当我们涉及到XML文档翻译和本地化时,了解如何处理这一特殊格式的文件至关重要。在这篇文章中,我们将深入探讨XML文档的翻译和本地化,旨在为语言专家和本地化专家提供一些思路和方法。无论您是新手还是经验丰富的从业者,这篇文章都将为您提供有价值的见解,使您能够有效地处理XML文件,并确保最终的本地化工作高效完成。让我们一起开始这个XML之旅吧。
1. 本地化为什么要涉及 XML 格式
从事以翻译为主的语言专家,其实每天都在和XML文档打交道。比如,我们用的 word 的.docx文档,其实就是基于Office Open XML 标准的压缩文件格式,本质上就是一个 XML 文档。
我们来看一个案例,这里有一个docx的文档:(用Office word 打开)
现在,我们对这个文档做如下操作:
- 将文档的后缀名由docx改为zip格式,变成一个压缩包;
- 把这个压缩包解压缩,打开解压后的文件夹,然后打开文件夹内的 word 的文件;
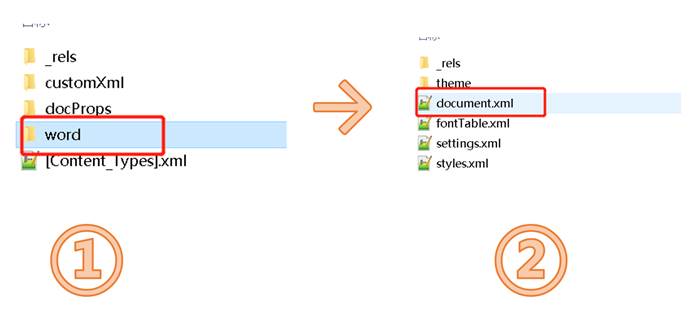
然后我们打开这个document. XML的文档,这就是原来的docx文档底层 XML 文档。
在这里我用vscode打开的,您也可以用任何一款文本编辑器打开,比如电脑自带的记事本,或者常用的Notepad++,sublime之类的都可以。
除此之外呢,我们现在用的CAT工具,翻译记忆库是.tmx格式,其实.tmx格式也是 XML 文档。
包括大家都熟悉的xliff格式,也是XML文档。
所以我们就来看看什么是 XML文档。
2. XML 的定义及其组成
百度百科是这样定义的:
XML(全称 Extensible Markup Language)可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。
如果您刚开始从事本地化行业,可能会感到疑惑,
什么是语言?
什么是标记语言?
什么是标准通用标记语言?
什么又是可扩展标记语言?
那么下面的内容就能帮助您回答这些问题。
2.1 语言
语言,这里指的是计算机的语言。就像人之间交流用的是人类语言,什么中文、日语、英语等等不同的语言,当然也有手语、肢体语言等等,有了语言人与人之间才能交流
可是,计算机并不能理解人类语言。所以我们需要使用二进制这种计算机能读懂的语言去翻译人类的语言,包含但不限于HTML、GML、 XML 、C++、VC、VB、Delphi、Java、PHP、Python等等
通过计算机语言,就能实现人与计算机进行交流和对话。
2.2 标记语言
标记语言,Markup Language,是一种将文本以及文本相关的其他信息结合起来,展现出关于文档结构和数据处理细节的电脑文字编码。(摘自百度百科)
如果看不懂标记的定义的话,我拿人类语言的标记举例子。
小时候一定遇到过这张图片:红叉标记——老师给我打的标记,标记我这里好像做错了;

同理,我们也有过:
- 荧光笔标记重点——我自己打的标记,标记这里有重点;
- 甚至用标点符号标记句子的含义,比如句号标记句子结束,问号标记疑问句,等等。
我们再回到标记语言这个话题,上述是人的标记。而这里的标记语言**=标记计算机语言**。
那,什么是标记计算机语言?
您可以理解为,给计算机文本用信息符号做个标记。
在标记语言中,一定要说明:
- 标记的规则是什么,或者标签叫什么名字?
- 要标记的文本内容,也就是给什么做标记?
- 标记的结构是什么,也就是各个标签之间的关系是什么
举个例子,我写了这样一个标记。表示:
- 这是一个什么?——<note>!这是一个笔记或者备注;
- 这个备注给谁的?——<to>Everyone</to>!给每个人的;
- 这个备注是谁发的?——<from>May</from>!原来是 May 发给大家的;
- 这个备注的主题是什么?——<heading>Say hello</heading>!原来是 May 跟大家打招呼的;
- 这个备注的正文是什么?——<body>This is May.</body>!原来是 May 跟大家打招呼,介绍了下自己。

上下结构和内容都很清楚。
您可能会有这样一个疑问:“那,我想怎么写就怎么写吗?”
比如,我在文本前输入井号加一个空格,告诉计算机“只要是见到井号**+空格,就表示标题**。
是的,在标记语言中,您想标记什么就标记什么,您想怎么定义结构就怎么定义结构,您想怎么写就怎么写,只要您和您的计算机商量好了就行。
但是这会有一个问题,就是:换一台计算机,就不知道您所规定的定义是什么
所以,为了解决“让大家都明白”的问题,在1986年国际标准化组织出版发布了一个信息管理方面的国际标准(ISO 8879:1986信息处理),也就是标准通用标记语言。
2.3 标准通用标记语言
标准通用标记语言,Standard Generalized Markup language,中文简称“通标语言”,英文简称SGML,就是计算机的文本结构和描述内容的国际标准语言。
既然是国际标准规范,那遵循什么规范呢?
一份“通用标言”文档可能有三部分组成:
- “**通用标言”声明**:定义字符集分隔符集和关键字(以下在本文里头简称“声明”)。
- 文档类型序言:定义一般实体和元素类型
包含一个“!文档类型(外语全称加缩写:!DOCTYPE)声明”与各种“标记声明”,它们一起组成了一个文档类型定义(外语首字母缩略词:DTD)
- 实例:包含一个顶级元素和实例的内容
不同的文档有不同的文档样式,比如我们的HTML文档有HTML文档的国标样式,您要是写HTML文档,遵循这个标准就行。
比如:
- 在HTML中我们用: <p>这是一句话</p>
- 表示:文本 这是一句话 是段落。
——这样就给文本赋予了一个段落结构。
如果您还是看不懂,您可以随意打开您的一个页面,查看这个页面的源代码。
对于这样一个文本而言,我们能获得的好处是什么?——您可以很清楚地看到这文本的布局。如果把源代码关掉,就可以看到图片、排版
当然问题是——HTML**的复用率很低**。您的文本格式、图片大小、宽度、固定值都固定了,很难复用。
解决的办法就是把它变成可扩展标记语言,也就是 XML !
2.4 可扩展标记语言( XML )
XML 的全称是 Extensible Markup Language 就是 XML 的全称,我猜是因为发音就是/ex/=X,所以才缩写为 XML ,而不是 EML。我也查了一些资料,没找到什么答案,您们要是感兴趣可以自己研究研究~分享给我呀~
如果我们了解了标记语言,那“可扩展”应该比较容易理解,就是:您可以由一个 XML 扩展到新的语言,比如: WAP 和 WML 语言。
您只需要记住 XML 的几个特征:
- 既然 XML 也是一种语言,所以 XML 也是一种基于文本的结构化格式;
- 既然 XML 也是标记语言,那么您当然可以自定义标签名,或者我们叫“元素名”。比如,我们可以自定义标签名为<seg>,<source>等。
既然标签名是自定义的,那么在用CAT工具翻译的时候就需要明确标签的名称;
当然,有的名称来源于 XML 文件本身,但是有些来源于用于创建 XML 文件的定义文件,如 DTD(document type definition文档类型定义)文件, XSD( XML SCHEMA Definition)文件(定义 XML 文档的合法构建模块)。
- XML 是用来传输和存储数据的,不是用来显示数据的,所以 XML 文档不包含格式或者布局信息,没有HTML布局明确;
既然 XML 不包含格式或者布局信息,那译员如果要预览布局怎么办呢?就需要借助XSLT(transformation style sheet) 文档, XML 文档转换为XHTML文档或其他 XML 。
既然 XML 也是SGML,那么 XML 当然要遵循 SGML 的规范。
我们一起来看一个 XML 文档。
- 第一行有 XML 声明,定义了 XML 当前的版本(1.0)和编码(utf-8);
<? XML version=”1.0″? encoding=”utf-8″>
- 第二行描述文档的根元素。
当然最后一行是根元素的关闭标签。
<sample>
- 接下来有描述根元素的子元素
<document> <topic> … </topic> </documen>
- 当然,也有描述<topic>的子元素
这样,就构成了一个完整的 XML 文档
3. XML 的组成
我们拿上文提到的这个 XML ,给大家举例。
这是怎么组成的呢?
3.1 XML 的声明语句
XML 声明是 XML 文档的第一句,描述了版本号和编码,其格式如下:
<? XML version=”1.0″ encoding=”utf-8″?>
您可以理解为这是 XML 的自我介绍:“Hi**,我是一个 XML 文档的1.0**版本***,是* utf-8 编码格式*。*”
3.2 XML 的元素、标签和属性
3.2.1 XML 的元素
我们把代码片段中,从最左侧的尖括号到最右侧的尖括号之间的所有内容称为“元素”,英文名是Element,是 XML 文档中很重要的组成部分。
XML 元素包括标签、文本、属性、注释等等,比如:<text>Introduction</text>,这就是一个元素。
一个 XML 文档可能包含很多的元素。
我们先来看看标签。
3.2.2 XML 的标签
关于标签,您需要了解:
- 标签是什么?标签,或者标记,就是您看到的尖括号括起来的部分,一个标签:一个左尖括号**+元素名+一个右尖括号**。比如:<text>和</text>,都是标签,标签名是text。标签名一般不翻译。
- 标签有开始标签和结束标签之分,在这个例子中,<text>是开始标签,</text>是结束标签。 具有同一个标签名的**“开始标签+结束标签”是一对标签对**,比如:<text></text>是一对。
标签对之间的文本,我们称为元素内容。
3.2.3 XML 的文本
关于文本,您需要了解:
- 文本,或元素内容,一般需要翻译的文本。 比如,在这个例子中:Introduction才是要翻译的文本。
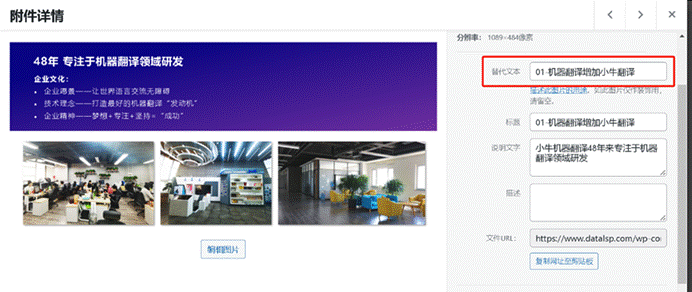
- 但是有时元素内容也可以不翻译,比如图中的“5-2b”就可以不翻译。
- 当然,有时候文本之间也有行内标签对的存在,比如图中的<emphasis></emphasis>标签对。
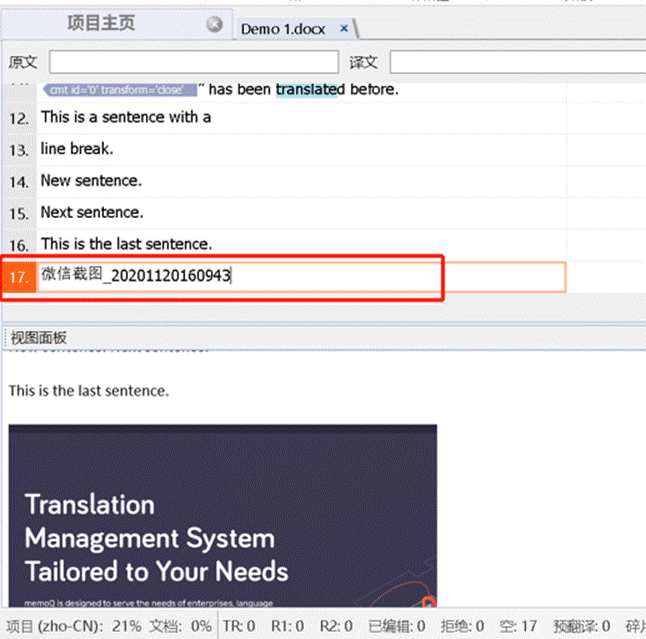
- 有时候因为元素内容为空,比如:<text></text>,有时把这样的标签也可写成<text/>(斜杠在元素名称后面),这样的元素我们称为空标签,或者独立标记。
您可能会问,空标签还需要翻译吗?——也要分析,我们往下看。
但是文本的书写并非随心所欲,有时候得换个写法才能呈现您想写的内容,也就是得改为实体。
3.2.4 XML 的实体
关于实体,您只需要了解:
XML 规范规定,如果下列字符出现在要显示的文本中**(在我们的例子中是要翻译的),它们应该写成实体。**
| 如果您想要 | 您需要改为: |
|---|---|
| < (小于号) | < |
| > (大于号) | > |
| &(和) | & |
| ‘ (英文单引号) | ‘ |
| ” (英文双引号) | “ |
如果您看不懂,我举个例子。
如果您想要这个文本:
您的 XML 应该怎么写呢? 
以上例子所示,大于号不是>,而是 >,单引号不是’,而是 ‘。这就是实体。
由此可知,如果您在 XML 中遇到了实体,是不是要考虑在翻译的过程中把这些实体设置为标签呢?
如何设置标签,参见:正则表达式篇(六):用正则将文本标记为标签-大辞科技 (datalsp.com)
3.2.5 XML 的属性
关于属性,您需要了解:
- 属性是什么?有时我们会给标签加一些详细的描述,这些描述就是属性,您可以理解为标签的注释。
- 如果是成对标签,属性一般放在开始标签的标签名后面;当然如果是空标签的话,属性会跟在标签名后面。
- 属性由 属性名 + =**(等号)+** 英文单引号**/双引号标注属性值**组成。
比如这样一个标签:<button value=”Cancel” />,这个标签的意思是:
- 这是一个空标签,标签名是button
- 有一个value的属性,属性值是cancel。
- 在遇到有属性值的标签时,要分析属性值是否要翻译。
比如,我们看一个属性值需要翻译的标签:
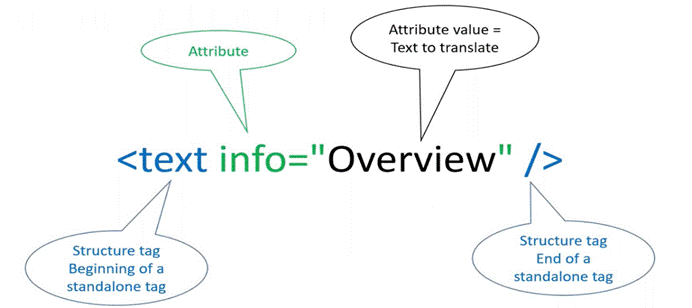
- 标签名是 text
- 有一个 info 属性
- info 属性值是 overview,需要翻译。
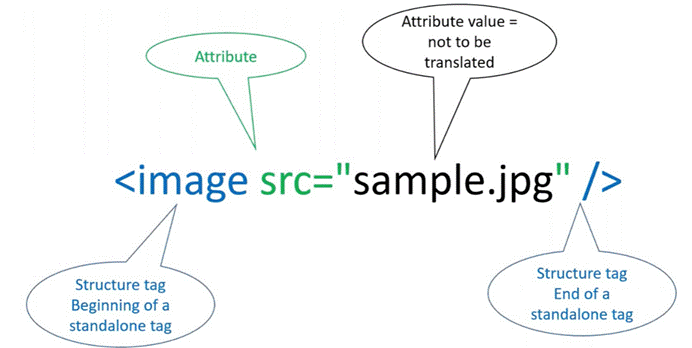
以及一个属性值不需要翻译的标签:
- 标签名是 image
- 有一个 src 属性
- src 属性值是 sample.jpg,不需要翻译,保留原文
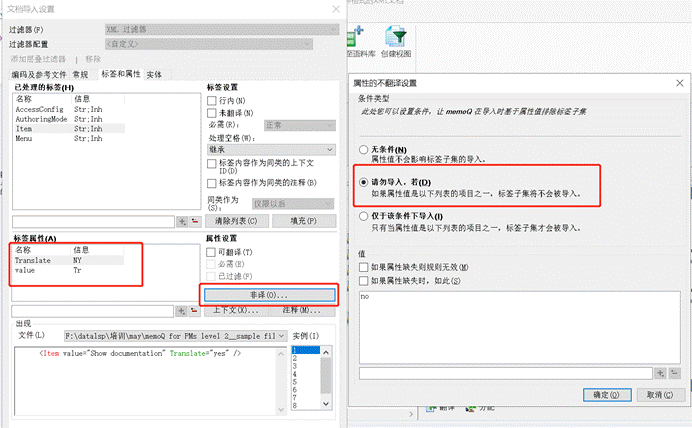
- 有时候属性可能代表某些条件,可以应用于标签或行内标签之间的文本。比如下图中,
- 第一行,只有遇到 translate 标签是 yes 的时候,文本才需要翻译;
- 第二行,只有遇到 translate 的属性值是 yes 的时候,另一个 value 的属性值才需要翻译。

