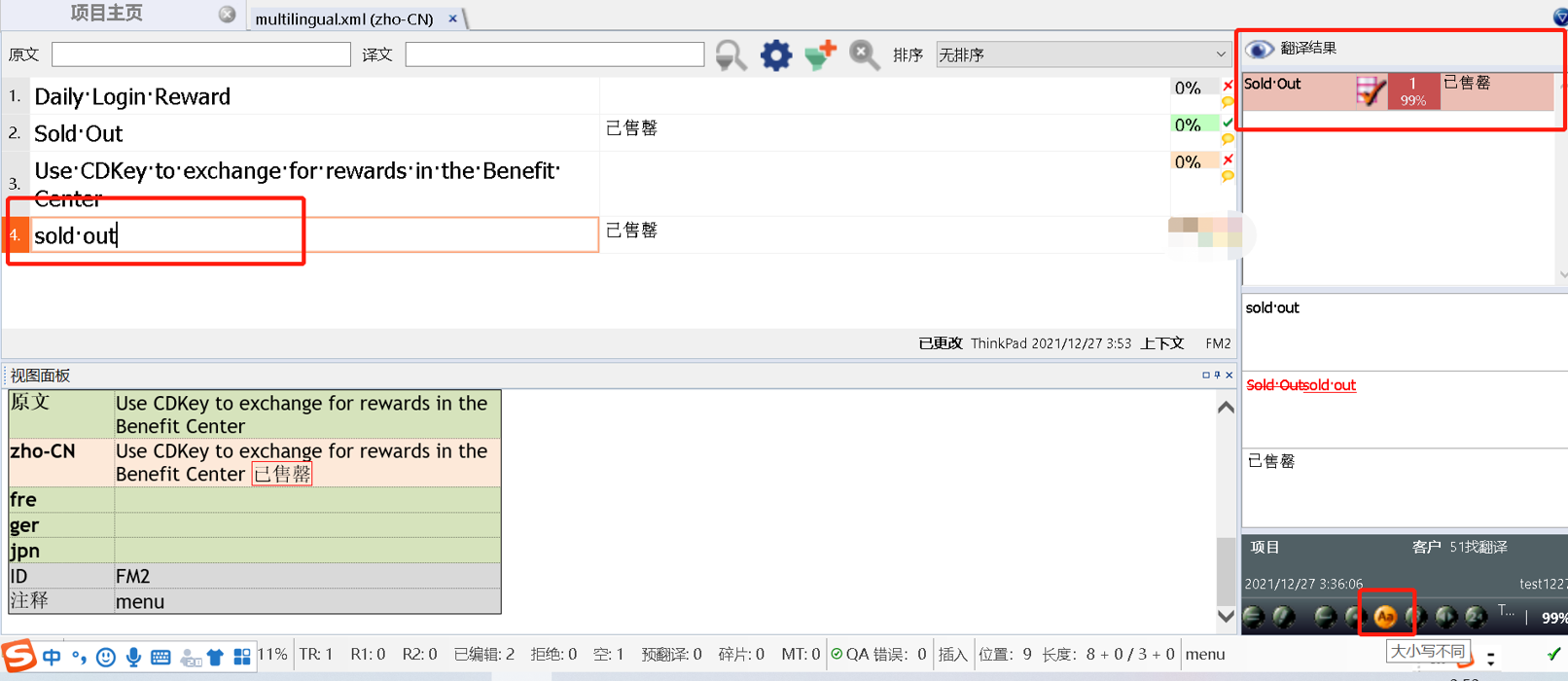
图14-模糊匹配
那上下文匹配又是什么呢?
除了达到100%匹配(完全匹配)之外,上下文匹配(context match)还考虑到了句段的上下文情况,即两个句段的上下文必须完全相同(也就是前一句段也必须完全相同)。
不同的CAT工具对上下文的匹配的标识不一样,memoQ中是上下文匹配是101%匹配,如图15所示。

图15-上下文匹配
补充:对于memoQ而言,还有一个双重上下文,匹配率更高啦!(要不它好呢~)——以后分享!
匹配率有什么作用呢?
我们可以通过匹配率来判断记忆库的准确值与否,记忆库匹配率越高,表示当前句段提供的准确度越高。
另外,在memoQ中,我们也可以设置匹配门槛:匹配率在多少以上的记忆库条目是有参考价值的,如60%。而一般匹配率在50%以下的,我们就觉得对准确度非常低了,所以记忆库的参考意义就不大了;
也可以设置罚分,比如,假设本来匹配率是100%,但是我们认为,如果是小王翻译的就减10分,这样小王确认的,匹配率就变为100-10=90%匹配了!

那,匹配率低就没有参考价值了吗?当然不是!我们还有其它的技术可以使用这些低匹配率的记忆库条目。最典型的应用就是2.1.3 语词检索。
2.1.3 语词检索(一致性检索)
关于语词检索,详见CAT的语词检索(一致性检索)。
语词检索是什么?
语词检索也叫相关搜索( Concordance )。
前面我们讲了,翻译的过程中你可以在记忆库中看到之前翻译过的参考译文,但是前提是,必须达到一定的匹配率。
那,如果没有达到该匹配率怎么办呢?如果匹配率太低,怎么办呢?比如,翻译结果区呈现的记忆库结果默认只会显示60%以上匹配的内容,所以如果匹配率在60%以下,怎么办呢?
