Table Of Contents
show
一、翻译包含HTML样式的XML文档(实体篇)
入门XML的时候,您只需要知道:
这一部分我再带来高阶一点的XML文档的知识。先从包含HTML样式的XML文档讲起。
比如,这里有一个文本:

里面有一堆看上去乱七八糟的东西,比如:<和>。
这些乱七八糟的东西其实是实体。
如果您看不懂这个文档,我再给您放另一个图:

上述两个图,除了第一张图多了一些乱七八糟的“实体”,其它都是一样的。
是的,这两个文档就是同一个文档,只是写法不同。
为什么写法不同呢?我们先讲实体的概念。
1.1 什么是实体?
XML规范规定,如果有些字符(详见下列表格)出现在要显示的文本中,它们应该写成实体。
| 如果您想要 | 您需要改为: |
|---|---|
| < (小于号) | < |
| > (大于号) | > |
| &(和) | & |
| ‘ (英文单引号) | ' |
| ” (英文双引号) | " |
我们来看个例子。
假设您想实现的文本是:
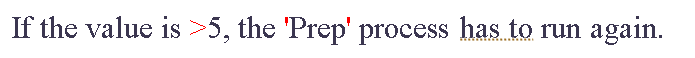
您的XML应该这么写:

在这里:
- 大于号没有写成>,而是