3.3 小结
我们来做个小结。
- 什么是标签?什么是标签对?什么是独立标记?如,<text>…</text>
- 什么是属性?什么是属性值?属性如果表示条件怎么做?如,value=”OK”
- 什么是实体?如,"。
那,作为一名PM或者译员,了解 XML 的注意事项是什么?
- 标签名和属性名不能翻译。比如:<button value=”OK” />中,button 和 value不能动。
- 标签文本和属性值要译前分析:是否需要翻译?是否是条件?是否是注释?等。
- 每一个开始标签一定要有结束标签:<text>…</text>
- 独立标记格式必须正确:<image…/>。
- 实体不能翻译,所以为了防止实体出错,要提前译前处理成标签。
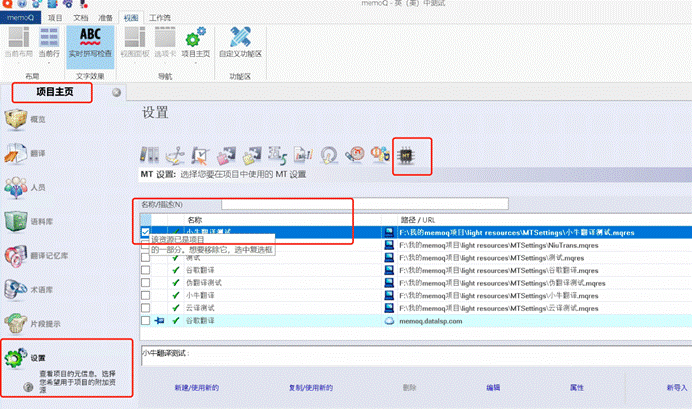
那,这样的 XML 文档如何用 memoQ 解析?
4. 常见的 XML 文档如何翻译?
在翻译一个文档时,最主要的选择和设置准确的过滤器, XML 文档也不例外。
memoQ中有默认的XML 过滤器,基本可以实现您对 XML 文档的需求。
不论是什么 XML 文档,都可以直接导入进memoQ,如果导入后发现导入的内容不对,那么我们再说~
那我们看看翻译 XML 文档有哪些需求,以及memoQ的过滤器如何解决。
4.1 memoQ 自动解析的 XML
正如我前两篇文章讲的,翻译单语言的 XML 文档一般就以下几个需求:
(1)标签名和属性名不能翻译。
memoQ的 XML 过滤器能帮我们自动识别标签名和属性名。
这样我只需要翻译标签之间的文本,可以忽略标签名,就保证了标签名和属性名称不会被译员随意翻译和修改。
(2)标签文本和属性值要译前分析,比如是否可译?是否是条件?是否是注释?等。
想知道这些,我们可以在这个 XML 过滤器中设置可译文本和条件,定义哪些标签对之间的文本要翻译?或者不翻译?哪些属性值要翻译或者不翻译?哪些属性值是注释?哪些属性值是条件?等等。
这样我们在翻译的时候,非译的内容就不会被影响到,而且我们就可以实时看到各种条件和属性了
当然,以上提到的具体细节,我拿几个案例文档来演示。
我已经在memoQ中创建了一个项目,语种是英文翻译至简体中文。
以下所有的 XML 文档都在这一个项目中导入。
4.2 翻译常见的 XML
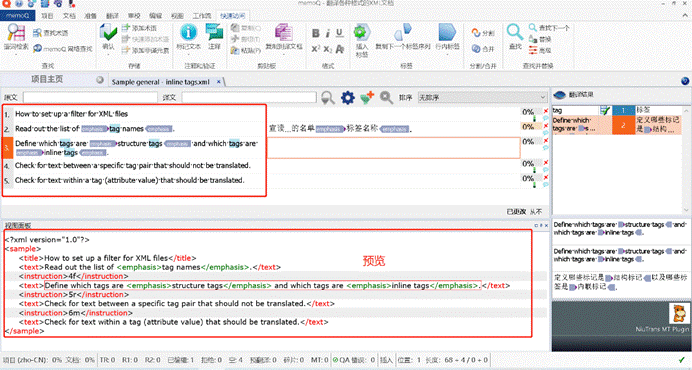
常规的 XML 一般只需要翻译标签对之间的文本。

我可以直接导入.导入后,
- 标签名会被自动过滤,
- 我只需要翻译我要翻译的文本就好了,
- 不需要考虑 XML 标签的问题。
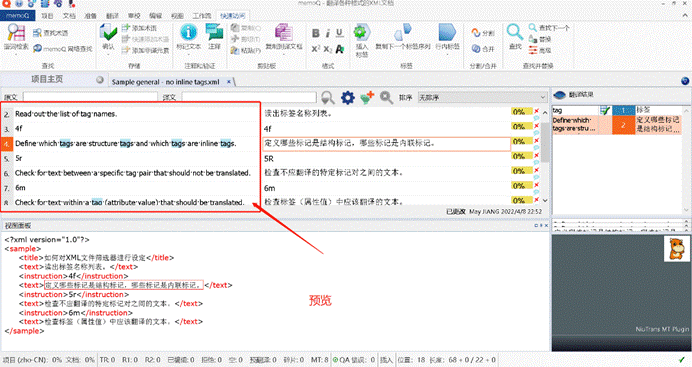
4.3 翻译有行内标签和非译标签的 XML 文档
还有一些文本,标签对之间是有行内标签的,

我可以把标签设置为行内标签。
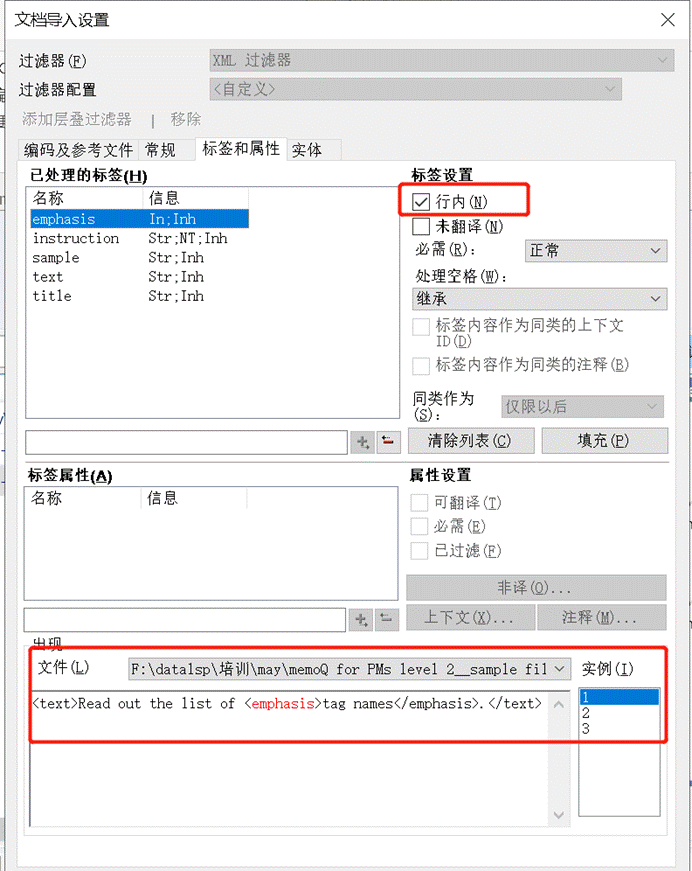
如果标签对之间的文本不需要翻译,
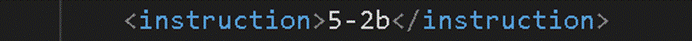
我也可以设置为非译。
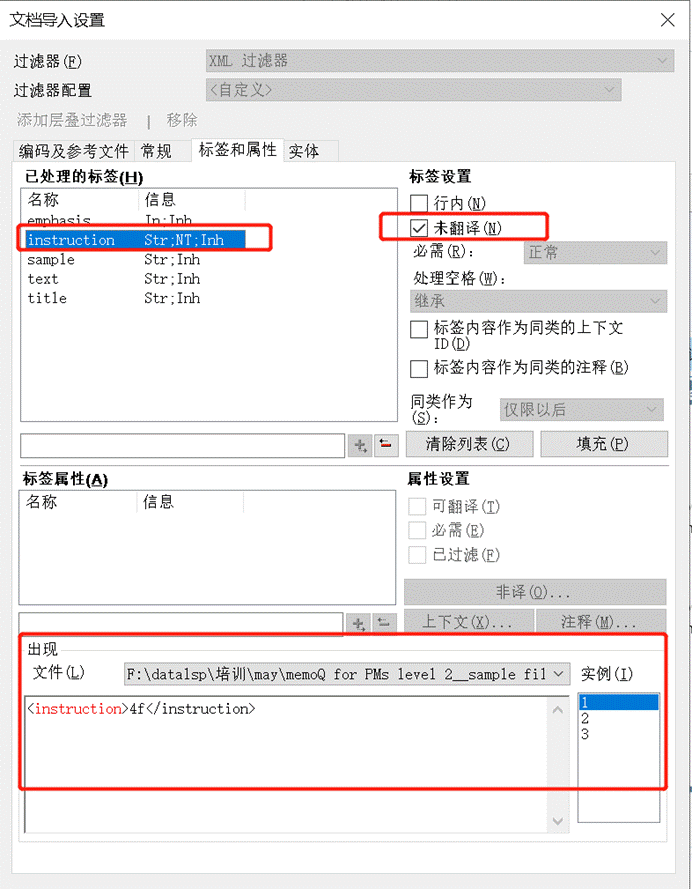
4.4 翻译有属性值的 XML 文档
前面讲个,XML XML 文档中也是有属性值的。
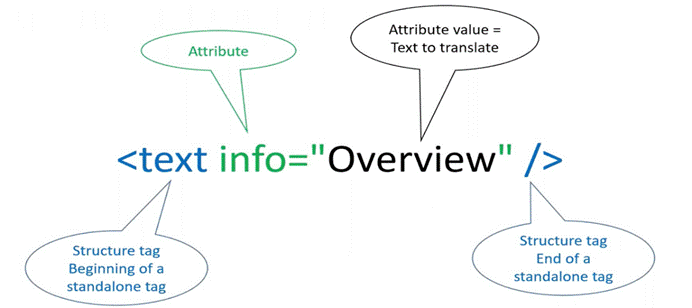
如果属性值需要翻译,我也可以把需要翻译的属性值设置为要翻译,或者非译。
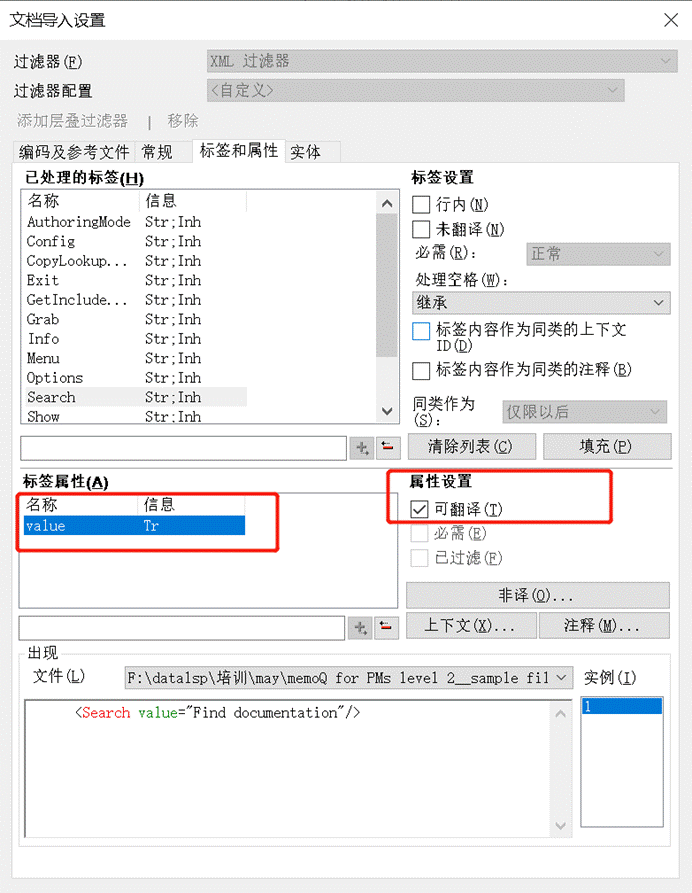
4.5 翻译属性值为条件的 XML 文档
有些属性值当中是包含条件的。比如下图中,我们希望:只有 translate 属性值是 yes 的时候,文本/另一个属性值才翻译。
我们就可以设置翻译**/非译条件**。
4.6 小结
回顾这一节的内容:
- 如何翻译常规的 XML 文档
- 如何翻译有行内标签和非译标签的 XML 文档
- 如何翻译有属性值的 XML 文档
- 如何翻译属性值包含条件的 XML 文档
当然,我们还有其它的 XML 文档,比如:
- 包含DTD或者XSD的 XML 文档;
- 有xslt的 XML 文档;
- 包含上下文ID的 XML 文档;
- 多语言的 XML 文档等。
5. 包含 HTML 实体的 XML 文档如何翻译?
我这里有一个文本:

里面有一堆看上去无序的内容,比如:< 和 >。——这些乱七八糟的东西其实是实体。
如果您看不懂这个文档,那么我再给您放另一个图:
这两个文档就是同一个文档,只是写法不同。
所以引出了一个问题,什么是实体?
5.1 什么是实体?
XML 规范规定,如果有些字符(详见下列表格)出现在要显示的文本中,它们应该写成实体。
| 如果您想要 | 您需要改为: |
|---|---|
| < (小于号) | < |
| > (大于号) | > |
| &(和) | & |
| ‘ (英文单引号) | ‘ |
| ” (英文双引号) | “ |
我们来看个例子。
假设您想实现的文本是:
 您的 XML 就应该这么写:
您的 XML 就应该这么写: 
在以上例子中
- 大于号没有写成 >,而是>
- 单引号也没有直接写为 ‘,而是’
这就是实体。
XML 的实体是对数据的引用,而不是直接使用该数据。
通过上述表格,我们也发现了,实体的标准写法是:
- 以一个与字符(**&)开始**,
- 以一个分号(**;)结束**。
那,遇到包含实体的文本,应该怎么翻译呢?
5.2 如何翻译包含实体的 XML 文档
我们回到这个文档:
如果把这个文档直接导入memoQ进行翻译,默认情况下,memoQ**默认的** XML 过滤器就可以自动识别这样的文本。
所以,如果这个文本直接导入memoQ,会是这样的:
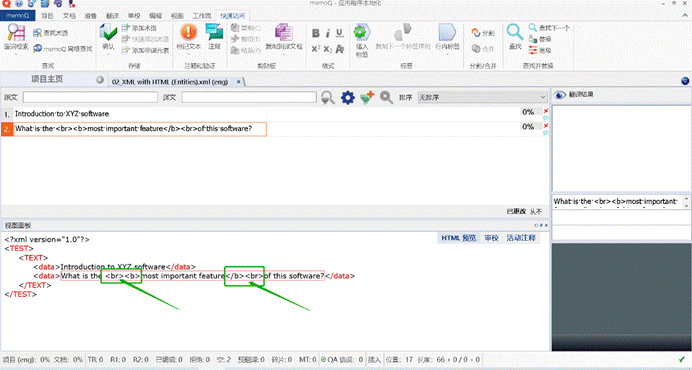
是的,我们发现了:
- memoQ自动把 < 转为了 <,
- 把 > 转为了>。
这时候我们也发现, memoQ自动转换为HTML的样式了:
- 是一个换行标签
- <b>是一个加粗样式
所以您可以理解为:这个文本是在 XML 基础上包含了**HTML样式**。
那我们可以用层叠过滤器。
关于层叠过滤器,您可以查看帮助文档:https://docs.memoq.com/current/en/Places/create-new-filter-cascading.html?Highlight=cascading%20filter
我们以后也会再讲
- 既然是 XML 文档,所以我们第一层过滤器还用XML 过滤器;
- 既然包含HTML样式,所以我们叠加一层HTML**过滤器。**
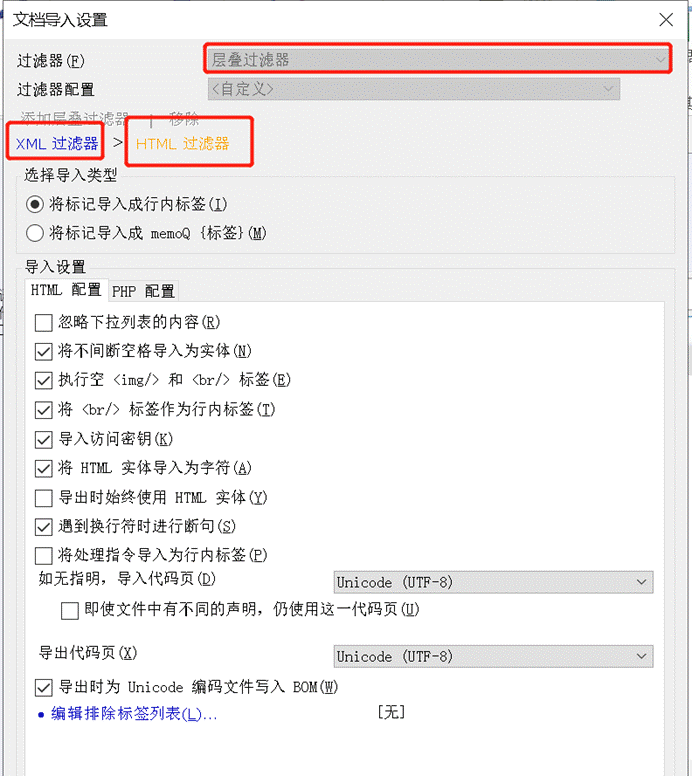
重新导入后,就可以解决了。
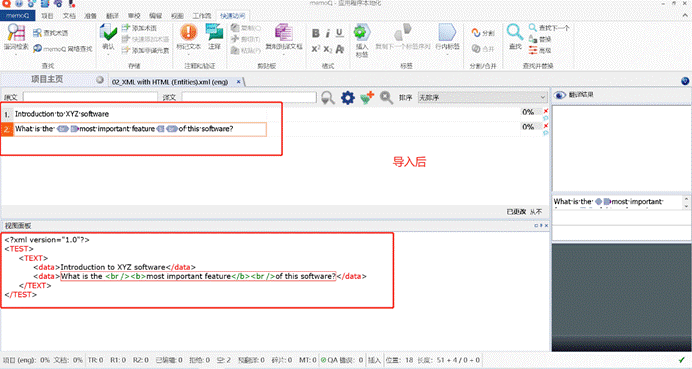
这样就不用担心出现字符串误译或者丢失的问题了
6. 包含 CDATA 样式的 XML 文档如何翻译**?**
包含**CDATA的** XML 也是应用程序本地化中常遇到的一种文档格式。
我们先来看它长什么样子:

我们发现它是符合 XML 标准的:
- 第一行说明语句:<? XML version=”1.0″ standalone=”no”?>
- 第二行和最后一行根元素:<doc>
- 中间有<para>是<doc>的子元素。
但是也有点不一样,就是多了一些<![CDATA[…]]的东西。
这就是 CDADA 文档。
那么它到底是个什么,又该如何翻译呢?
6.1 什么是 CDADA?
我们知道,计算机在读取编程文件的时候,是一行一行来读的。
我用前面的 XML 文档为例。
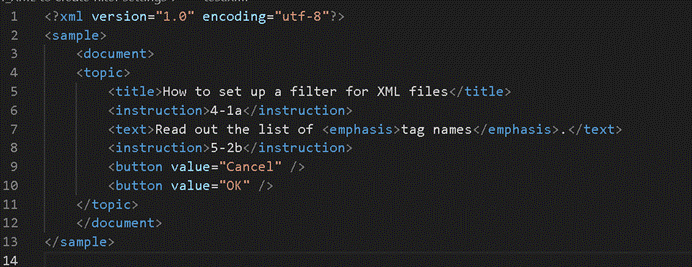
计算机就会先读取第一行:<? XML version…?>,
然后继续往下读<sample>,
可是如果遇到走不通的地方,计算机读不懂,就会提示报错
可是为什么会有报错呢?可能的原因有:
- 您的代码逻辑有问题。或者
- 这是个 XML 文档,您写的不是 XML 样式
第一个原因如字面意思,往往是因为自身代码的原因
第二个原因,该怎么解决呢?
- 改成它能懂得语言;——比如我们前面讲的改为实体,如果’读不懂,就改为’
- 直接跳过。——比如通过 CDATA 就是一种解决方法。
怎么解决呢?我们看看 CDATA 是什么。
CDATA 的全名是**character data。**
在 XML 文档中,文本均会被计算机读取和解析,但是被 CDATA 包起来的文本除外。
比如某些代码,包含像 < 、 > 、& 等字符,我们可以将其定义为 CDATA,这样计算机就不会读这部分内容,也就会减少出错了。
CDATA 部分由**<![CDATA[“** **开始,由** **”]]>结束**:
我们还是以本文开篇的 CDATA 文档为例,这次我们用 Chrome 打开看一下。

我们发现,由 CDATA 包起来的内容是没有读取的
但是这些内容总是需要去进行翻译的
那么遇到 CDATA 该怎么翻译呢?
6.2 如何翻译包含**CDATA** 的 XML ?
我们先看源文档:
如果要翻译出 CDATA 的部分,必须要知道 CDATA 包起来的部分是什么。
在这个例子中,我们发现,其实被 CDADA 包起来的内容是 HTML 样式,像<p>、<b>都是,当然也有实体,像&amul;、ö。

这就变得简单了,我们还是用层叠过滤器:
- 既然是 XML 文档,那第一层过滤器还是用 XML 过滤器;
- 既然 CDATA 部分是 HTML 样式,那第二层我们就用 HTML 过滤器。
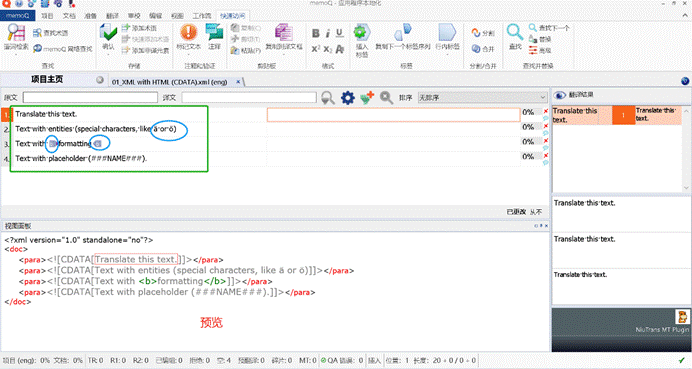
我们在最后一行发现了:####NAME####
- 继续加过滤器,加一层正则表达式标注器,标记为标签。
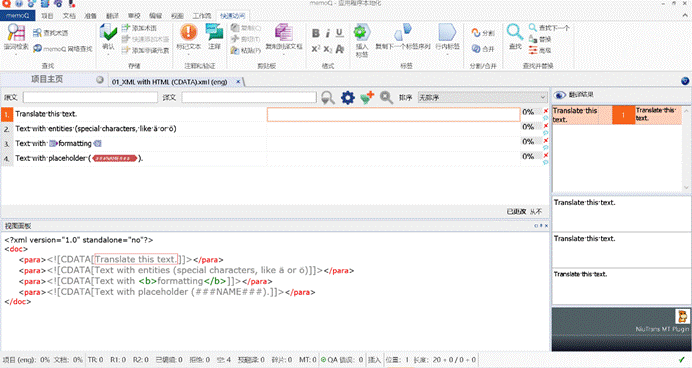
记得怎么用正则标注标签吗?不记得看这里回顾:正则篇(六):用正则将文本标记为标签
7. 多语言的 XML 文档
但是除此之外,我们也会遇到多语言的 XML 文档,尤其是游戏本地化和应用程序本地化中。
所以,今天带大家看看,多语言的 XML 文档长什么样子,以及如何翻译。
7.1 认识多语言的 XML
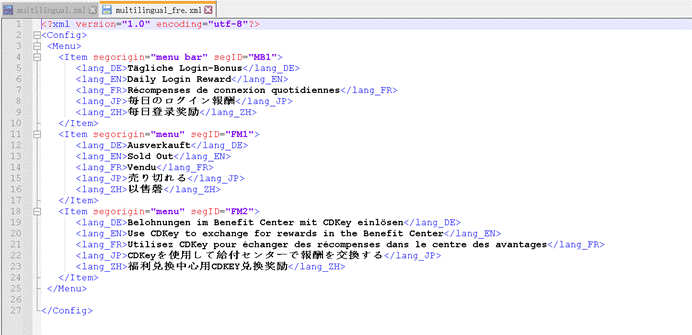
先来看一个多语言的 XML 文档示例,其实和单语言的也差不多,但是又有所不同。

我们来分析一下这个 XML :
- 声明语句:<? XML version=”1.0″ encoding=”utf-8″?>
- 有根元素:<Config>
- 有多个子元素,比如<Menu>、<Item>、<lang_DE>、<lang_EN>、<lang_FR>、<lang_JP>、<lang_ZH>等。
- 在这些元素中用不同的元素名表示需要对应的语种,如:
- <lang_DE>代表德语;
- <lang_EN>代表英语;
- <lang_FR>代表法语;
- <lang_JP>代表日语;
- <lang_ZH>代表简体中文;
- 元素还包含两个属性,其中:
- segorigion是注释;
- segID是上下文。
- 元素还包含两个属性,其中:
认识了这个 XML 文档,应该怎么翻译呢?继续往下读。
7.2 翻译多语言的 XML 文档
我们一直在讲,翻译首先要设置对过滤器,翻译多语言的 XML 文档也不例外。
多语言的 XML 文档需要用多语言 XML 过滤器,通过设置XPATH实现。
我们看一下具体操作:
7.2.1 创建多语言的项目
多语言文档肯定项目也要多语言。所以首先要创建多语言项目。
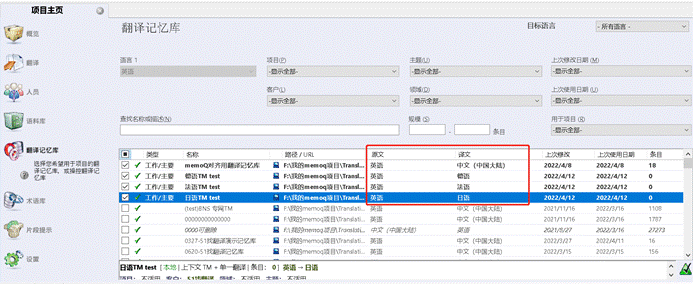
在这个项目中,我的源语言是英文,目标语言是德语、法语、日语、中文(中国大陆)。