——这时,就要用到语词检索功能了:你可以在记忆库中搜索某个特定的词汇、词组、短语及其所在的句段。
比如下图中,当前句段(第5句段)没有任何记忆库参考。

图16-翻译结果区
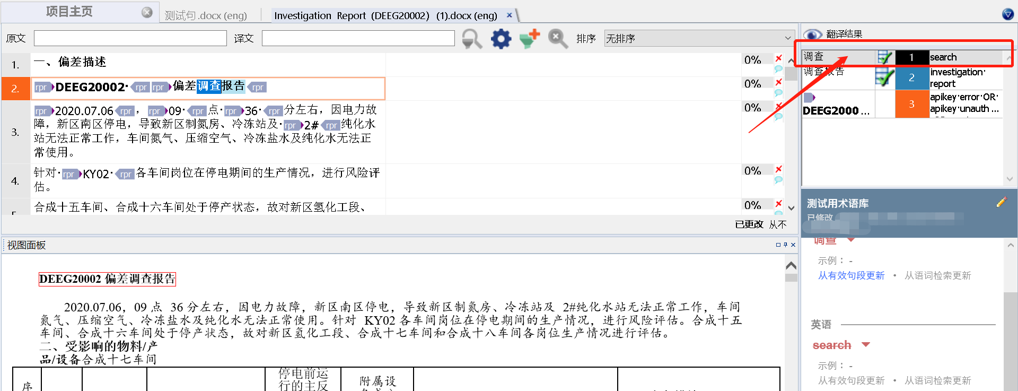
但是实际上,你曾经翻译过类似的内容,所以如果你想在记忆库中查一下,某个词,比如①”this”在记忆库中是如何翻译的,就可以使用②”语词检索(Concordance)”功能,这样你就可以知道:③”哦!原来之前是这样翻译的!”如图17所示。
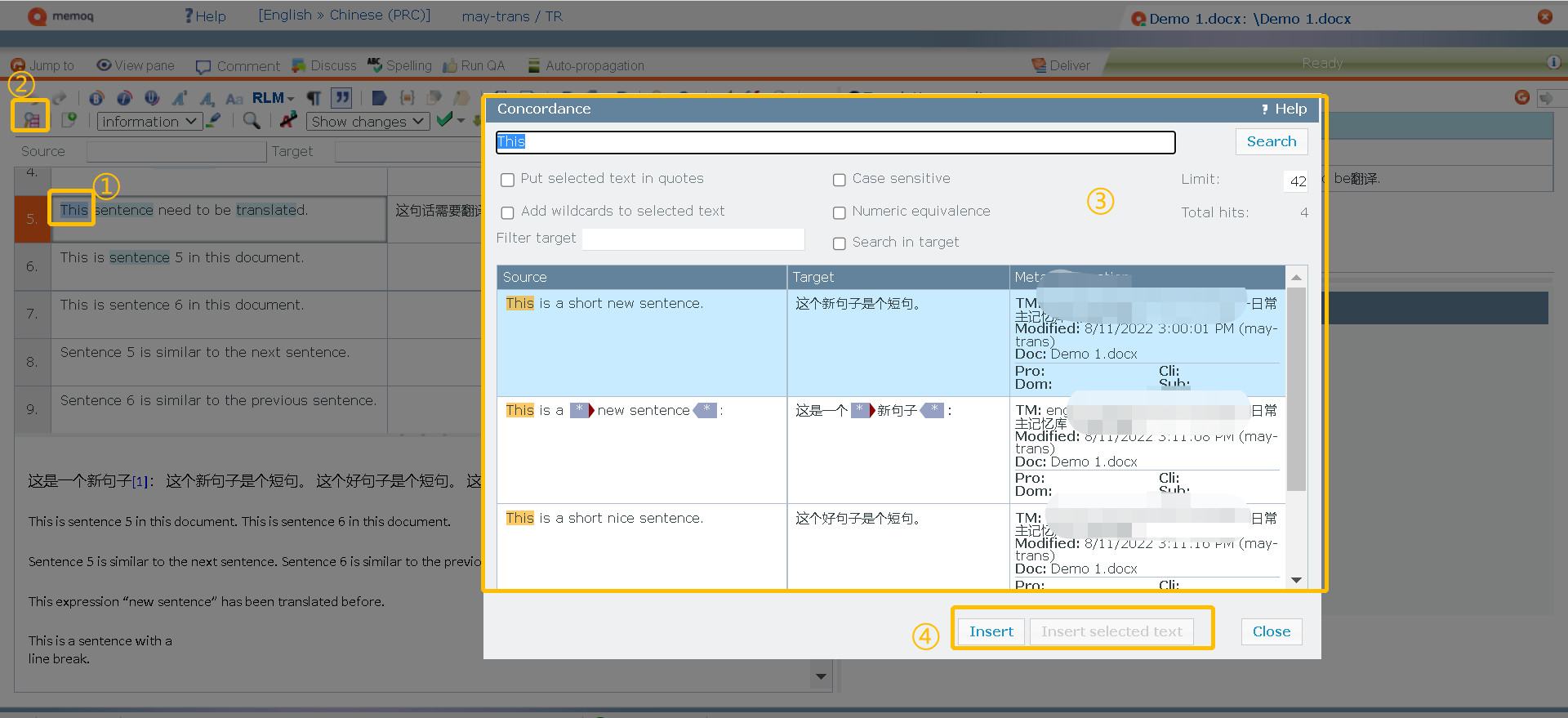
图17-使用语词检索
然后如果你需要,你就可以使用④”插入”按钮,插入需要使用的译文啦~
这样是不是也可以加速你的翻译呀,从此再也不用担心找不到哪个词啦!
2.1.4 解析器(简化翻译格式)
判断一款CAT工具好还是不好,并不仅仅是靠记忆库和术语库,还有一个很重要的技术,就是解析器技术。也就是说:这个CAT能解析多少文档?解析到什么程度?——这是经常被忽略的一点。
那,什么是解析器?
不论你的原文是什么,CAT工具都会用自己的解析器,将你各种各样的原文格式,解析为XLIFF格式,从而直接处理.html、.xml、.rtf、.docx、.json、.srt等文件。
所以,你会发现,如图18所示,你的原文虽然是word文档,但是导入到memoQ中,会自动帮你解析出原文,所以你看到的是左边是原文,右边是译文。
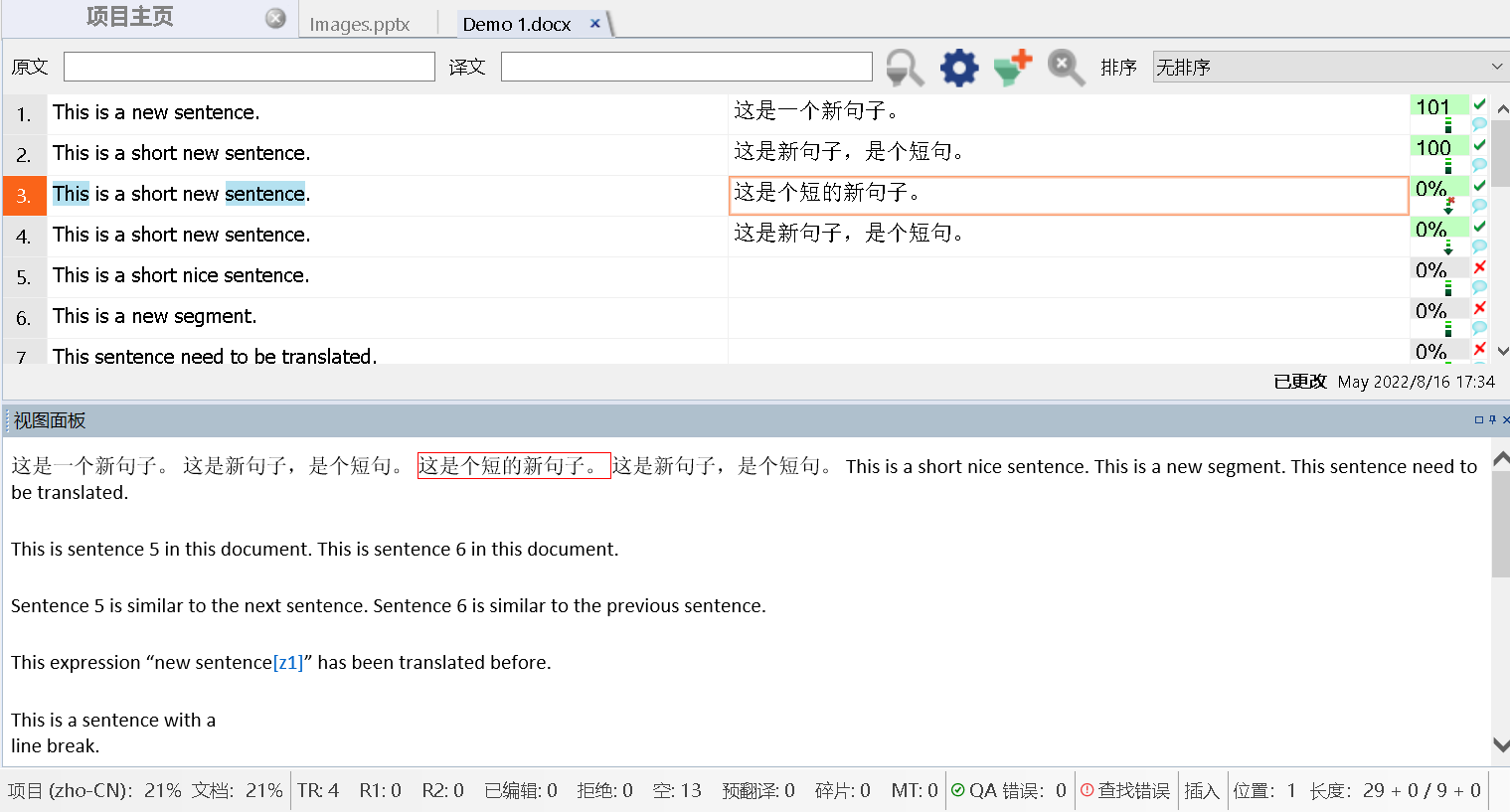
图18-memoQ中的word文档
你的原文虽然是xml文档,但是memoQ依然帮你解析出原文,你仍然只需要看左边的原文,在右边的译文区翻译即可,不需要考虑代码和格式。
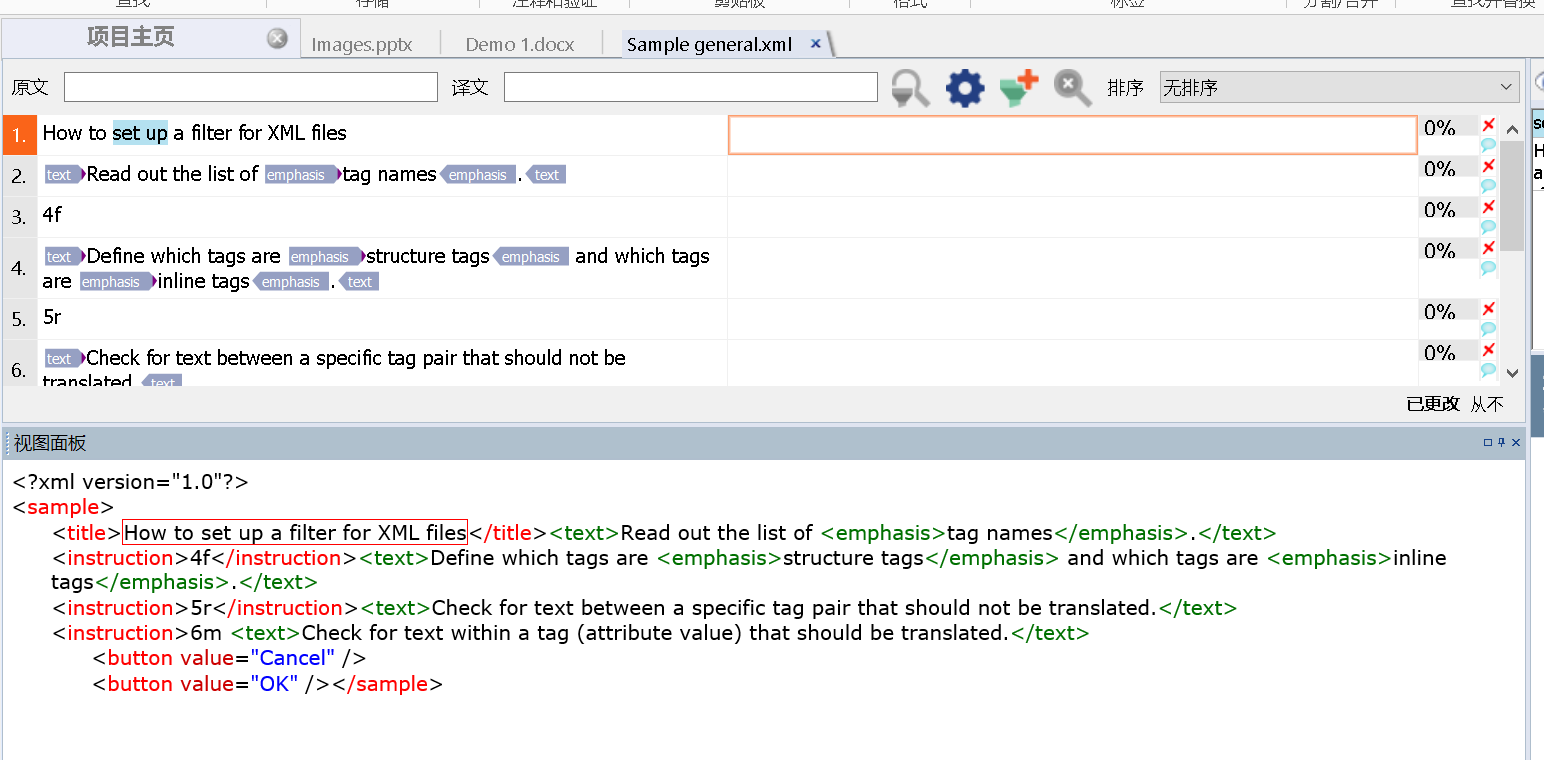