> - 单引号也没有直接写为’,而是
'
这就是实体。XML的实体是对数据的引用,而不是直接使用该数据。
通过上述表格,我们也发现了,实体的标准写法是:
- 以一个与字符(&)开始,
- 以一个分号(;)结束。
那,遇到包含实体的文本,应该怎么翻译呢?
1.2 如何翻译包含实体的XML文档?
我们回到图一的文档:
如果把这个文档直接导入memoQ进行翻译,默认情况下,memoQ默认的XML过滤器就可以自动识别这样的文本。
所以,如果这个文本直接导入memoQ,会是这样的:
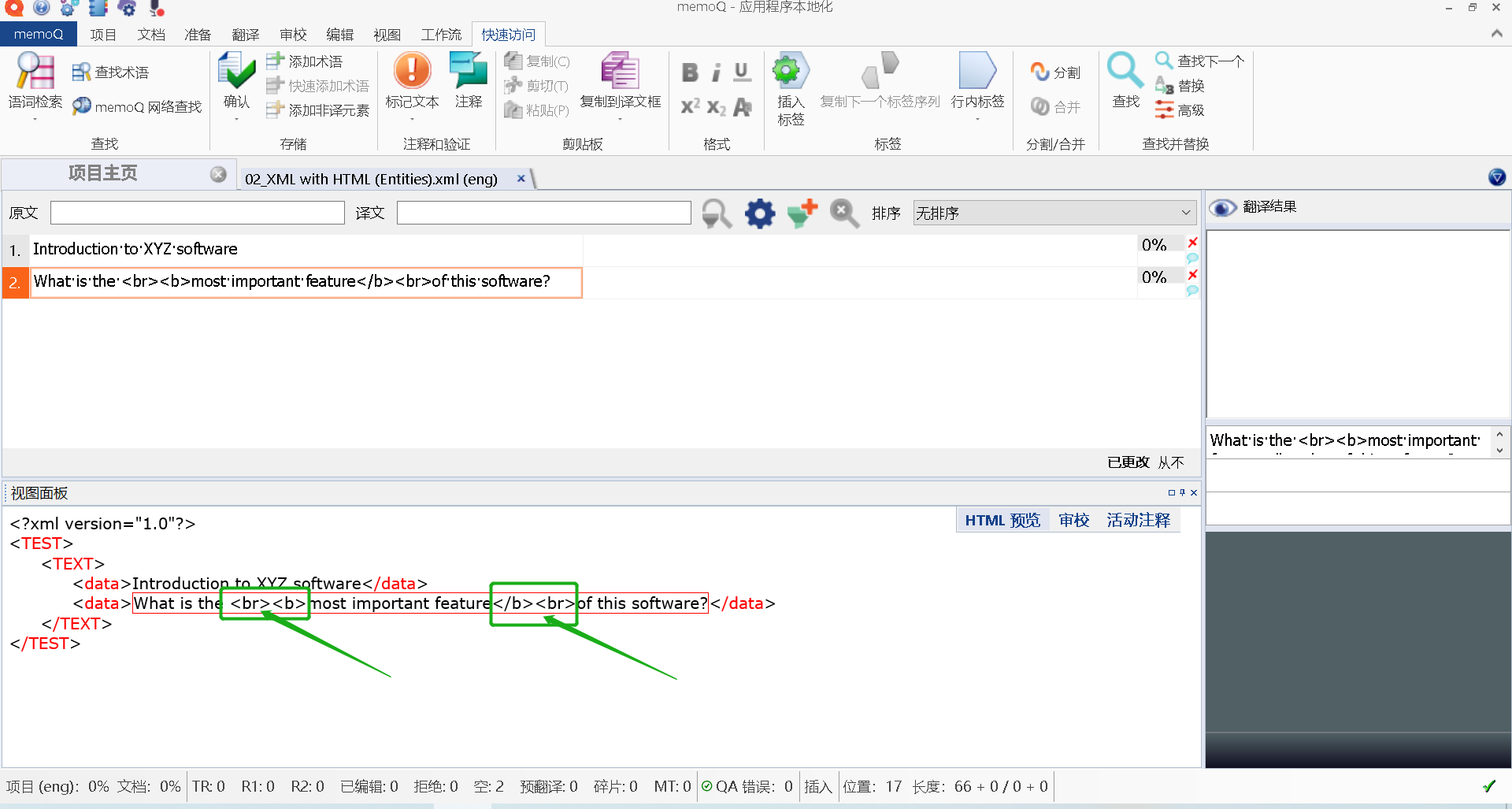
是的,我们发现了:
- memoQ自动把
<转为了<, - 把
>转为了>。
这时候我们也发现,咦,memoQ自动转换为HTML的样式了:
<br>不就是一个换行标签嘛!<b>不就是一个加粗样式嘛!
所以您可以理解为:这个文本是在XML基础上包含了HTML样式。
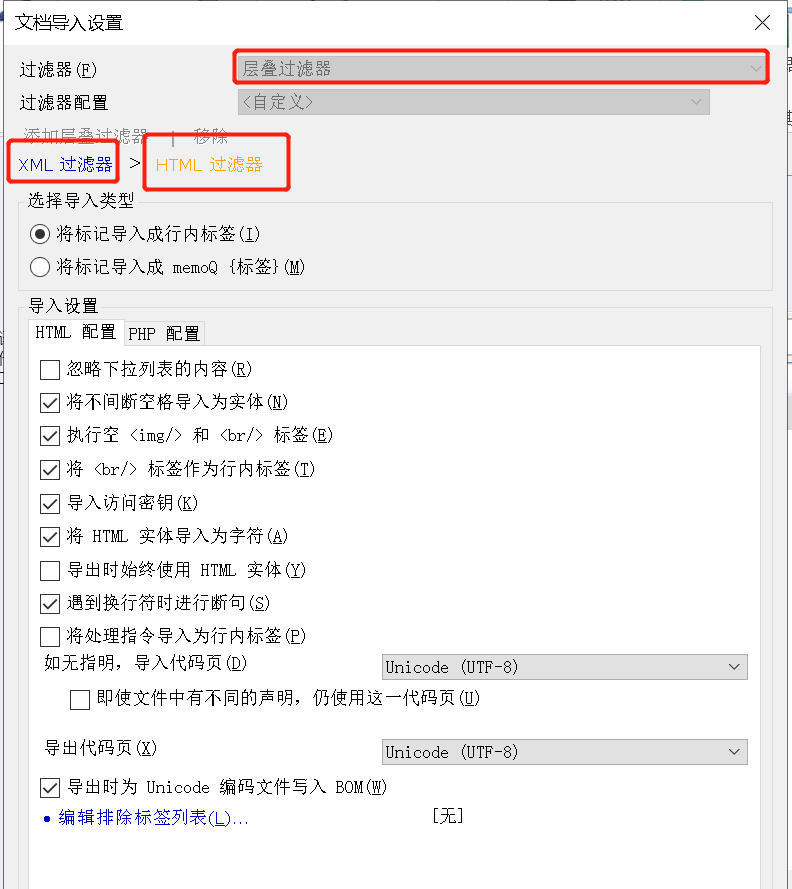
那就简单了,您可以用层叠过滤器解决。
关于层叠过滤器,您可以查看帮助文档:https://docs.memoq.com/current/en/Places/create-new-filter-cascading.html?Highlight=cascading%20filter