需要注意的是:多语言项目要记得为每个语种设置记忆库。
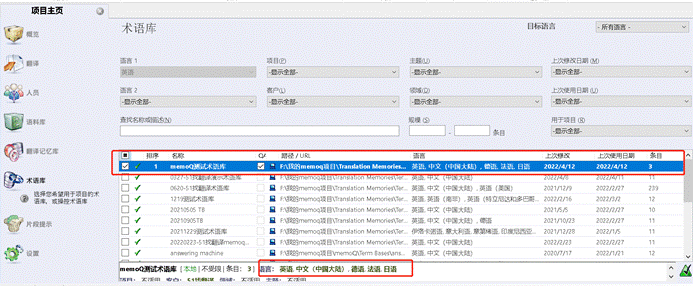
术语库可以是一个多语言的术语库。
7.2.2 设置并使用多语言 XML 过滤器
Step 1:选择性导入 > 选择 XML 文档 > 更改过滤器和配置 > 选择多语言 XML 过滤器 > 点击编辑导入规则。
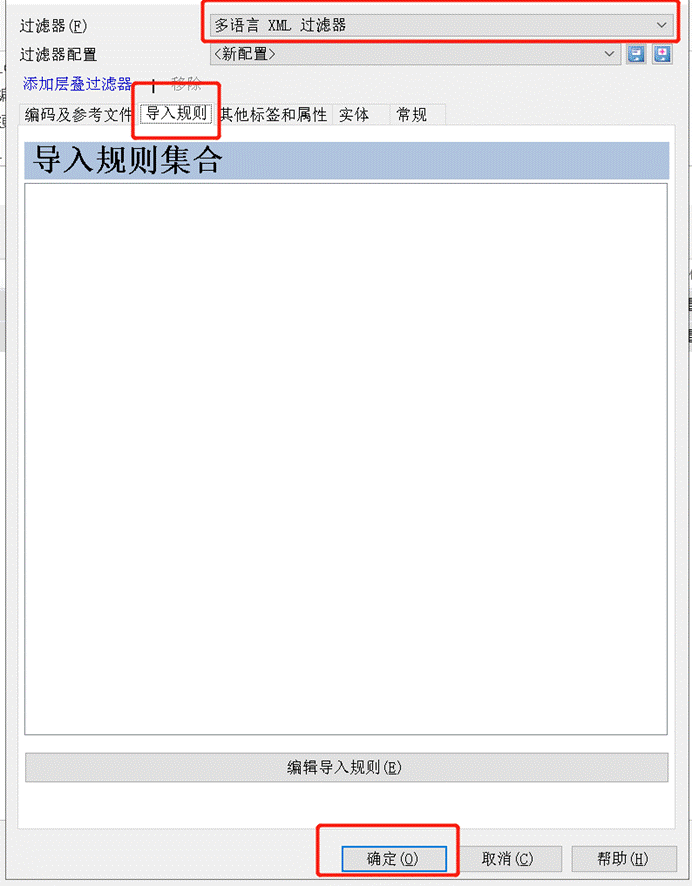
Step 2:跳转至XML 导入规则窗口,我可以在左侧点击各个元素,预览 XML 全局。
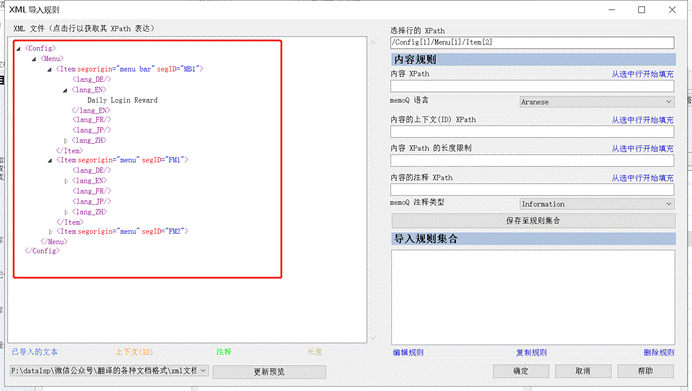
Step 3:设置 XPath。
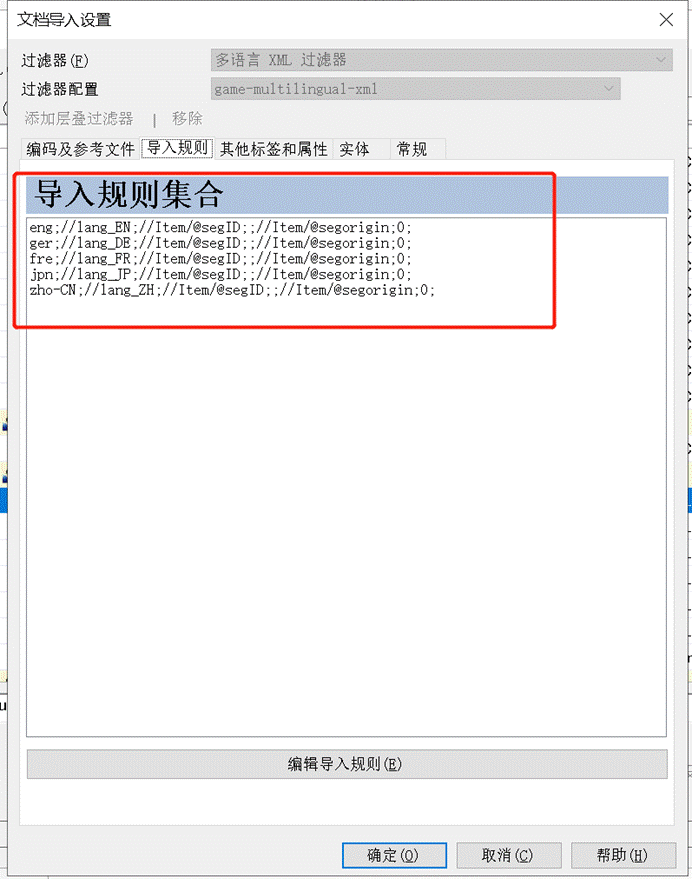
多语言的 XML 文档是通过 XPath 来实现的。所以我们要定义每个内容,设置完成一个内容就可以点击“保存至规则集合”。
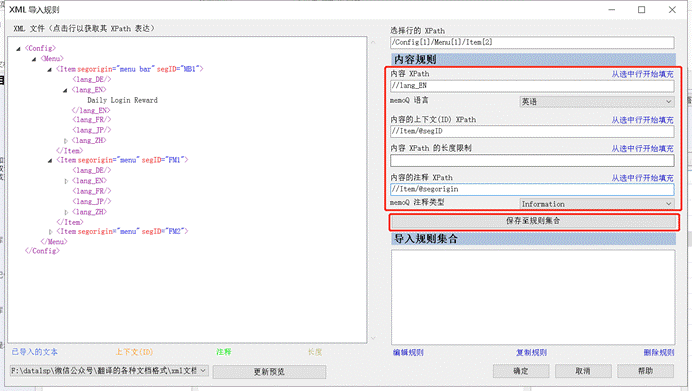
内容规则说明如下:
- 内容XPath:指的是哪个元素代表哪个语种。元素名前面用//隔开。在这里输入:
- //lang_DE,选择memoQ语言为德语;
- //lang_EN,选择memoQ语言为英语;
- //lang_FR,选择memoQ语言为法语;
- //lang_JP,选择memoQ语言为日语;
- //lang_ZH,选择memoQ语言为简体中文;
- 内容的上下文(ID)XPath:指的是元素中是否有上下文属性。元素前同样是用//隔开,元素名与属性名之间用/@隔开。在这里,segID是上下文,所以输入:
- //Item/@segID
- 内容 XPath的长度限制:指的是元素中是否有长度限制属性。在这里没有设置。
- 内容的注释 XPath:指的是元素中是否有注释属性。在这里输入:
- //Item/@segorigin
点击完“保存至规则集合”,会在左侧预览设置好的内容。
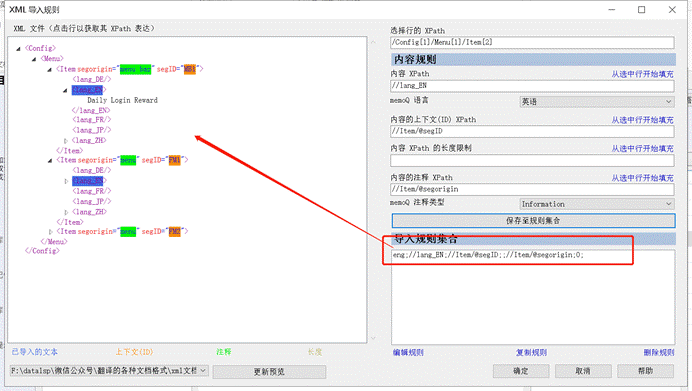
说明如下:
- 蓝色底色为已导入文本;
- 橘黄色底色为上下文(ID);
- 绿色底色为注释;
- 褐色(好像是褐色吧)底色为长度。
全部内容设置完成后,预览如下:
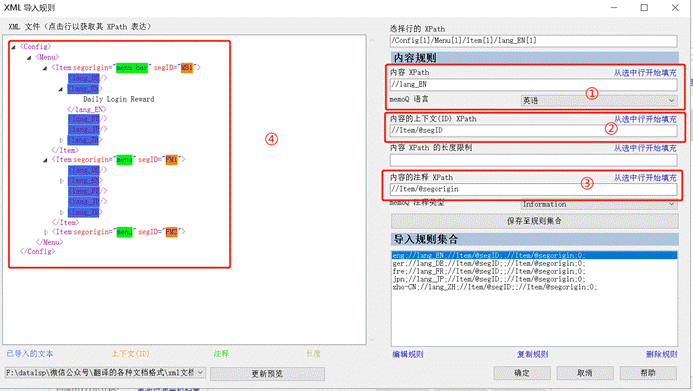
Step 4: 点击“确定”,预览设置后的导入规则;
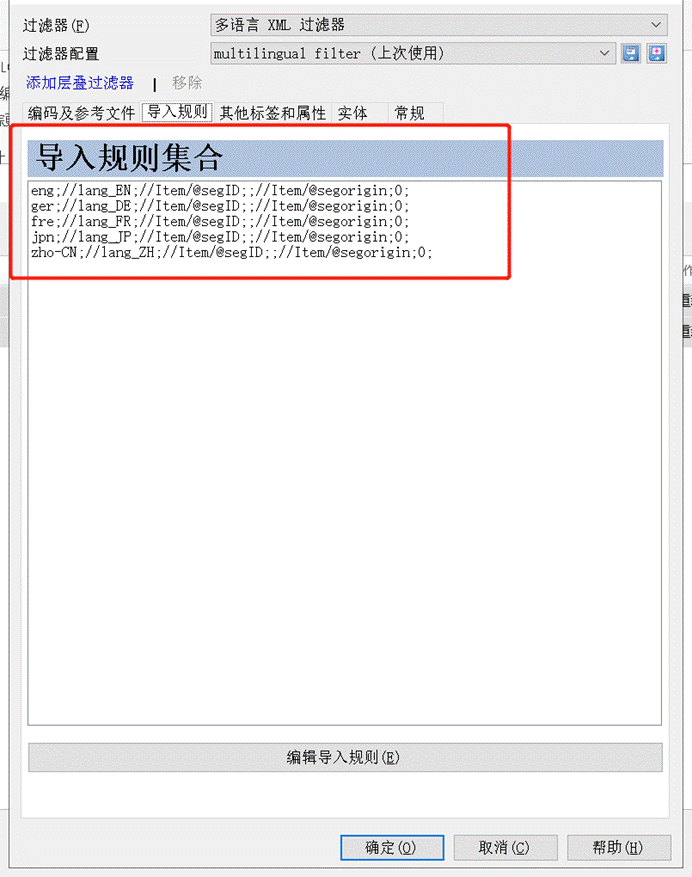
Step 5: 点击“确定” > 确定,完成多语言 XML 文档的导入
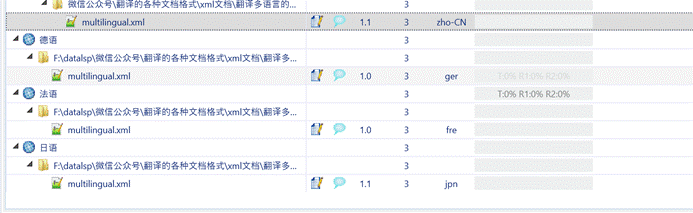
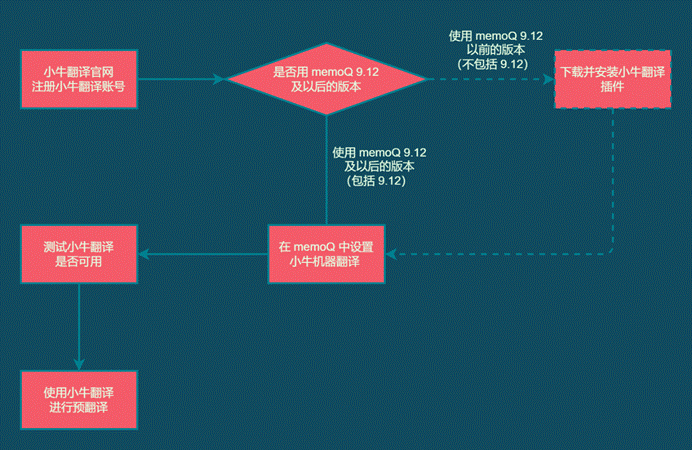
7.2.3 翻译并导出译文
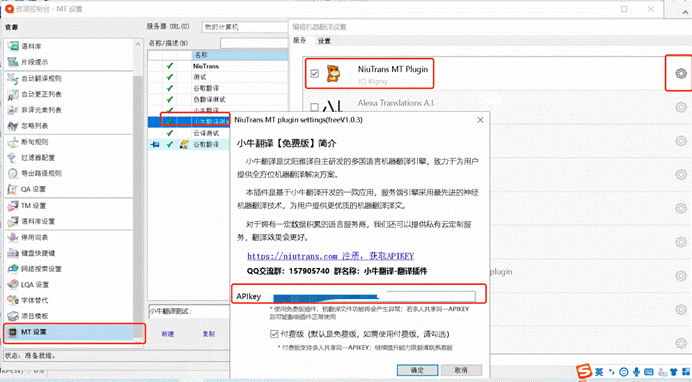
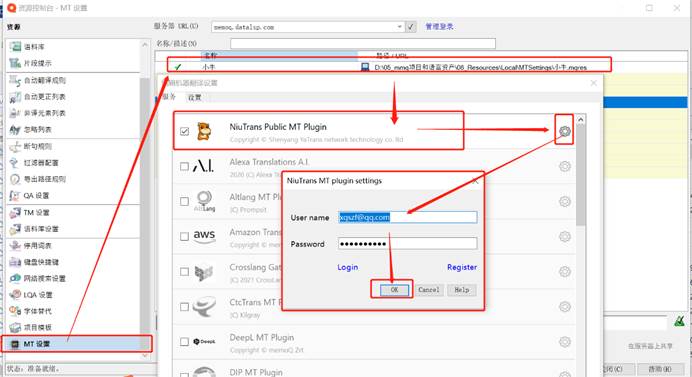
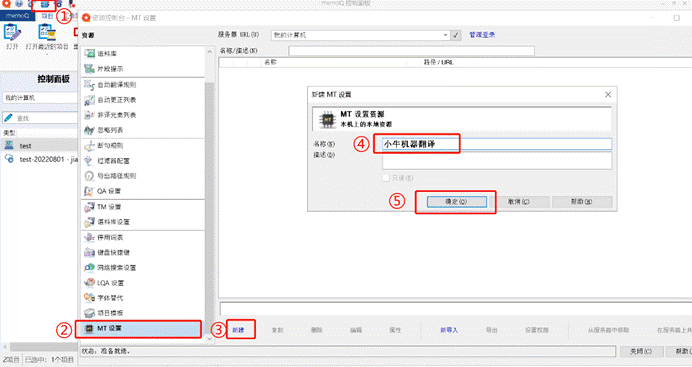
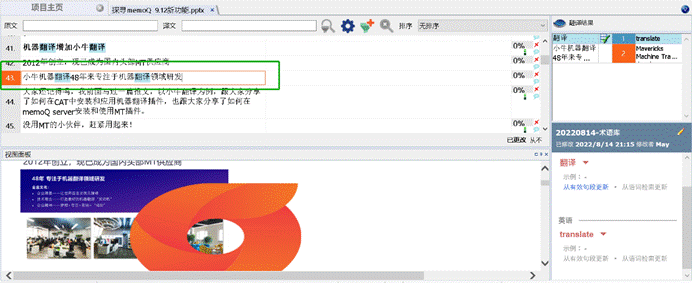
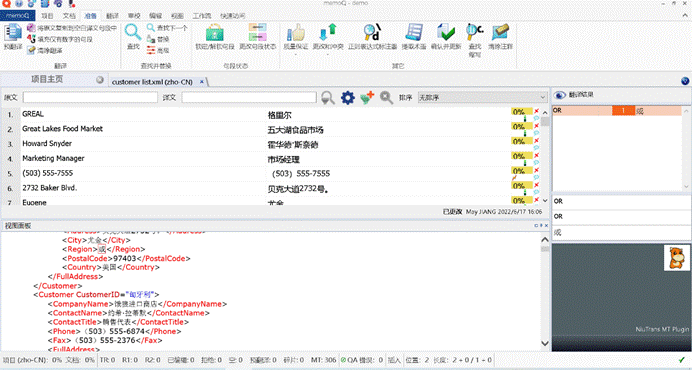