图19-memoQ中的xml文档
memoQ的强大在于,只要你的文档是可编辑的,它都能帮你解析!
在memoQ中,不同文档在导入时会使用不同的解析器,默认情况下,文档在导入时会按照默认的后缀名的解析器进行解析,如.html用HTML过滤器。

图20-memoQ的解析器
而且,memoQ的更强大在于,你还可以针对文档需求,自定义你的解析内容。
也就是说,你可以自定义:哪些要翻译,哪些不翻译。
比如,如图21所示,假设原文档是excel表格,你可以自定义哪些工作表要导入,哪些文本框的内容要导入,甚至是否导入索引,是否导入注释等等。
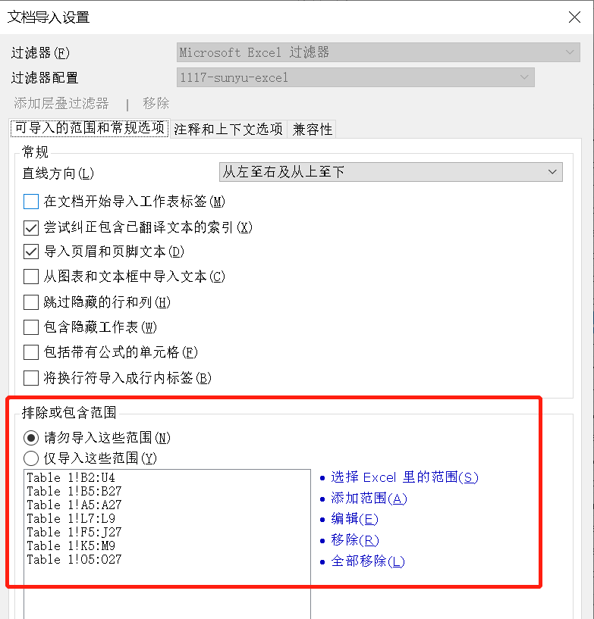
图21-memoQ的自定义解析器
当然,不懂也没关系,你现在只要知道:CAT工具会将你的原文解析为XLIFF格式,就可以了。
那,XLIFF是什么?
你只要知道概念就好了,不懂没关系,你也不需要深入研究,只知道,”XLIFF”这个概念就好了。
如果你是小白,真的现在不用深究,慢慢来~听我的,慢慢来~
XLIFF(XML Localisation Interchange File Format),即XML本地化交换文件格式,是一种基于XML的交换格式。
你看,这里也有标签对、根元素、子元素等等XML具备的特征嘛对不对,点击认识XML文档的元素、标签、文本、属性和实体
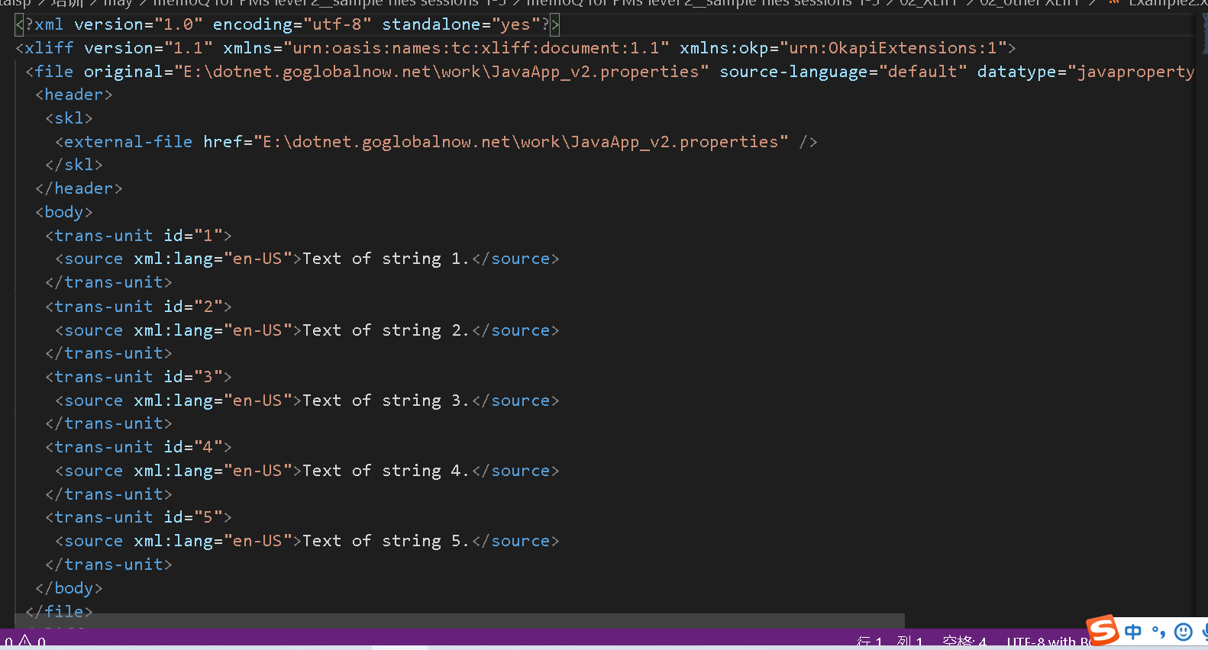
图22-XLIFF文档
XLIFF文件是为了在工具(TM工具、内容管理工具、创作工具)之间传输双语数据而创建的,现在也被XML开发人员用来准备翻译数据。
更多关于XLIFF文档,我以后会分享,不基于一时。
解析器的作用
那,解析器有什么作用呢?