我们以后也会再讲,慢慢涨知识
- 既然是XML文档,所以我们第一层过滤器还用XML过滤器;
- 既然包含HTML样式,所以我们叠加一层HTML过滤器。
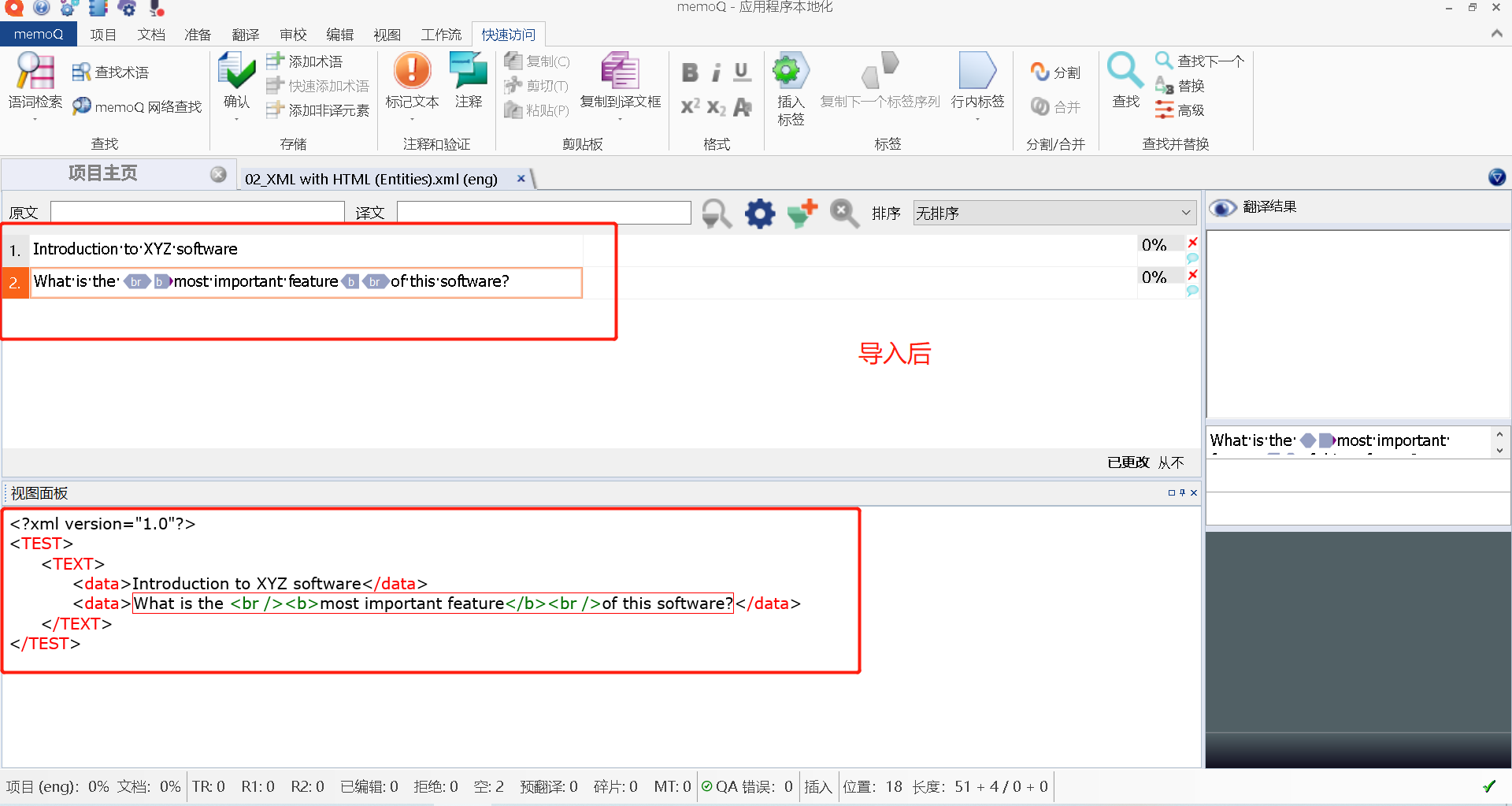
重新导入后,就OK啦!
该变为标签的也变为标签了
这样就不用担心出现字符串误译或者丢失的问题了
操作视频
二、翻译包含HTML样式的XML文档(CDATA篇)
在这一部分我会讲另一种XML 中包含 HTML 的文本,也就是包含 CDATA 的文档。
包含CDATA的XML也是应用程序本地化中常遇到的一种文档格式。
我们先来看它长什么样子:

我们发现它是符合 XML 标准的:
- 第一行说明语句:
<?xml version="1.0" standalone="no"?> - 第二行和最后一行根元素:
<doc> - 中间有
<para>是<doc>的子元素。
但是也有点不一样,就是多了一些<![CDATA[...]]的东西。
这就是 CDADA 文档。
那么它到底是个什么,又该如何翻译呢?