首先,打开文档,预览并翻译。在这里,我用的小牛机器翻译进行预翻译。
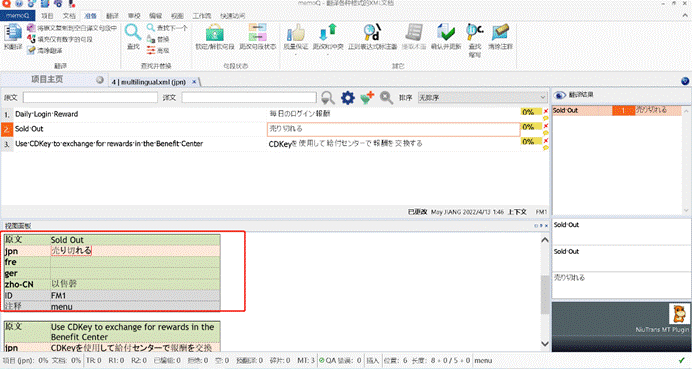
翻译后导出。我们发现,导出后的译文,每个语种都应该在自己应该在的位置:
- <lang_DE>为德语;
- <lang_EN>为英语;
- <lang_FR>为法语;
- <lang_JP>为日语;
- <lang_ZH>为简体中文;
8. 包含 DTD 的 XML 文档
再来复习普通 XML 长什么样子:
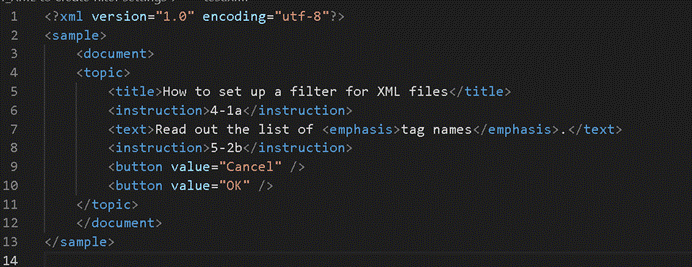
在这里,
- 第一行的**<? XML version=”1.0″ encoding=”utf-8″?>是声明语句。**
- 从第二行开始,<sample>**就是根元素**了,根元素之间还有子元素<document>
- 元素必须要有完整标签对:<document></document>或者独立标记要完整标记:<button/>
- 元素可能有属性:value就是button的属性;
- 标签对之间的文本是我要翻译的内容;标签属性值也是我要翻译的内容;
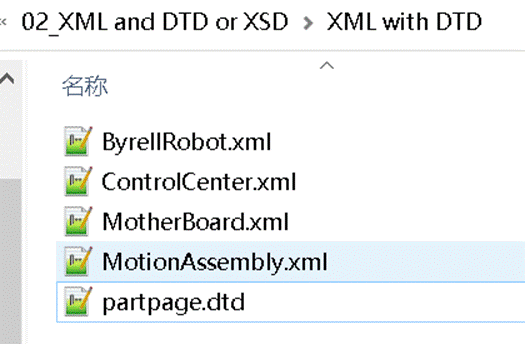
有时候,我们也会收到这样的文件包:文件包里既有 XML 文档,又有一个**dtd文档。**
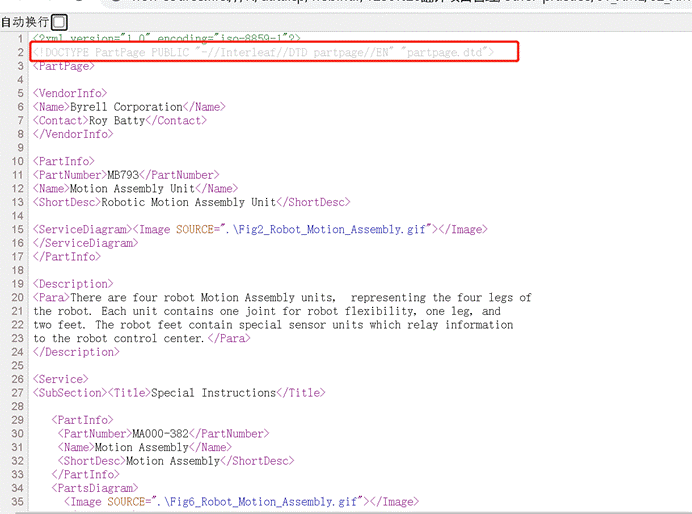
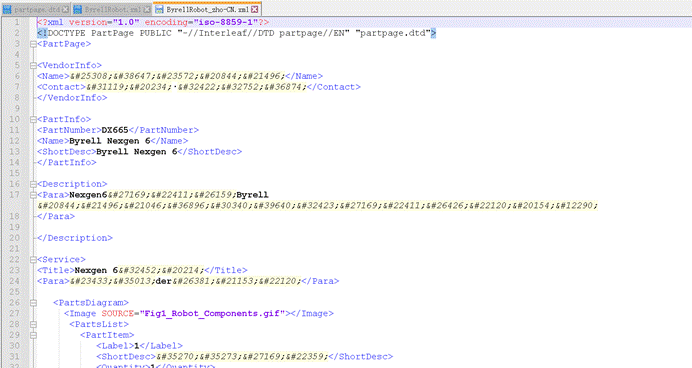
如果打开其中一个 XML 文档,是长这样的:
那么我们可以发现,这个文档多了第二行:
<!DOCTYPE PartPage PUBLIC “-//Interleaf//DTD partpage//EN” “partpage.dtd”>
其实,这是DOCTYPE 声明的内容,用来告诉您:“这是这个文档类型是一个PartPage,引用的是外部的partpage.dtd文档”。
我们还可以发现,
这个第二行的最后”partpage.dtd”不就是文件包中的后缀名为*.dtd的partpage.dtd文档
如果您打开这份*.dtd文档(其实这就是一个ASCII的文本文件)——也就是包含 DTD 的 “partpage.dtd” 文件,长这样:
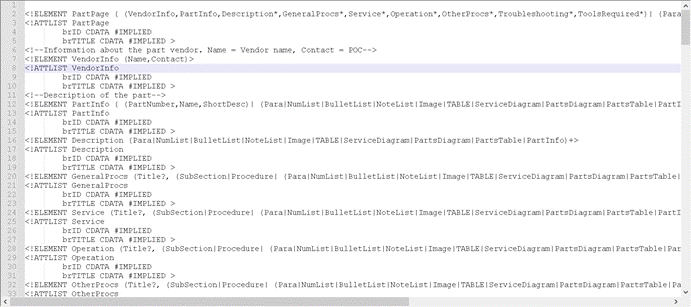
这就是含有 DTD 的 XML 文档。这就引出了另一个问题:什么是**DTD?**
8.1 什么是 DTD**?**
DTD 是英文Document Type Definition的首字母缩写,中文意思为“文档类型定义”。
通过DTD我们可以验证 XML 是“合法”,也就是说:验证您的 XML 文档结构是否拥有正确语法,或者您可以理为是否符合要求。
如果您不想知道这是什么,也可以直接往下划,直接看如何翻译含有DTD的 XML ,找到方法论。
那么问题来了:
- 正确语法是什么?或者说:要求是什么?
8.2 DTD 的构成
首先,在原 XML 中已经声明了:<!DOCTYPE PartPage PUBLIC “-//Interleaf//DTD partpage//EN” “partpage.dtd”>,您可以理解为自我介绍:
“Hi 我引入partpage文档;”