- 保护源文档格式,如:标题、标记、表格、文本等。——这样你在翻译的过程中,只需要在翻译编辑器区域编辑即可,不需要考虑到标题、标记、表格、文本等格式。

图23-保护源文档格式
- 保护源代码,如:xml文档、json文档、html文档等。——这样你仍然只需要在翻译编辑器区域编辑即可,不需要考虑到源代码,也不会编辑源代码。
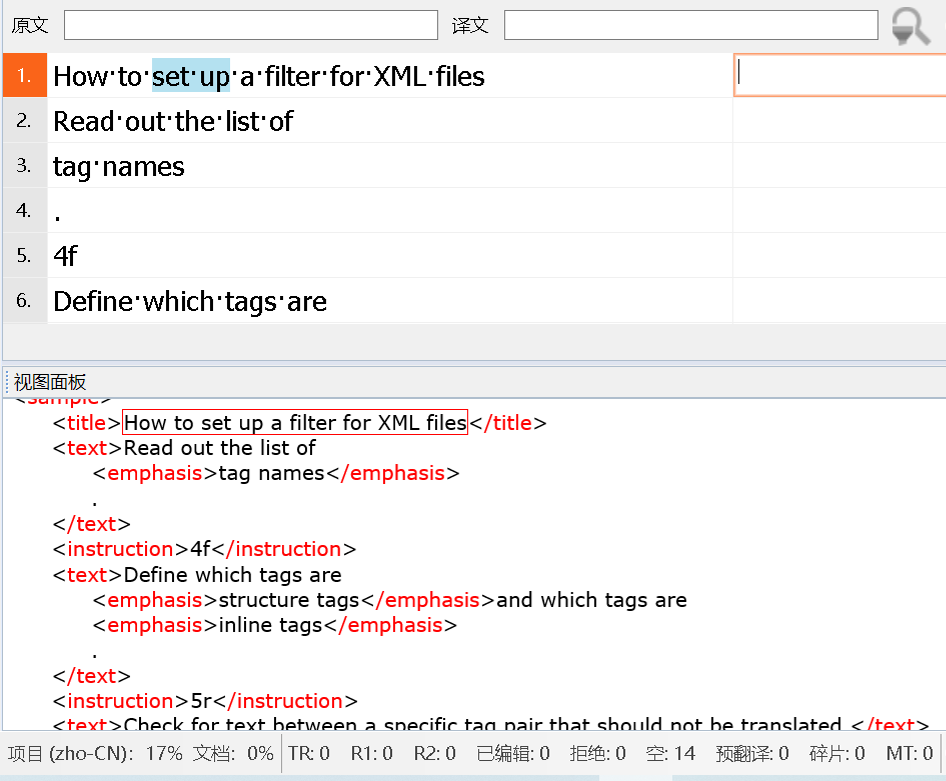
图24-保护源代码
如果你正在选一款CAT,一定要考虑是否能解析你现有、及将来的源文档!
2.1.5 语料对齐
语料对齐是什么?
依据现有的翻译资源建立记忆库的过程称为语料对齐。
其实就是我们玩的连连看:把原文句段和译文句段连连看。
——如果你有一个源语言文档和对应的目标语言文档,你就可以连连看,将这两个文档连起来,进行自动对齐或者手动连连看/对齐文件中的句段,如图25所示。
在memoQ中,语料对齐功能是放在LiveDos中的,你可以查看我之前写的memoQ中的语料库
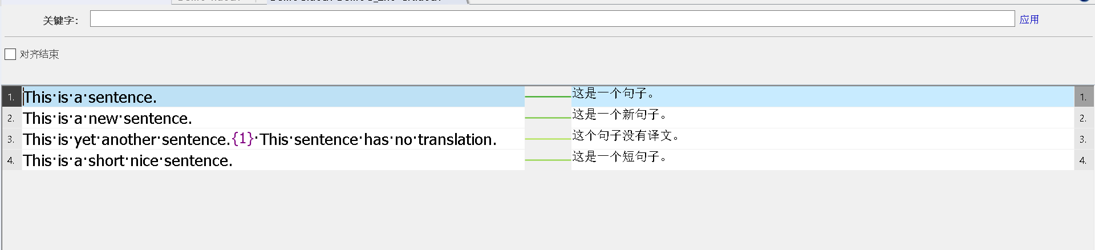
图25-语料对齐
使用语料对齐也可以加快翻译速度。如图26所示,在翻译时,语料库中的匹配内容也给你提供翻译建议,你甚至可以使用匹配的译文来进行预翻译,就像记忆库一样,提高翻译效率。
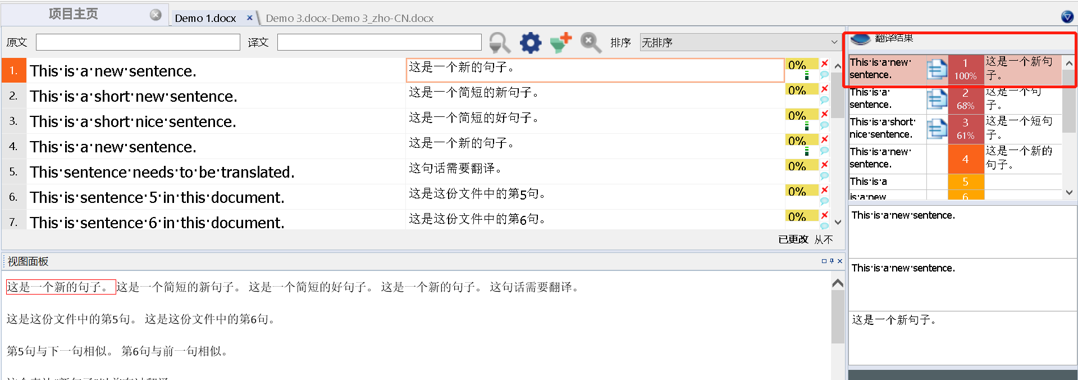
图26-语料对齐结果
当然,以上都是CAT的基本技术,而截图我都是借助memoQ截的。
2.2 CAT如何帮助提高翻译质量
在提高翻译翻译质量方面,CAT具有:
- 2.2.1 术语库技术;
- 2.2.2 质量保证(QA);
- 2.2.3 实时预览;
- 格式与标签处理等译中的编辑操作;
2.2.1 术语库技术
关于术语管理的流程,详见高质量翻译的秘诀:掌握术语管理的三个阶段
什么是术语库呢?