2.1 什么是 CDADA?
我们知道,计算机在读取编程文件的时候,是一行一行来读的。
我用前面的 XML 文档为例。
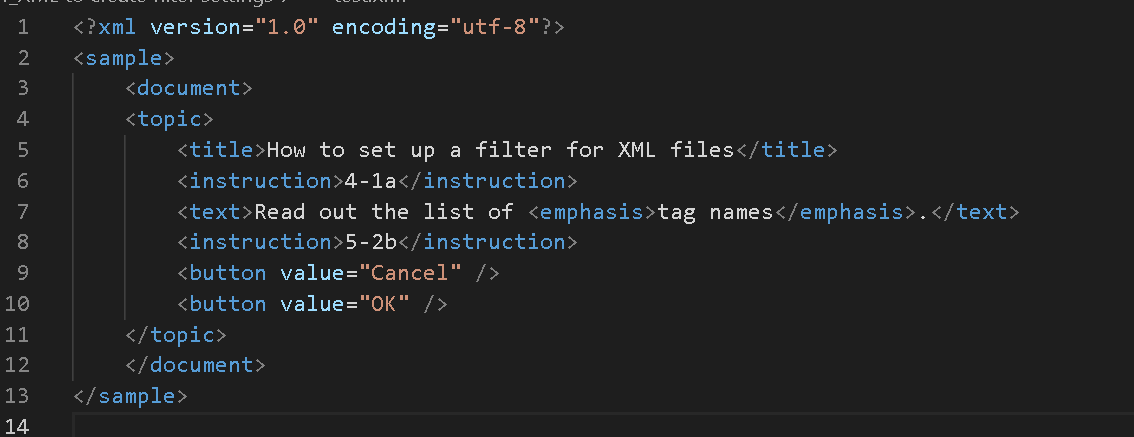
计算机就会先读取第一行:<?xml version...?>,然后计算机就知道了:“哦,原来是个xml文档,要识别为XML文档~”。
然后继续往下读<sample>,“哦,是个示例呀~”。
可是如果遇到走不通的地方,计算机读不懂,就会提示您:“哎呀,出错惹,我读不懂啊”。(这就是我们经常说的报错。)
可是为什么会有报错呢?可能的原因有:
- 代码逻辑有问题。或者
- 这是个XML文档,您写的不是XML样式,所以您跟它说,它确实读不懂。(
如果是代码有问题,您可以自行检查并解决
第二个原因,怎么解决呢?
- 改成它能懂得语言;——比如我们前面讲的改为实体,如果
'读不懂,就改为' - 既然读不懂,就别难为计算机了——比如通过 CDATA 就是一种解决方法。
怎么解决呢?我们先来看看 CDATA 是什么。
CDATA 的全名是character data。
在 XML 文档中,文本均会被计算机读取和解析,但是被 CDATA 包起来的文本除外。
比如某些代码,包含像 < 、 > 、& 等字符,我们可以将其定义为 CDATA,这样计算机就不会读这部分内容,也就会减少出错了。
CDATA 部分由<![CDATA[" 开始,由 "]]>结束:
我们还是以本文开篇的 CDATA 文档为例,这次我们用 Chrome 打开看一下。

我们发现,由 CDATA 包起来的内容是没有读取的
但我们其实想要的结果是:
不管是什么Java XML HTML 语言,都是要读的,也还是要翻译的。
那么遇到 CDATA 该怎么翻译呢?
2.2 如何翻译包含CDATA 的XML?