我们看一下DTD的这个构成:
8.2.1 DTD 的元素
在 DTD 中,元素通过ELEMENT来进行声明。语法如下:
<!ELEMENT 元素名称 (**元素内容)>**
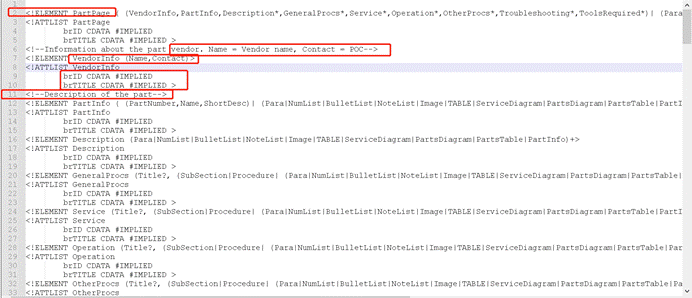
所以我们看第2行,说明了:
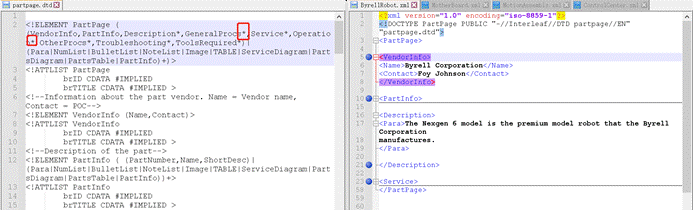
根元素PartPage元素应该包含哪几个子元素,这里有VendorInfo、PartInfo、Description、Service等。
所以您会发现,在右侧的正文 XML 中就是按照这几个元素及关系在定义的。
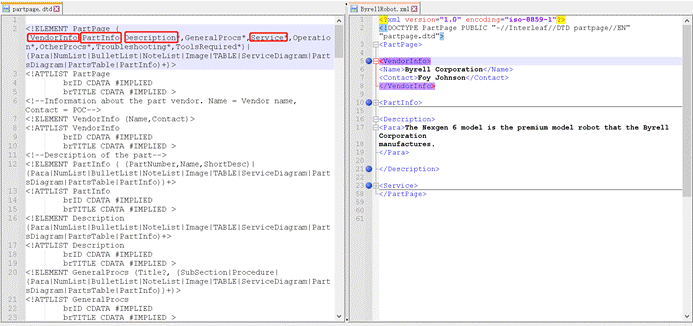
再比如第7行就定义了:父元素<VendorInfo>应该包含Name、Contact两个子元素。
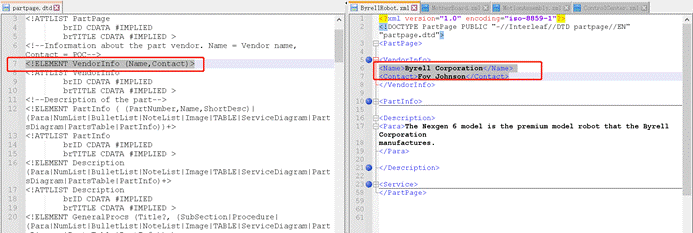
那元素名右上角的星号(***)、加号(+)号等等是什么意思呢?**
类似我们前面讲的正则的符号表示,详见:正则篇(一):认识正则表达式[1] :
- 星号(***)表示该元素出现零次或多次**。
- 理解了星号,加号就很容易理解了:加号(**+)表示该元素至少出现一次**,也就是一次或多次。
所以,在上图中,右侧的 XML 文件有VendorInfo、PartInfo、Description、Service元素,但是没有<GeneralProcs>或者<Operation>等元素。
但是我们再看下图,在右侧的 XML 中就有了<GeneralProcs>元素,但是却没有Service元素。
8.2.2 DTD 的属性
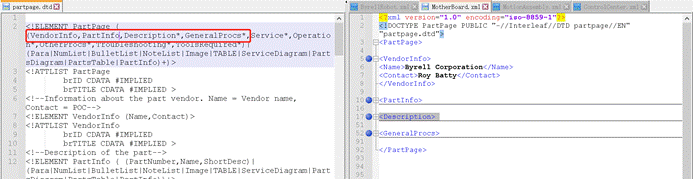
在 DTD 中,属性通过 ATTLIST 声明来进行声明。语法如下:
<!ATTLIST 元素名称 属性名称 属性类型 默认值**>**
比如这里的第100行:
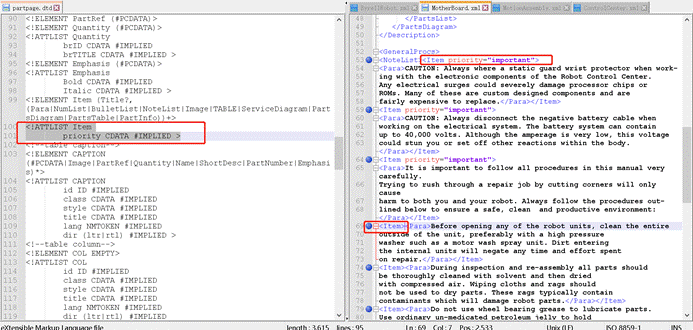
- Item**元素包含了 priority** 属性
- <priority>属性类型是CDATA。关于CDATA,参见:翻译包含HTML样式的 XML 文档 (CDATA篇)[2]
- 该元素默认值**#IMPLIED**,表示priority 属性不是必需的。所以第53行的Item有priority属性,但是像69行、74行、79行就没有priority属性。
8.2.3 DTD 的实体
前面我们讲过 XML 的实体,详见:翻译包含HTML样式的 XML 文档(实体篇)。[3]
在 DTD 中,实体通过 ENTITY 来进行声明:<!ENTITY 实体名称 “实体的值”>,或者<!ENTITY 实体名称 SYSTEM “URI/URL”>。
如果您已经懂了DTD是什么
那么我们就需要知道DTD**怎么翻译**
8.3 包含 DTD 的 XML 文档如何翻译?
在翻译包含DTD的 XML 时,可以有2步:
- 检查翻译包
- 配置及测试过滤器
8.3.1 翻译包检查
在正式启动翻译之前,我们要检查源文档和翻译包。
您需要检查:
1、收到的翻译包是单个文档还是多个文件的翻译包;如果是多个文档的翻译包,哪几个文档需要翻译?
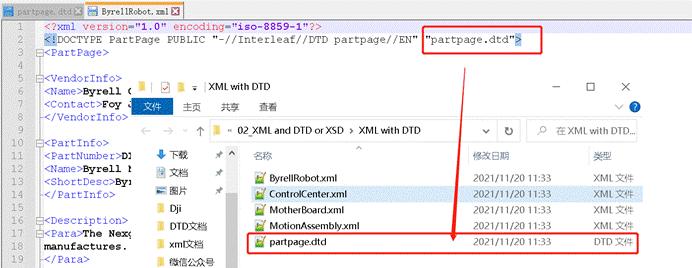
比如这个翻译包:文件包里有**4个** XML 文档,以及一个**dtd文档。**
2、检查需要翻译的 XML 文档,看一下源文 XML 文档是否有外部引用;
比如,下图中就包含了一个”partpage”的dtd引用。
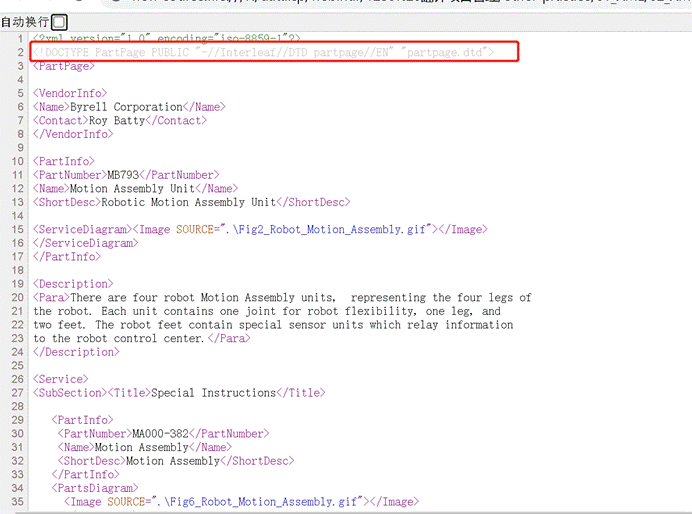
3、如果 XML 中有有外部引用,对比翻译包中的引用文档是否和声明中的引用一致。
在本案例中,根据上两张图,发现翻译包中的引用文档和声明中的引用是一致。
OK,既然收到的翻译包没有明显的错误,那我们导入memoQ进行翻译
我们前面一直讲:导入翻译文档,需要设置正确的过滤器。
那么,包含DTD的 XML 文档应该如何配置呢?
8.3.2 为包含**DTD的** XML 配置过滤器
当然,在memoQ此类的翻译工具中,过滤器也可以叫解析器。
配置过滤器有三个步骤:
- 选择正确的过滤器
- 配置过滤器
- 检查过滤器。
8.3.2.1 选择正确的过滤器
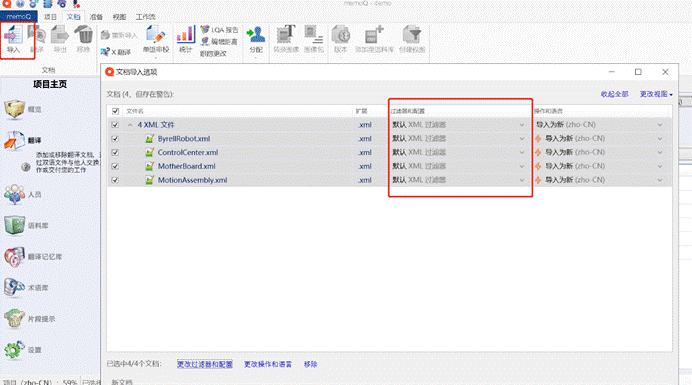
既然是 XML 文档,那么我们就用 XML 过滤器即可。
所以在导入时,选择:导入 -> 找到需要翻译的**4个** XML 文档 ->**选择** XML 过滤器,如下图所示。
8.3.2.2 配置过滤器
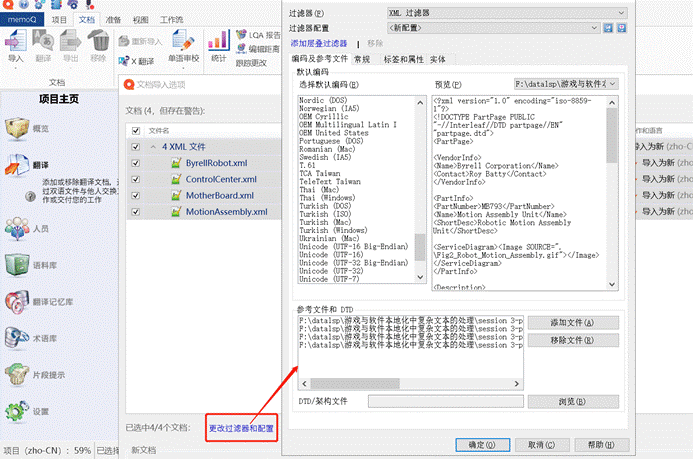
默认的过滤器不能满足我们的需要,所以我们可以更改过滤器配置。
操作如下:
1、在文档导入选项 -> 点击“更改过滤器配置” -> 跳转出“文档导入设置”窗口;
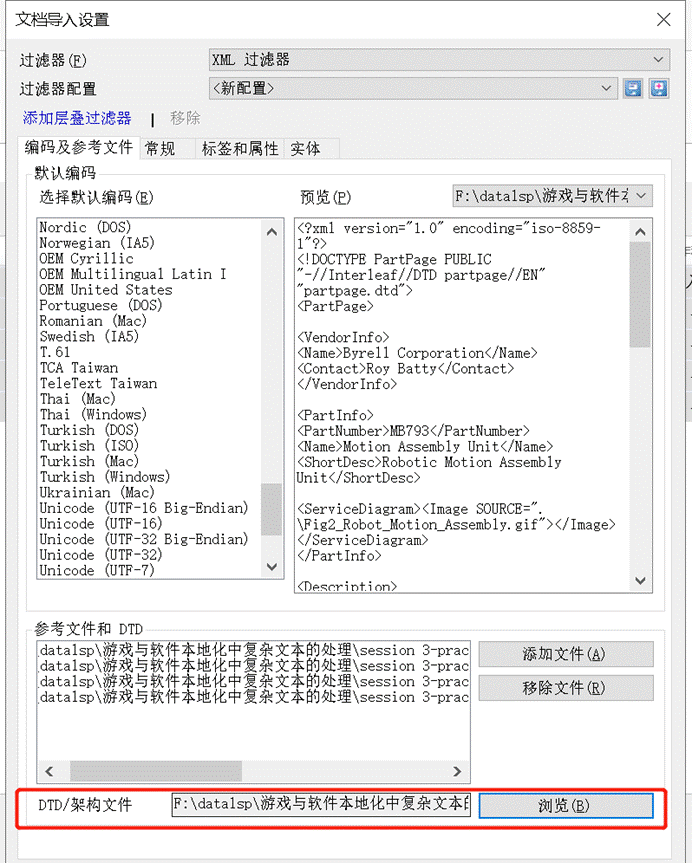
2、在“文档导入设置”窗口 -> 点击“DTD/**架构文件”的“浏览” -> 选择正确的dtd文档**;
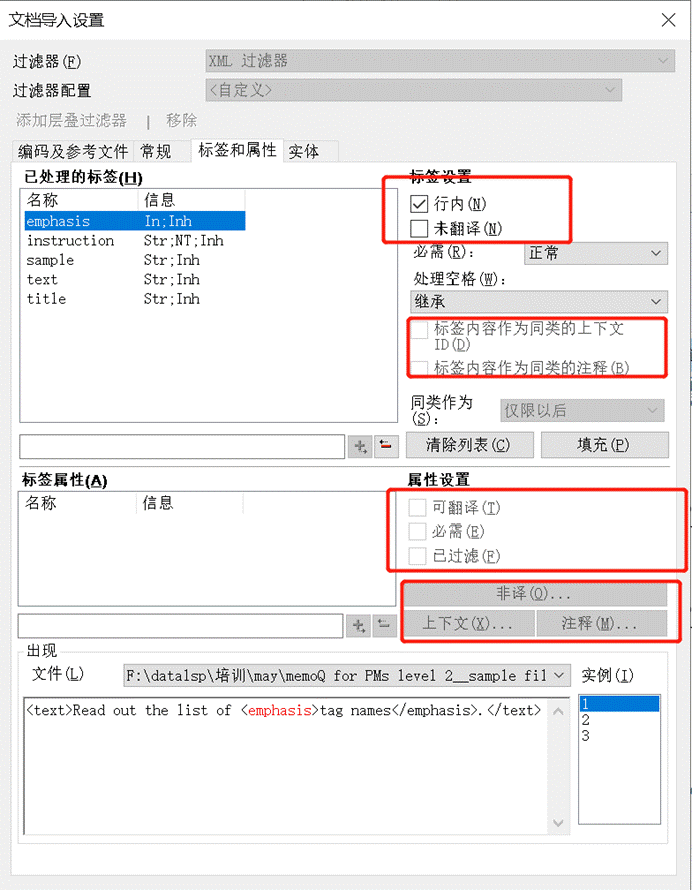
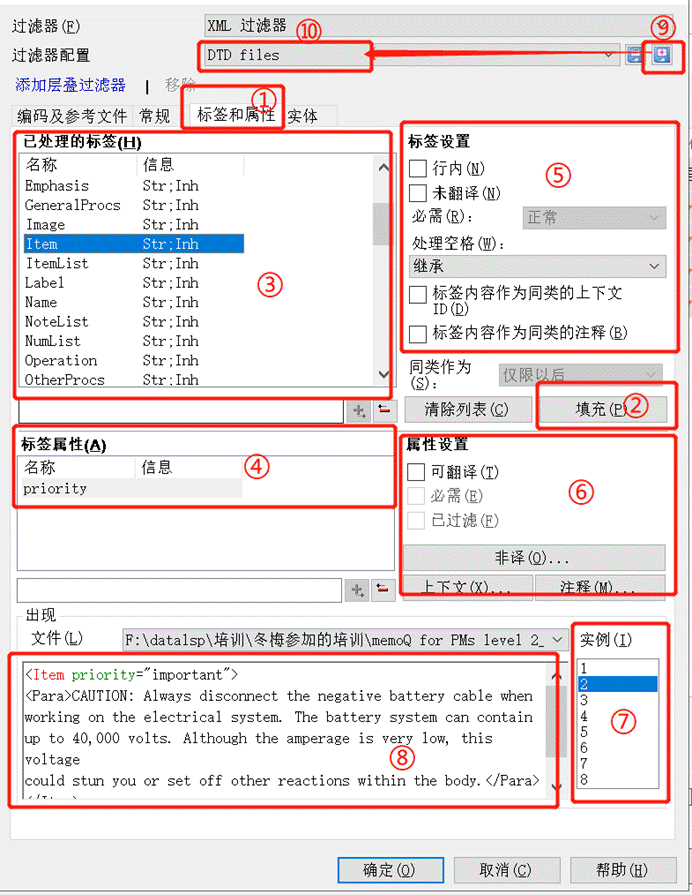
3、点击“①**标签和属性**” -> 配置 XML 过滤器。具体如下:
- 点击 “②**填充” -> 自动填充 ③标签** 和 ④**标签属性**
- 在 ⑤**标签设置**” -> 设置哪些标签需要翻译、哪些标签属于行内标签
- 在 ⑥**属性设置**” -> 设置哪些标签属性需要翻译、哪些标签属于非译元素或上下文等条件
- 可以参考 ⑦**实例** 为每一个 ③**标签** 和 ④**标签属性**单独设置不同条件
- 还可以在 ⑧**预览**区预览实际文件内容
- 您还可以点击 ⑨**保存过滤器,保存并 ⑩重命名一个新的过滤器**,供下次使用。
更多关于 XML 翻译的解析器设置,请参考:如何翻译单语 XML 文档?[4]
4、过滤器配置完成后,点击确定即可导入翻译文档
8.3.2.3 检查过滤器
按照前面的操作,导入后如下图所示:
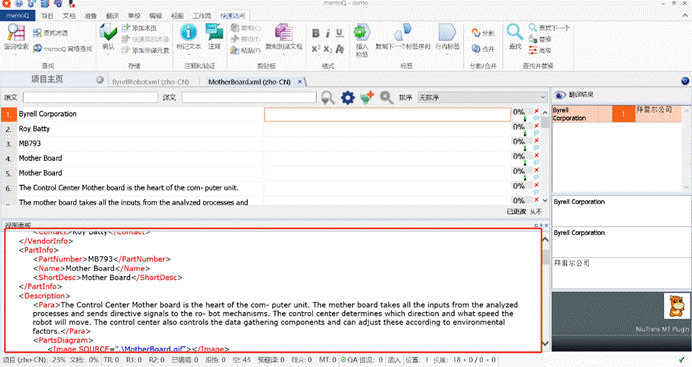