术语库(term base,简称TB)指的是包含与特定主题相关的某个单词或特定表达的数据库。
——其实,你可以把它理解为专业名词、专业术语的库。
术语库中的术语往往是双语的,甚至是多语的。
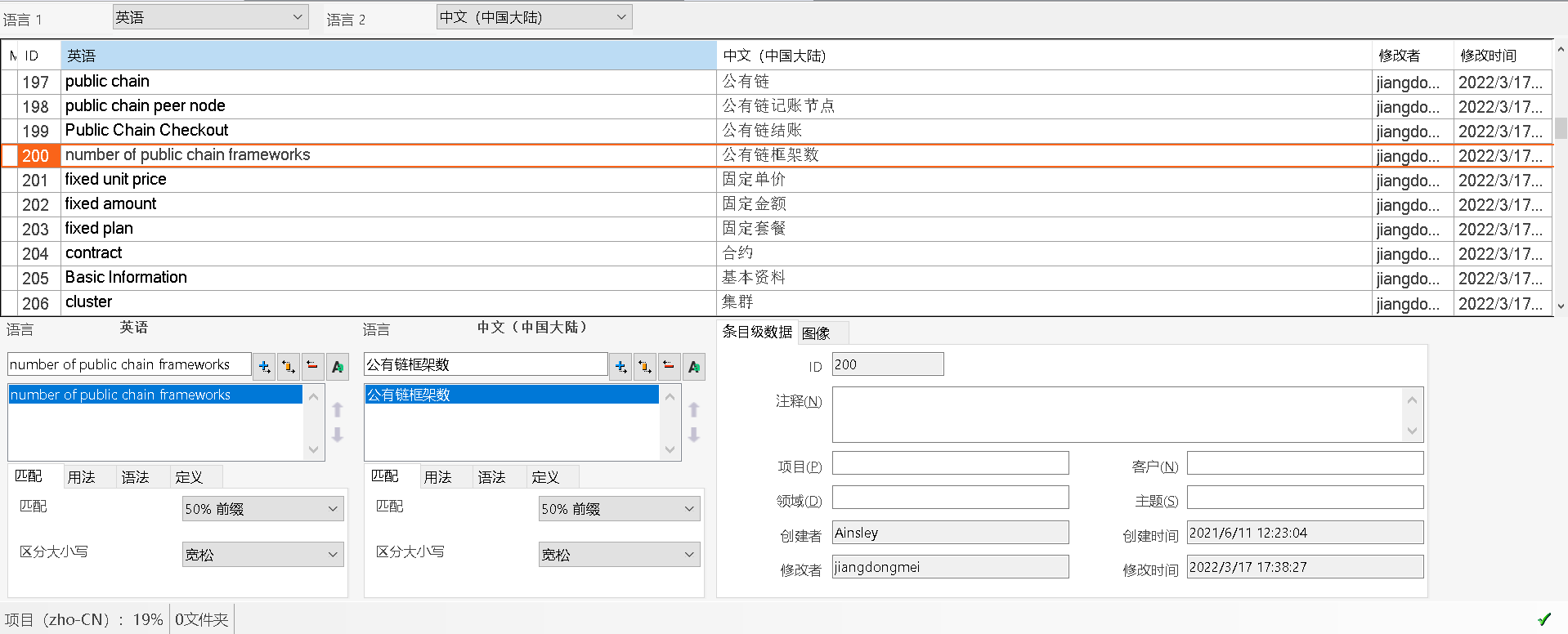
图27-术语库
那它是如何工作的呢?又如何提高翻译质量呢?
术语库是如何工作的?
- 术语库在CAT工具后台工作;
- 你可以在译前将现有的术语表/词汇表导入至术语库,也可以在翻译的过程中,添加/更新术语,同时,也可以将多种双语术语表合并为多语种术语表,并标记禁用术语。
- 系统会自动会根据TB提供这个术语词汇的专业译法。
使用术语库有什么好处?
- 保证术语一致:如图28所示,准确的术语库能够保持核心信息的一致性。如果企业/组织内有多人协作翻译,或多项目协作,一致性是必不可少的!
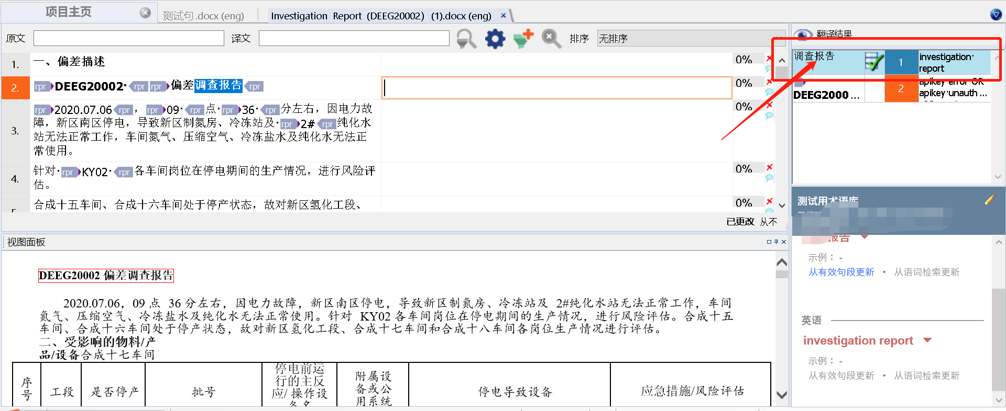
图28-保证术语一致
- 提高翻译质量:如图29所示,通过管理术语和定义禁用术语,你可以确保:不需要的单词或表达不会为翻译人员所使用 。
29-提高翻译质量
- 提高检索效率:如果你之前花大量时间查询术语,那么你只需要查一次!如果团队中已经有一个人确认了术语,那么其他人不需要重复查询啦!是不是可以提高检索效率呀~
术语库的交换格式
术语的交换格式是*.tbx格式,Termbase eXchange format(Termbase交换格式),也是XML的一种。
如果你不知道XML格式是什么,你可以先放放,或者你也可以看我之前写的认识XML文档(一)什么是XML文档?
如图30所示,在这个文档中会标注术语库的语言,每个语言的术语是什么,包括其他信息,比如创建者、创建时间等。
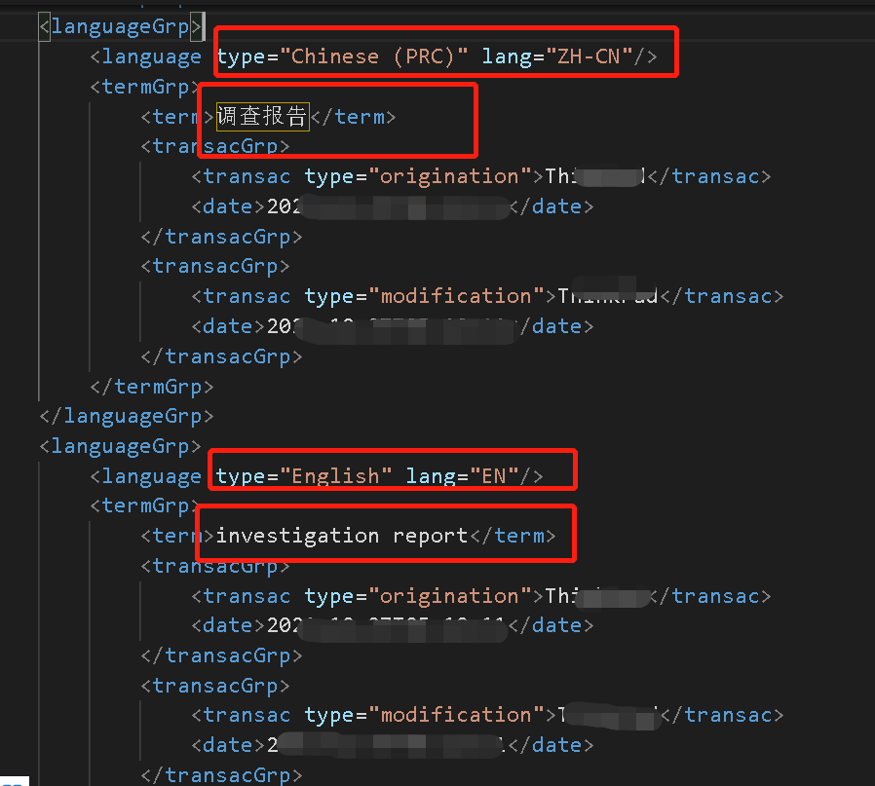
图30-tbx格式
通过TBX标准可以实现不同CAT之间术语库的互换。
当然,术语库还有很多其他的细节,我以后会慢慢分享,今天关于术语库,你只需要知道:
术语库是CAT的基本技术,帮助提高翻译质量。就好!
2.2.2 质量保证(QA)
关于质量控制的方法,详见避免翻译陷阱:如何识别和消除低级错误,确保翻译忠实、精确、通顺。
既然要提高翻译质量,那么,CAT一定能检查翻译质量,对不对。
——没错,这个可以检查质量的工具,就是QA(Quality Assurance,质量保证)工具!
我之前也写过和质量保证相关的内容,详见:memoQ中的质量保证
什么是质量保证呢?