我们先看源文档:
其实不是不能读,是不能用 XML 读了。要用它支持的语言读。
所以:
如果要翻译出 CDATA 的部分,必须要知道 CDATA 包起来的部分是什么。
在这个例子中,我们发现,其实被 CDADA 包起来的内容是 HTML 样式,像<p>、<b>都是,当然也有实体,像&amul;、ö。

所以还是用层叠过滤器:
- 既然是XML文档,那第一层过滤器还是用 XML 过滤器;
- 既然 CDATA 部分是 HTML 样式,那第二层我们就用HTML 过滤器。
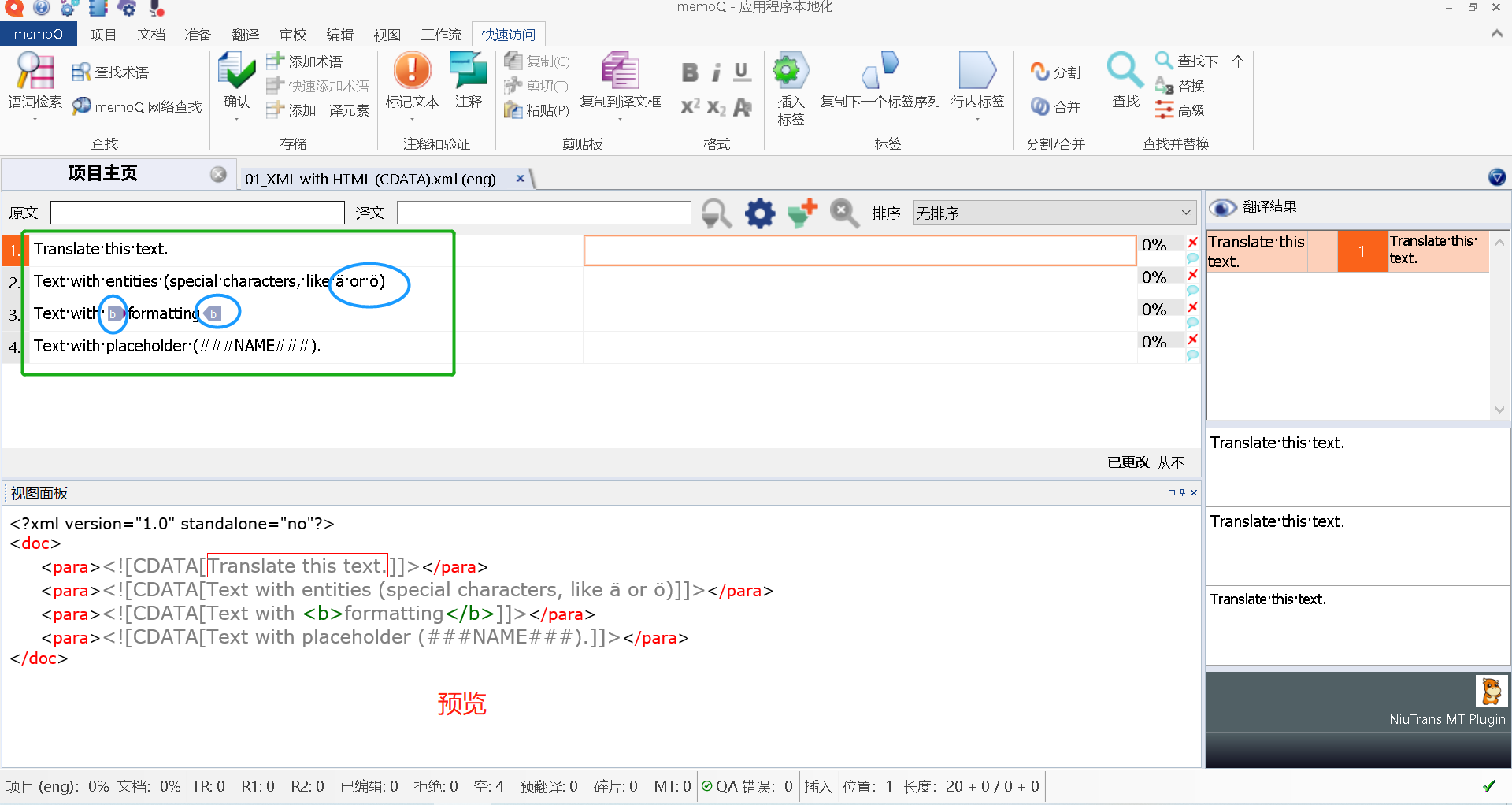
- 继续加过滤器,加一层正则表达式标注器,标记为标签。该是段落识别为段落,该是标签识别为标签,该是特殊字符的还原特殊字符
记得怎么用正则标注标签吗?不记得看这里回顾:正则篇(六):用正则将文本标记为标签
操作视频