为了保障译文的格式准确性,我们要测试,看一下译文是否可以按照目标语言顺利导出
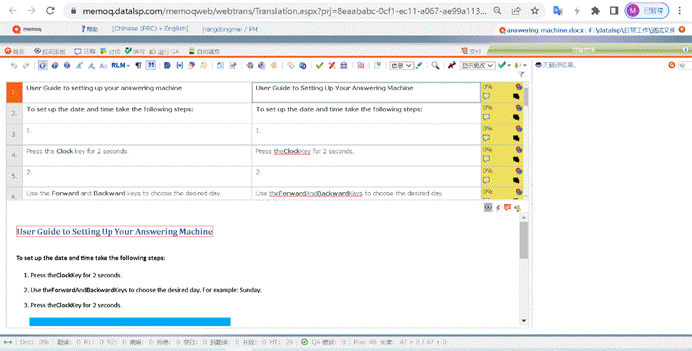
比如在这里,我借助小牛机器翻译,利用MT进行了预翻译。
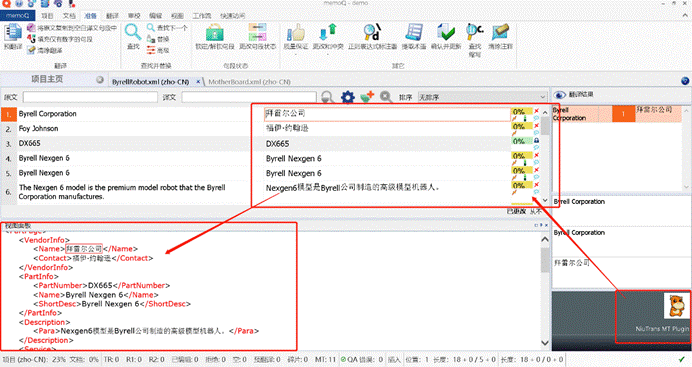
更多关于MT预翻译的内容,参考:机器翻译在CAT中的应用[5]
并把MT的译文导出检查一下~如果导出后的译文如图所示,可以顺利显示,就说明是可行的:
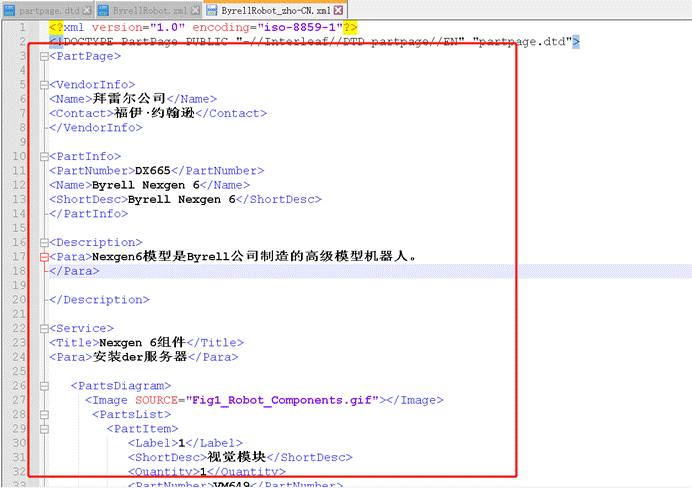
果然没问题,那我们就可以正式启动翻译啦
更多关于memoQ翻译的操作,详见:memoQ单机版入门指南[6] 。
给大家留个一个思考题:如果导出的译文是乱码,如下图所示,该如何解决 ?
这其实是在进行应用程序本地化中的另一个常见问题:编码问题。
以后会分享的。
9. 包含 XSD 的 XML 文档
有时还会遇到一个 DTD 的替代者,XML Schema Definition(XSD),也是定义 XML 文档的合法构建模块,非常类似 XSD,也是应用程序本地化中常见的文档。
所以,我们来简单了解一下XML Schema Definition**(XSD)**。
9.1 XSD**的定义?**
XML Schema 的作用是定义 XML 文档的合法构建模块。
通过XSD我们可以验证 XML 是“合法”,同理,我们通过xsd也是为了验证 XML 是否“合法”。
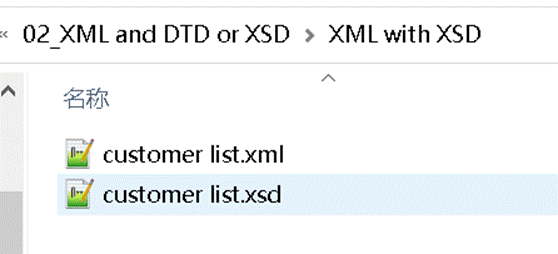
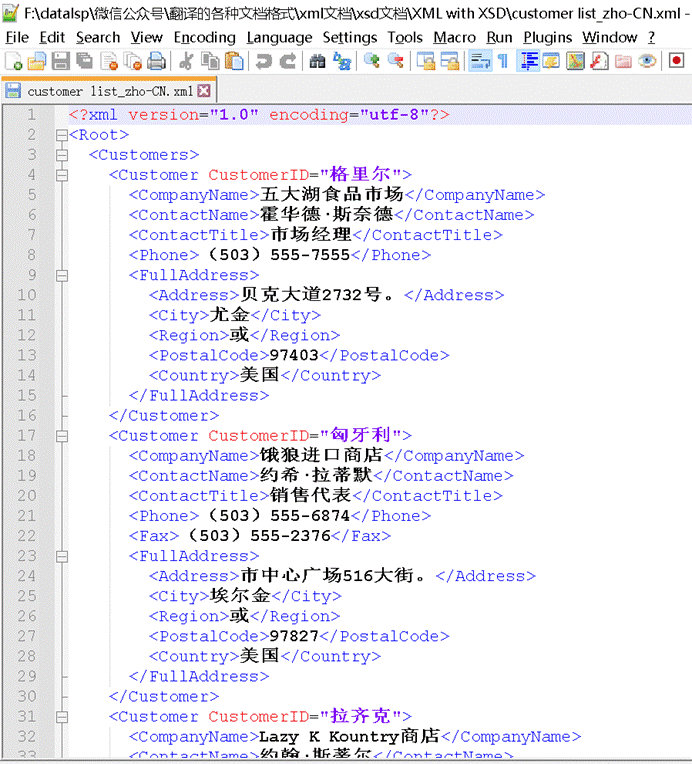
在这里我用一个翻译包给大家看一下:
文件包里既有 XML 文档,又有一个 *.xsd 文档。如图所示。
其实如果您在自己电脑中检索xsd的话,也会找到很多xsd文档,只不过您可能不知道而已。
比如我在我电脑里用 Everything 进行检索,就找到很多XSD文档,如图所示。
我们发现:
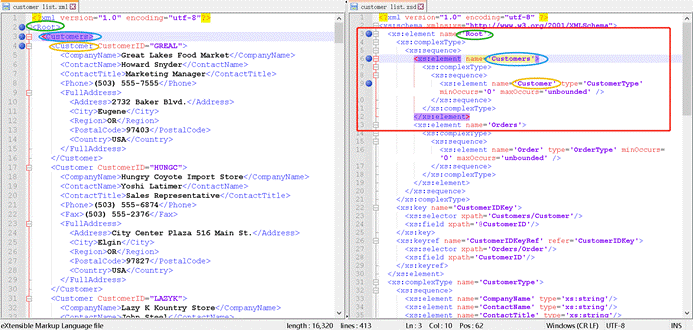
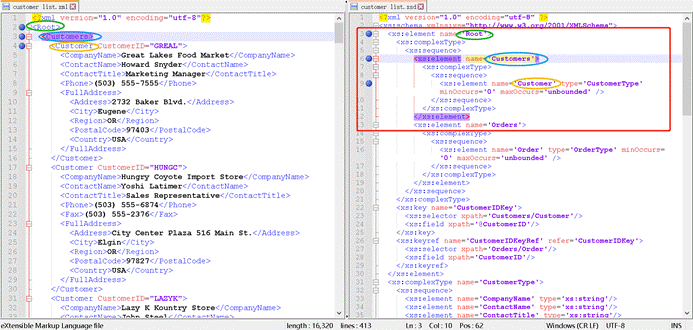
- XML中的元素名就是右侧**XSD文档中定义好的**,比如:
- XML 第2行的根元素<Root>,是右侧XSD文档第3行的name属性值;
- XML 第3行的元素<Customers>,是右侧XSD文档第6行的name属性值;
- XML 第4行的元素<Customer>,是右侧XSD文档第9行的name属性值。
- 左侧XML的结构是按照右侧**XSD定义的**,比如:
- 在右侧XSD文档中,第一个根元素xs:element属性值Root,就是左侧的 XML 的根元素<Root>;
- 在右侧XSD文档中,第二行子元素xs:element属性值Customers,就是左侧的 XML 的<Root>的子元素<Customers>。
- 同理,<Customer>也是<Customers>的子元素。
- 左侧XML元素的数量是按照右侧**XSD定义的,**比如:
- 在右侧XSD文档中,第九行就说明了 XML 第4行的元素<Customer>,是可以出现0次-无数次的。
对 XML Schema**来说,它可以:**
- 定义文档中的元素名,元素的属性值
- 定义元素和属性的数据类型
- 定义各个元素的关系,哪个元素是子元素,哪些元素是兄弟元素
- 定义子元素的次序
- 定义子元素的数目等
所以说 XML Schema 比 XSD 更强大,而且据说很快会在大部分网络应用程序中取代 XSD。
9.2 XSD 的构成
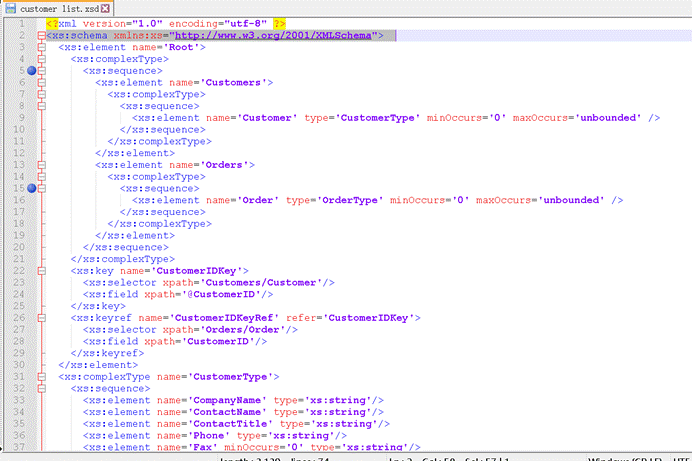
如上图所示,首先,XSD也是 XML 文档,所以结构是符合 XML 的文档结构:
- 第一行的**<? XML version=”1.0″ encoding=”utf-8″ ?>是声明语句。**
- 从第二行开始,xs:schema**就是根元素**<schema>元素。
<schema>元素可包含属性。一个 schema 声明往往看上去类似这样:<xs:schema XML ns:xs=”http://www.w3.org/2001/ XML Schema”>
- 根元素之间还有子元素xs:element、xs:complexType等。
我们看一下XSD的这个构成。
当然,我的原则还是:只认识这个文档,看看它有没有明显的错误,能进行译前分析就好了
9.2.1 XSD 的元素
在 XSD 中,元素依然是通过**element来进行定义。**语法如下:
<xs:element name=”xxx” type=”yyy”/>
其中:
- name**的属性值** xxx**,指元素名**
- type**的属性值** yyy**,指元素的数据类型**
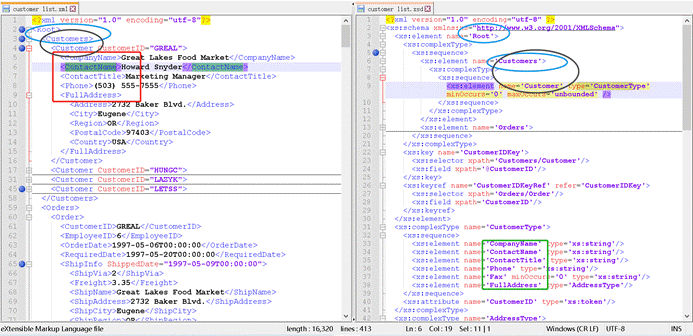
所以,如图所示,
- 在右侧xsd中(绿色方框)就定义了左侧 XML 的元素(红色方框)有:<CompanyName> <ContactName> <ContactTitle>等;
- 其中,
- 如蓝色椭圆所示,元素 <Customers> 是根元素<Root>的子元素;
- 如灰黑色椭圆所示,元素 <Customer> 是元素 <Customers> 的子元素;
比如复合元素(complexType)是什么,在这个案例中,其实<Root>、<Customers>就是复合元素。
9.2.2 XSD 的属性
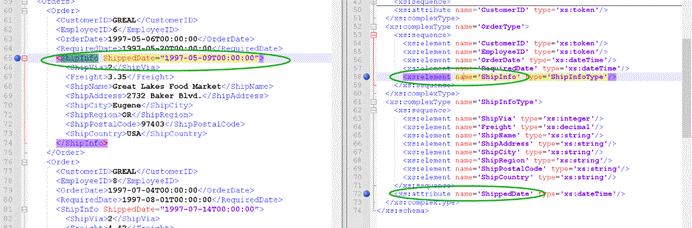
在 XSD 中,属性通过 attribute 来进行声明。语法如下:
<xs:attribute name=”xxx” type=”yyy”/>
如图所示,在右侧XSD中就声明了:
元素**<ShipInfo>的属性是ShippedDate,其属性值(左侧** XML 文档的第**65行)应该是日期时间数据类型,也就是在右侧第72行看到的dateTime。**
9.2.3 关于 XSD 的其它
当然,其它内容xsd的介绍,大家感兴趣的话可以自行去网络上查找,比如:
通过**sequence元素来表示子元素出现的顺序,每个子元素可出现** 0 到任意次数。