翻译质量保证是一个全面的工具,它会基于定义好QA规则,进行检查。
比如,图31展示了memoQ部分默认的QA规则。
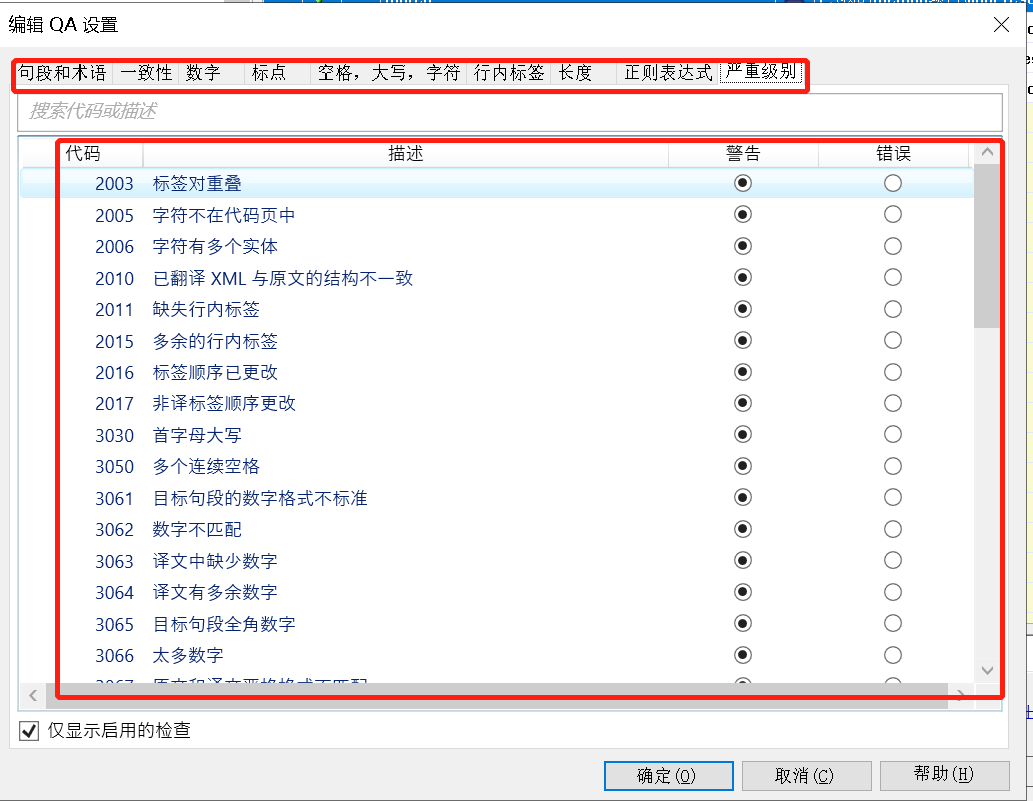
图31-memoQ部分默认的QA规则
如图21所示,在翻译结束后,通过运行QA,如果译文触发了QA的问题,CAT会提醒你这些问题,包括:缺少行内标签、存在多余的空格、缺少数字、术语不一致等。
这样你就知道:”哦,我这里犯了这样的错误,我需要改。”;当然,有时候,你也可以根据自己的情况判断:”哦,原来这里可能存在这样的错误,我觉得是个伪错误,OK,我忽略就好了~”。
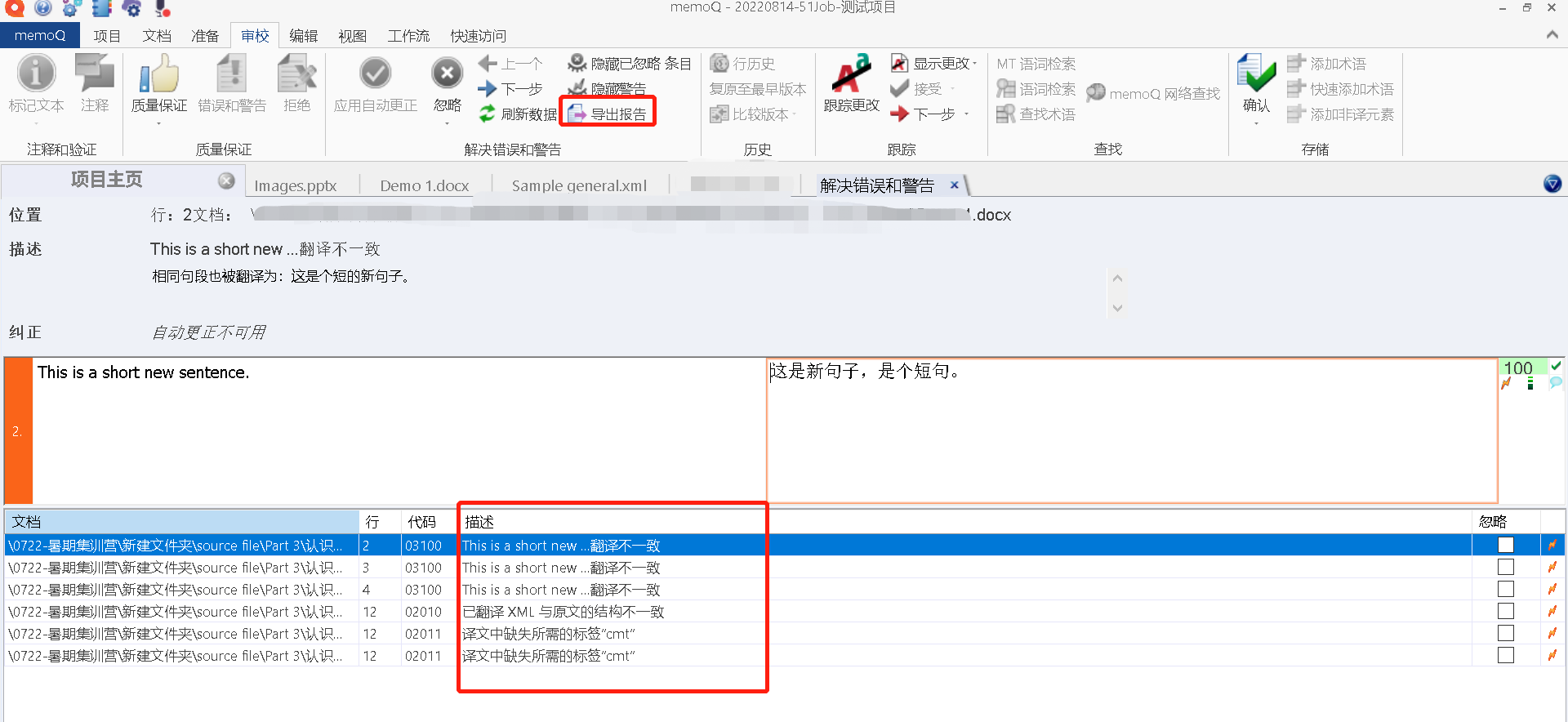
图32-运行QA
当然,memoQ的强大在于,memoQ的QA不仅译后可以统计,它还实时提醒。
如图33当你在memoQ中进行翻译时,memoQ实时自动检测译文问题。
比如源句段和目标句段之间的标点符号不一致、译文中有多余或缺失的数字、译文中有缺失或多余的行内标签、标签顺序不一致、或缺失术语等,也可以是:首字母没有大写、或目标句段末有多余空格等等。

图33-实时质量保证
2.2.3 实时预览
实时预览即所见即所得,指在翻译的过程中实时预览最终的译文。
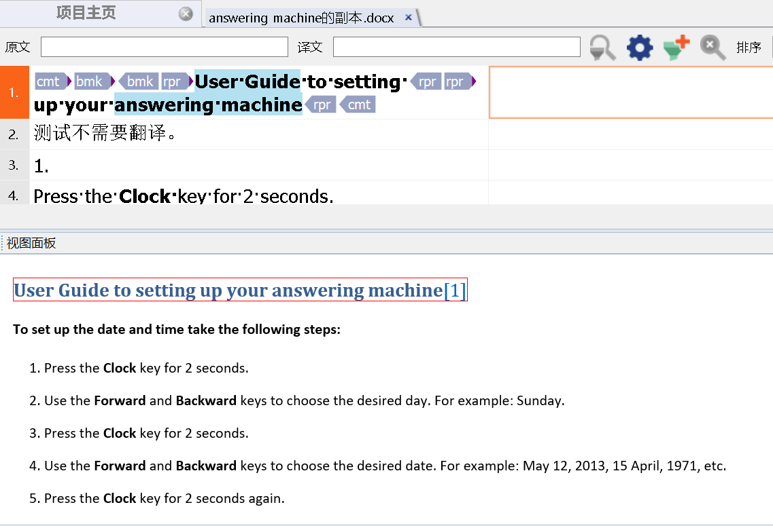
图34-实时预览
当然,memoQ不仅支持内部预览,还支持外部预览。
- 比如翻译indesign等文档时,需要预览外部pdf文档,就可以使用外置的pdf预览工具,详见:所见即所得:memoQ独立预览先人一步
- 再比如,翻译srt字幕文件时,需要预览最终的视频文件,就可以使用外置的视频预览工具。我之前和我老师一起举办过一期关于字幕翻译质量控制的webinar,你可以去看一下~
当然,我想前面写的可能不全面,我也会慢慢补充。
2.3 CAT如何帮助降低翻译成本
CAT可以通过字数统计和加权字数统计,来降低翻译成本。
关于字数统计的方法,详见memoQ中如何统计翻译字数?。
详细的字数统计结果包括:
- 多少重复的句段?
- 多少已锁定的句段?
- 多少已预翻译的句段?
- 各个匹配区间之间分别有多少句段?
你译前和译后都可以进行字数统计~
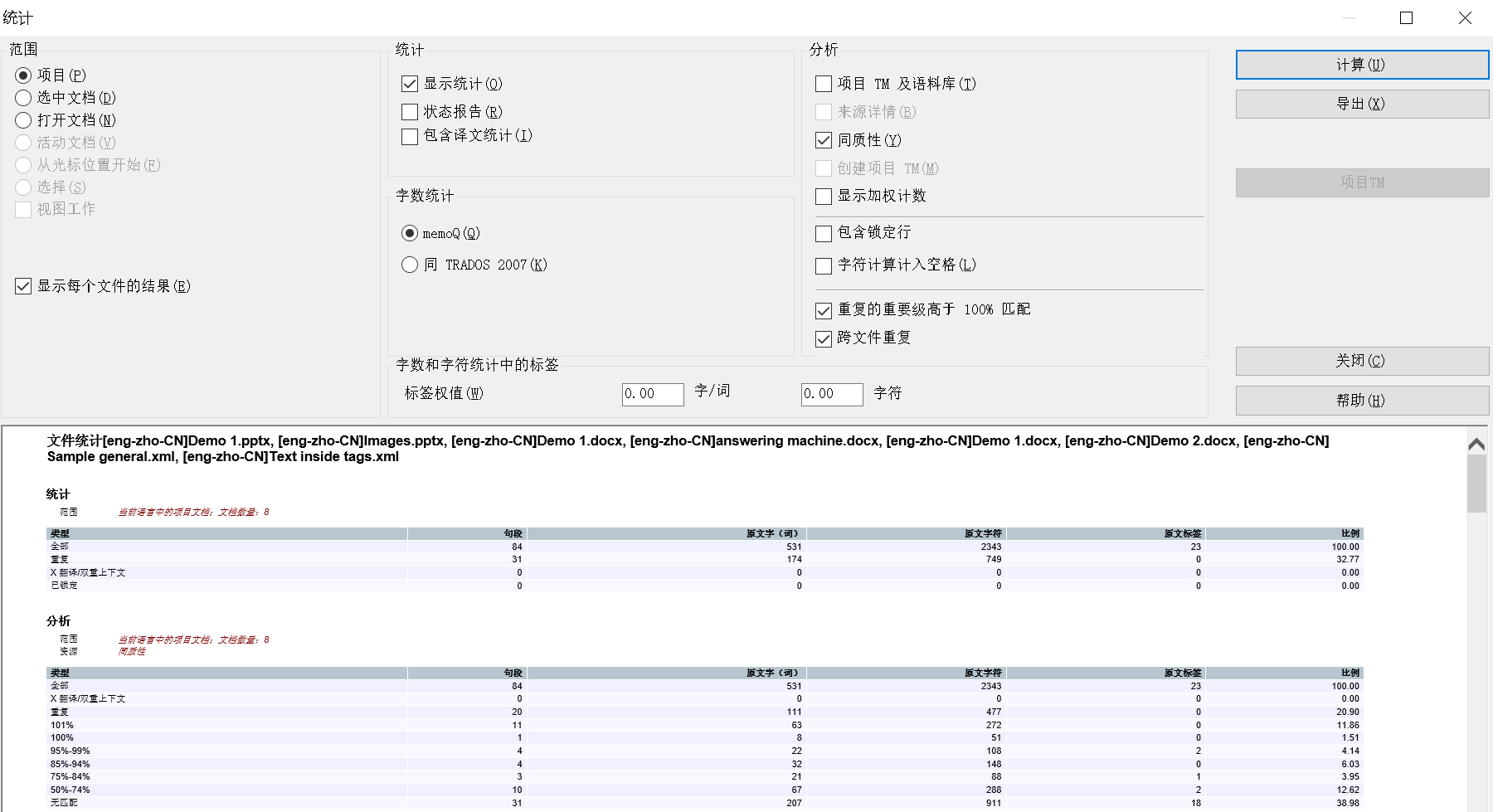
图35-字数统计
这样,加上加权统计的话,你就可以降低翻译成本。
比如如果你设置好加权值,如图36所示。(加权也就是打几折嘛~)
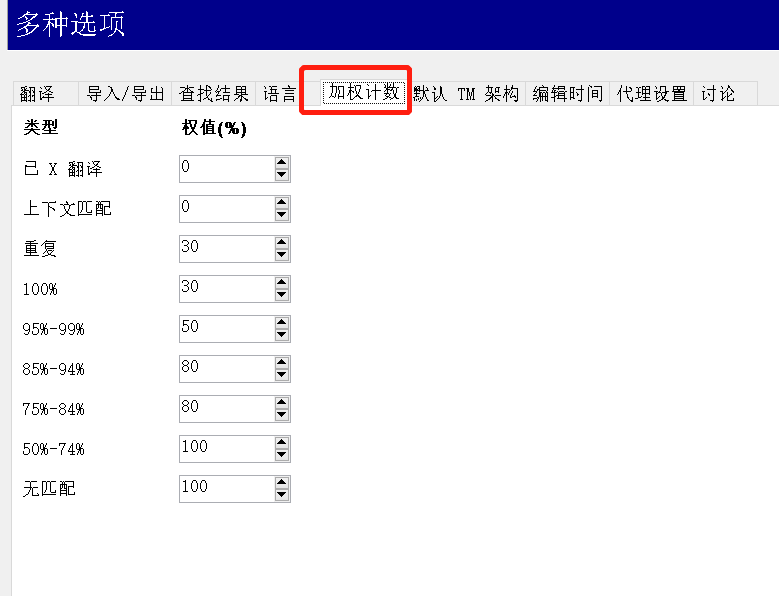
图36-加权统计
你在统计时,就可以进行加权统计,直接计算出打折后的字数啦,就像图37~!