通过**key元素来指定属性或元素值(或一组值)必须是指定范围内的键。**

如果您已经懂了XSD是什么,那么 XSD**怎么翻译**呢?
9.3 翻译 XSD 的文档
在翻译包含XSD的 XML 时,也是有2步:
- 检查翻译包
- 配置及测试过滤器
9.3.1 翻译包检查
在正式启动翻译之前,我们要检查源文档和翻译包。
您需要检查:
1、接收的翻译包是单个文档还是多个文件的翻译包;如果是多个文档的翻译包,哪几个文档需要翻译?
比如这个翻译包:文件包里有**1个** XML 文档,以及一个*.xsd**文档。**
明确一点:xsd**是架构文件,不需要翻译,需要翻译的是其** XML 文档
2、检查需要翻译的 XML 文档,看一下源文 XML 文档和**xsd是否一致**;
在这个案例中,我们发现:
- 左侧 XML 中的元素名和属性值和右侧**XSD文档的定义是一致的**,比如: XML 第2行的根元素<Root>,是右侧XSD文档第3行的name属性值;
- 左侧 XML 的结构是按照右侧**XSD定义的**,比如:在右侧XSD文档中,第一个根元素xs:element属性值Root,就是左侧的 XML 的根元素<Root>。
OK,既然收到的翻译包没有明显的错误,那我们就可以利用**memoQ进行翻译了~**
我们前面一直讲:导入翻译文档,需要设置正确的过滤器。
那么,包含XSD的 XML 文档应该如何配置呢?
9.3.2 为包含**XSD的** XML 配置过滤器
和配置DTD完全一致。
我们在前面讲过,翻译包含DTD的 XML 文档[7] ,配置过滤器有三个步骤:
- 选择正确的过滤器
- 配置过滤器
- 检查过滤器。
翻译包含架构文件的 XML 操作也是一模一样!
9.3.2.1 选择正确的过滤器
既然是 XML 文档,那么我们就用 XML 过滤器即可。
所以在导入时,选择:导入 -> 找到需要翻译的 XML 文档 ->**选择** XML 过滤器,如图所示。
9.3.2.2 配置过滤器
默认的过滤器不能满足我们的需要,所以我们可以更改过滤器配置。
操作如下:
1、在文档导入选项 -> 点击“更改过滤器配置” -> 跳转出“文档导入设置”窗口;
2、在“文档导入设置”窗口 -> 点击“DTD/**架构文件”的“浏览” -> 选择正确的XSD文档**;
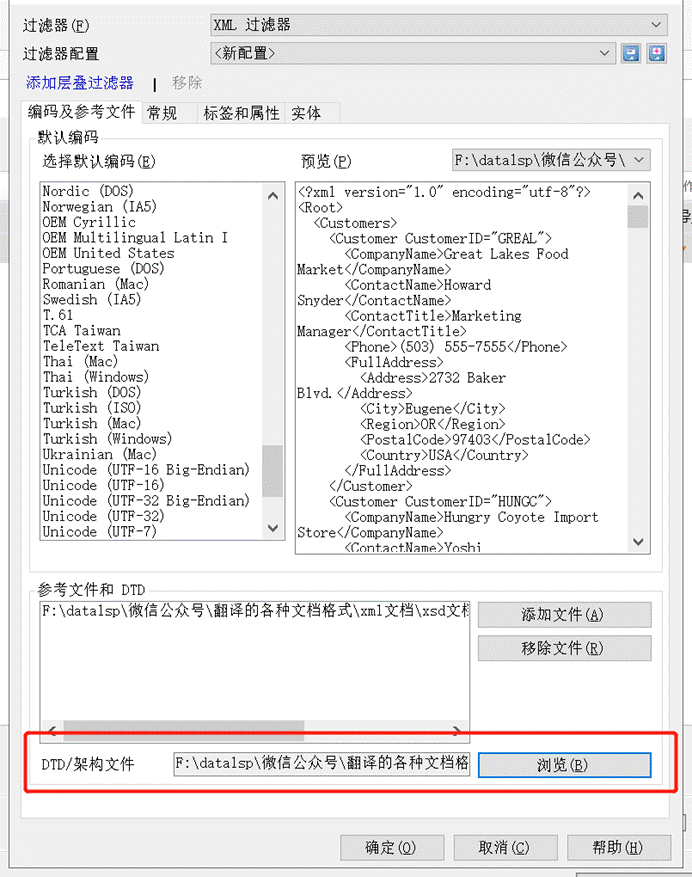
3、点击“①**标签和属性” -> “②填充**”
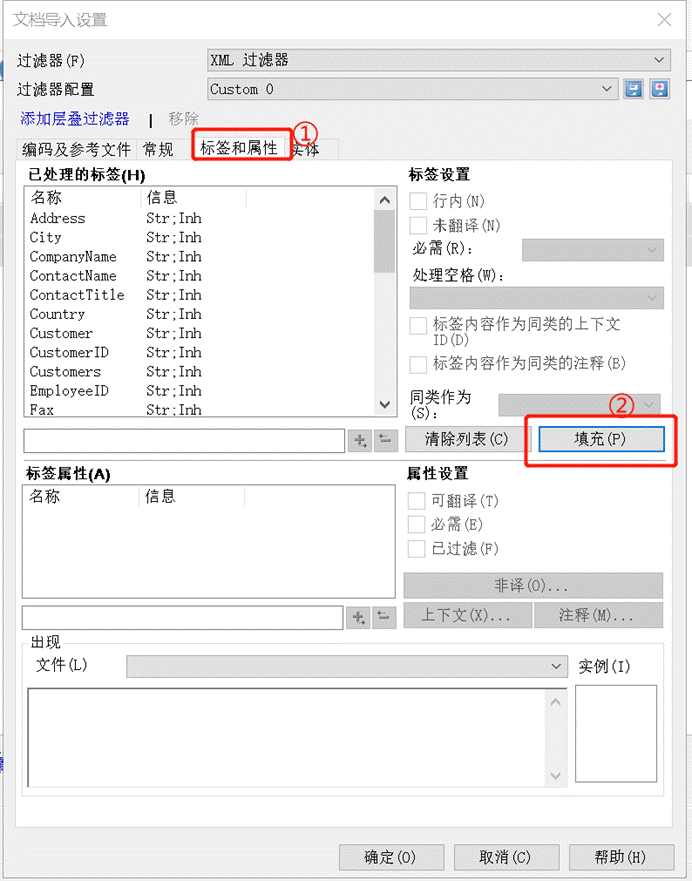
4、自动弹出Namespace URL -> 点击确定
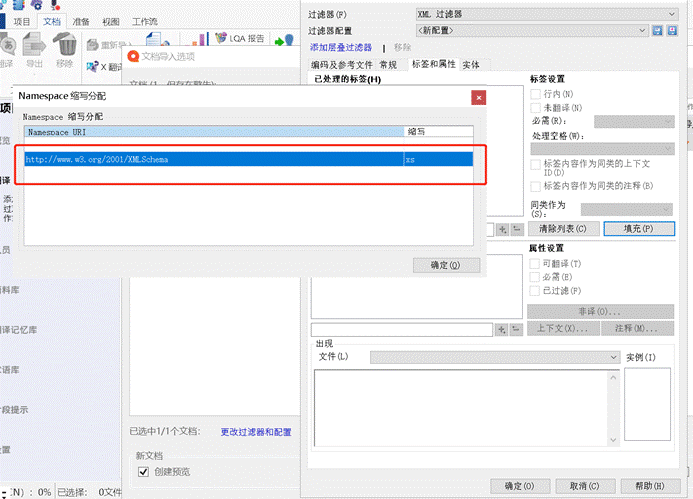
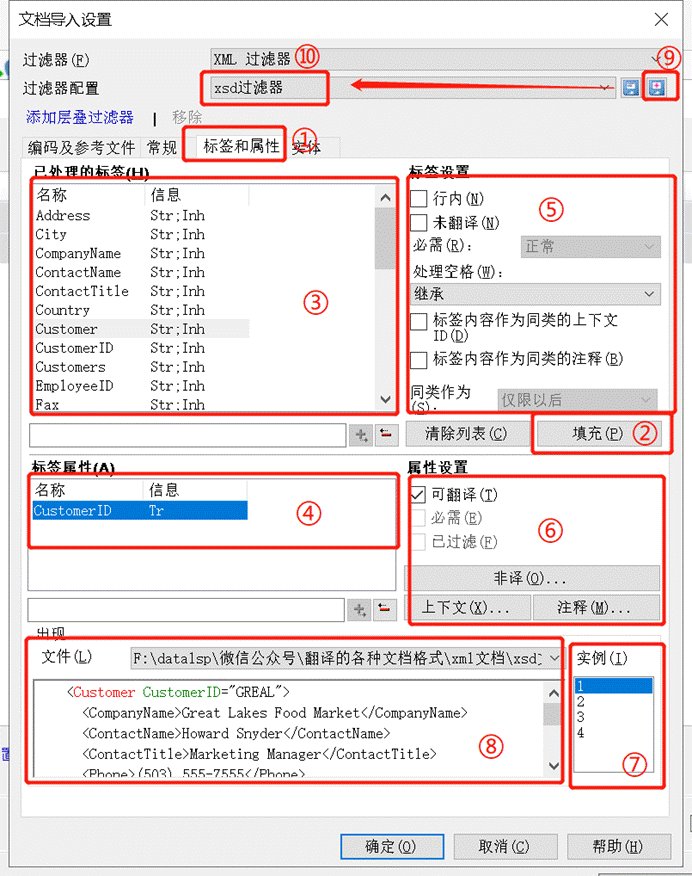
5、配置如图的 ③**标签** 和 ④**标签属性**
- 在 ⑤**标签设置**” -> 设置哪些标签需要翻译、哪些标签属于行内标签
- 在 ⑥**属性设置**” -> 设置哪些标签属性需要翻译、哪些标签属于非译元素或上下文等条件
- 可以参考 ⑦**实例** 为每一个 ③**标签** 和 ④**标签属性**单独设置不同条件
- 还可以在 ⑧**预览**区预览实际文件内容
- 您还可以点击 ⑨**保存过滤器,保存并 ⑩重命名一个新的过滤器**,供下次使用。
更多关于 XML 翻译的解析器设置,请参考:如何翻译单语 XML 文档?
过滤器配置完成后,点击确定即可导入翻译文档。
9.3.2.3 检查过滤器
按照前面的操作,导入后如下图所示:

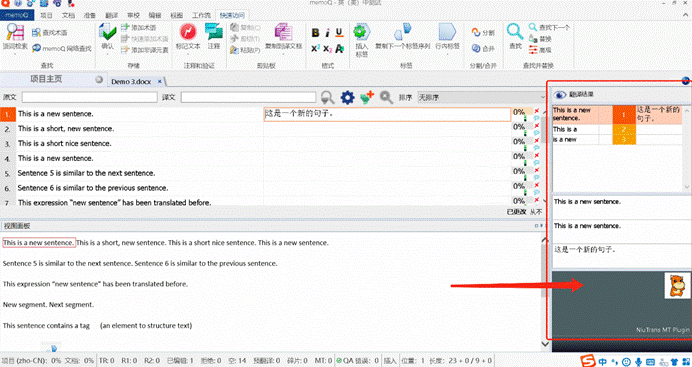
我们发现:编辑器的界面看上去都是**OK的**,比如:
- ① 是**memoQ的功能区;**
- ② 是**memoQ的翻译区,**我们可以在这里翻译;
- ③ 是**memoQ的预览区,**我们可以在这里预览原文;
- ④ 是**memoQ的翻译结果区,**所有的翻译结果(机器翻译、术语库、记忆库、片段提示等)都在这里呈现;
- ⑤ 是文档的统计栏,我可以看项目和文档的统计情况,比如进度、已编辑的句段统计、QA统计、原文译文的长度比例和字符数量等等。
9.3.3 测试译文
但是,过滤器配置完,不代表万事大吉
记得我们之前讲过的编码问题吗?如图所示,虽然翻译好了,但是导出后的编码有问题。
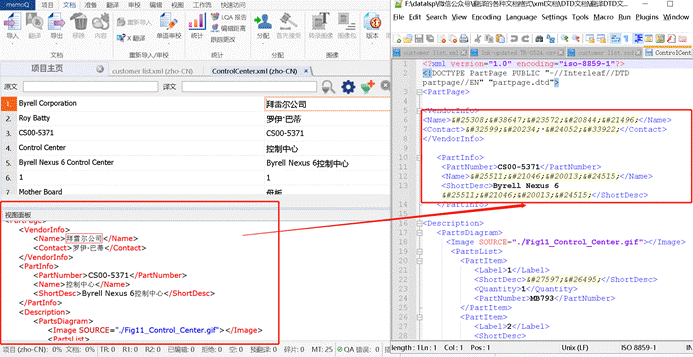
所以说,为了保障译文的格式准确性,我们要测试,看一下译文是否可以按照目标语言导出
比如在这里,我依然借助小牛机器翻译,利用MT进行了预翻译。
更多关于MT预翻译的内容,参考:机器翻译在CAT中的应用[8]
并把MT的译文导出检查一下~如果导出后的译文如图所示,可以顺利显示,就说明是OK的:
果然没问题,那我们就可以正式启动翻译
大家分享:如何在翻译的过程中基于样式表进行 XML 文档的显示预览。
10. 基于样式表预览 XML 文档的发布状态
我们前面讲过,XML 是没有样式的,HTML 有。
CSS 是 HTML 的样式表,通过 CSS 的设置,可以告诉浏览器:“我的网页布局是这样那样显示的**~”。包括颜色、字体、文本大小、元素之间的间距、元素的位置和布局、要使用的背景图像或背景颜色、不同设备的不同显示和屏幕大小等等。
那,XML 的样式表怎么配置呢?就是借助 XSLT 生成的
10.1 使用 XSLT 预览 XML
如果您不想了解 xslt,只想了解如何翻译的话,可以直接跳至下一节。
而 XSLT (eXtensible Stylesheet Language Transformations) 则是 XML 的样式表,**它远比** CSS 更加完善。
通过 XSLT 的设置,可以告诉浏览器或者服务器:“我的 XML 文件是这样那样显示的。”
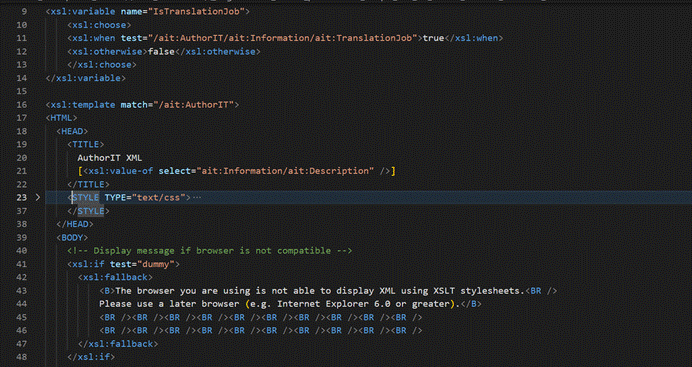
比如,这里我有一个样式表:
我们不讲样式表如何写,我也不是程序员,如果您感兴趣,可以去搜索 XSLT 教程: https://www.w3school.com.cn/xsl/index.asp)。
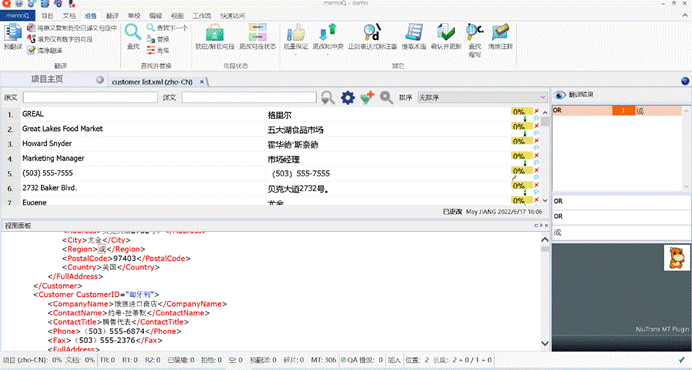
这是我需要翻译的 XML 文档,在这个 XML 文档中添加了 XSL 样式表引用:
10.2 翻译时,如何预览 XML 文件
如果没设置预览文档的话,导入后的预览仍然是按照 XML 文档格式来的:
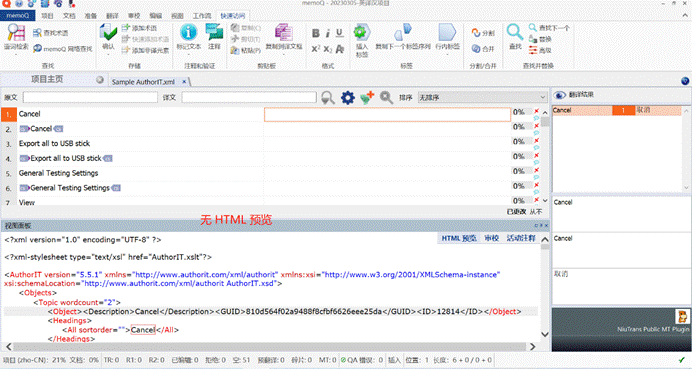
memoQ 支持翻译过程中只需要配置 XSLT 样式表,即可预览 XML 文件。
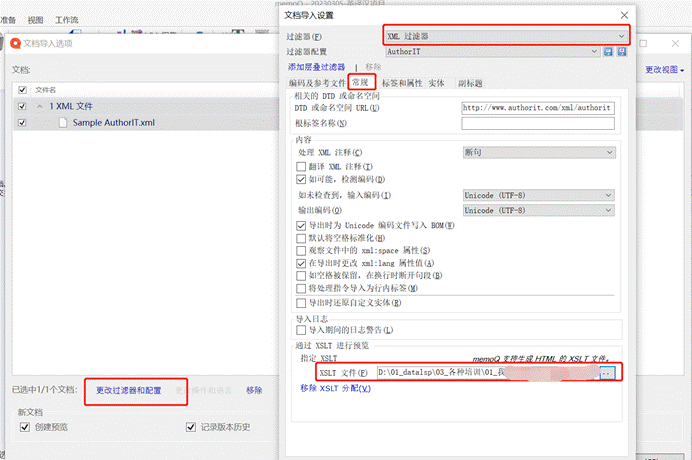
您只需要:在导入文档时,使用”选择性导入” -> “更改过滤器和配置” -> 在默认的” XML 过滤器” 下,点击”常规” -> 并”指定 XSLT 文件“。
导入后即可在预览区显示 XML
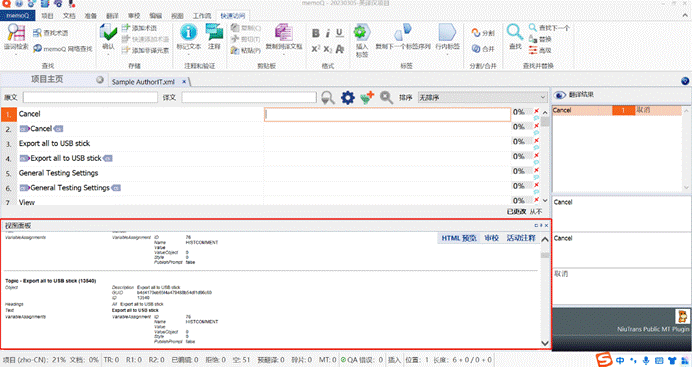
以上就是有关XML文档的全部内容。
如仍有疑问,欢迎咨询。
作者:姜冬梅
© Copyright 2023. 大辞科技 沪ICP备17050550号  沪公网安备 31011402006110号
沪公网安备 31011402006110号