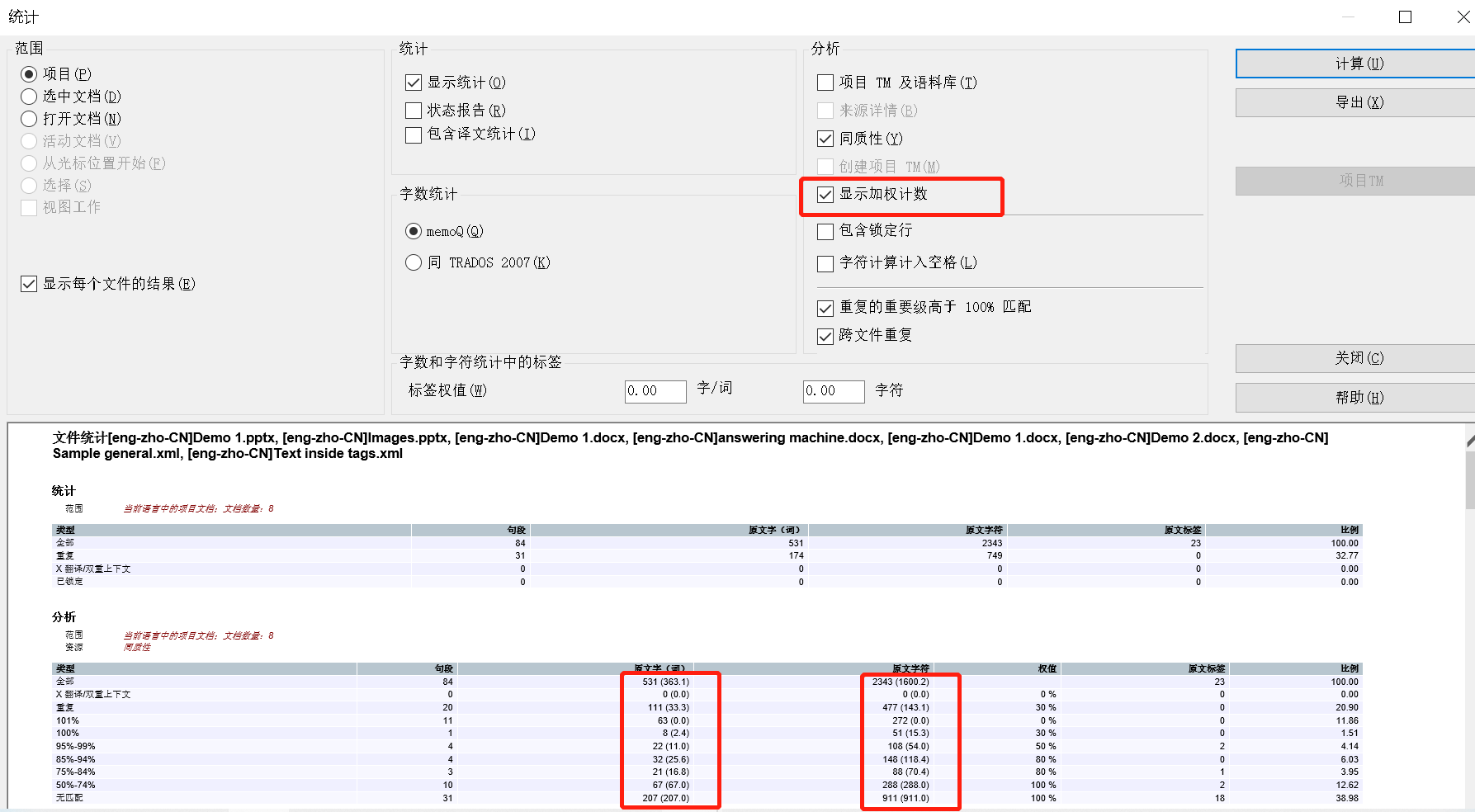
劳动人民赚钱不易啊呜~
3.总结
总结一下CAT的作用和基本技术:
在提高翻译翻译效率方面,CAT具有:
- 翻译记忆技术,基本格式是TMX格式,实现重复的内容不做二次翻译;
- 匹配率,包括完全匹配、模糊匹配和上下文匹配;
- 语词检索(一致性检索),轻松查找记忆库中某个词;
- 解析器,简化翻译格式,将所有源文档解析为XLIFF格式;
- 语料对齐,,复用已有语料。
在提高翻译翻译质量方面,CAT具有:
- 术语库技术,基本格式是TBX格式,实现术语一致;
- 质量保证(QA),检查低级错误。
- 实时预览,实现所见即所得。
在降低翻译成本方面,CAT可以进行:
- 字数统计,得出详细统计报告,让钱花的值,赚的明确。
- 加权字数统计,进行字数打折~
当然,以上都是基本技术。
memoQ也是通过这些基本技术,帮大家的。当然,远远不止这些~
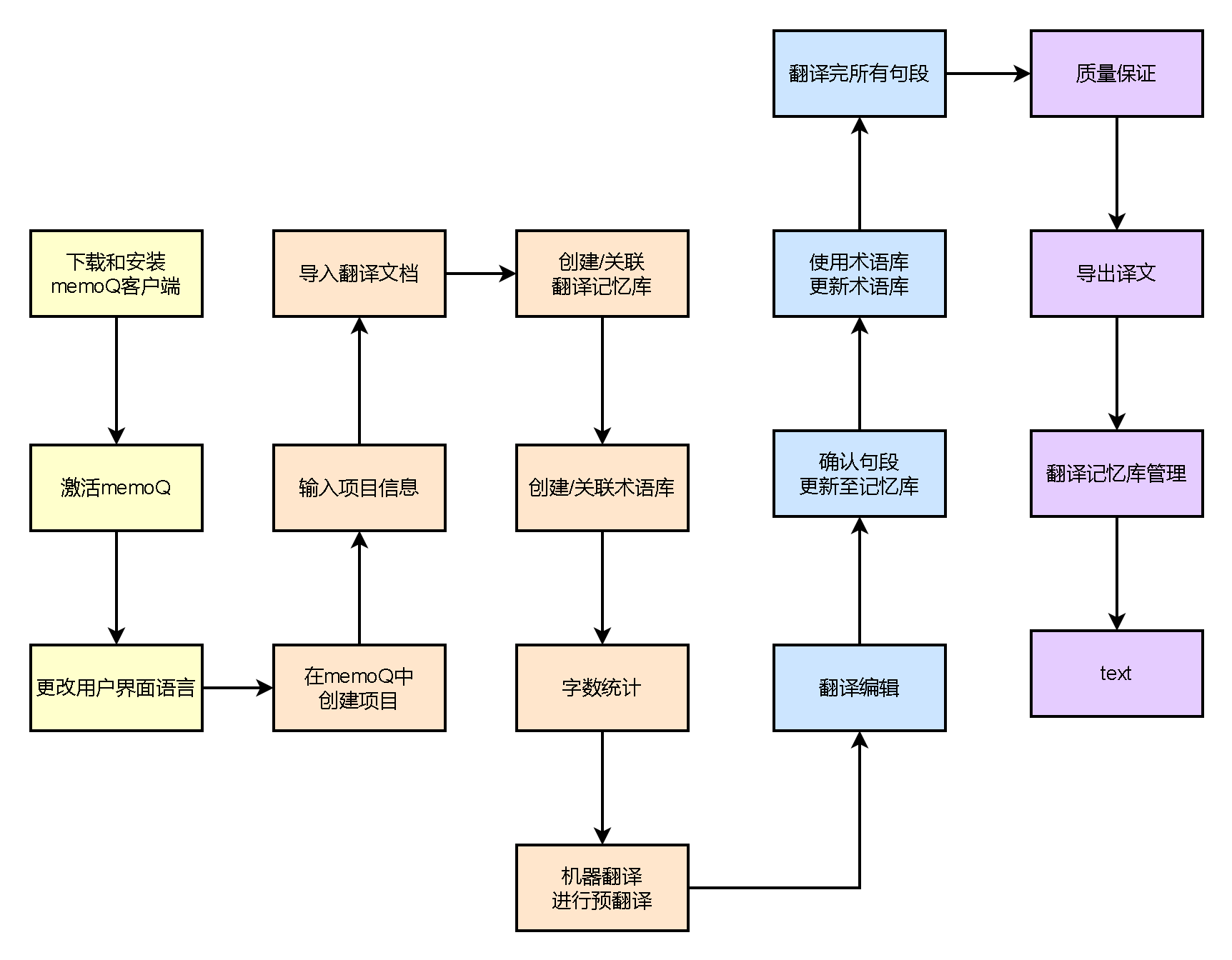
这些,借助我今天说的内容,结合我画的这张流程图,你应该可以理解一点点我为什么基于CAT的基本流程是这样啦
你也可以自己尝试一下
本文作者:姜冬梅
© Copyright 2023. 大辞科技 沪ICP备17050550号  沪公网安备 31011402006110号
沪公网安备 31011402006110号