三、翻译含有DTD样式的XML文档
有时候,我们也会收到这样的文件包:文件包里既有xml文档,又有一个dtd文档。
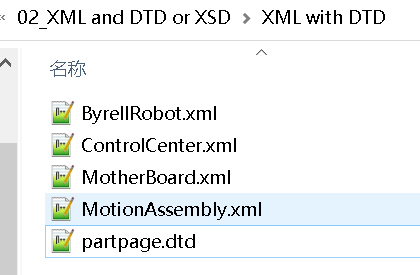
如果打开其中一个XML文档,是长这样的:
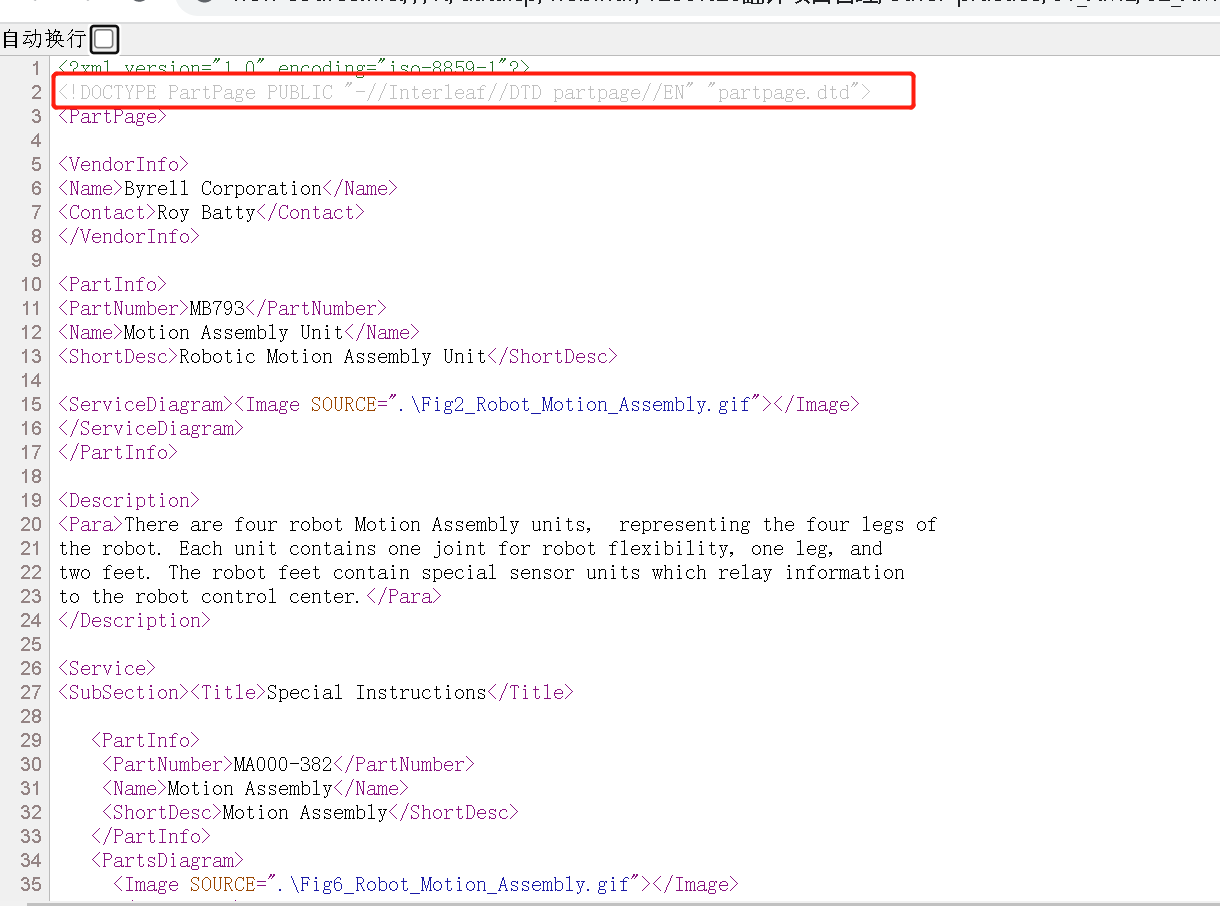
您会发现:似乎和图1的XML不一样
这个文档多了第二行:
<!DOCTYPE PartPage PUBLIC "-//Interleaf//DTD partpage//EN" "partpage.dtd">
——其实,这是DOCTYPE 声明的内容,用来告诉您:“这是这个文档类型是一个PartPage,引用的是外部的partpage.dtd文档”。
您也会发现:这个第二行的最后”partpage.dtd”不就是文件包中的后缀名为*.dtd的partpage.dtd文档嘛!
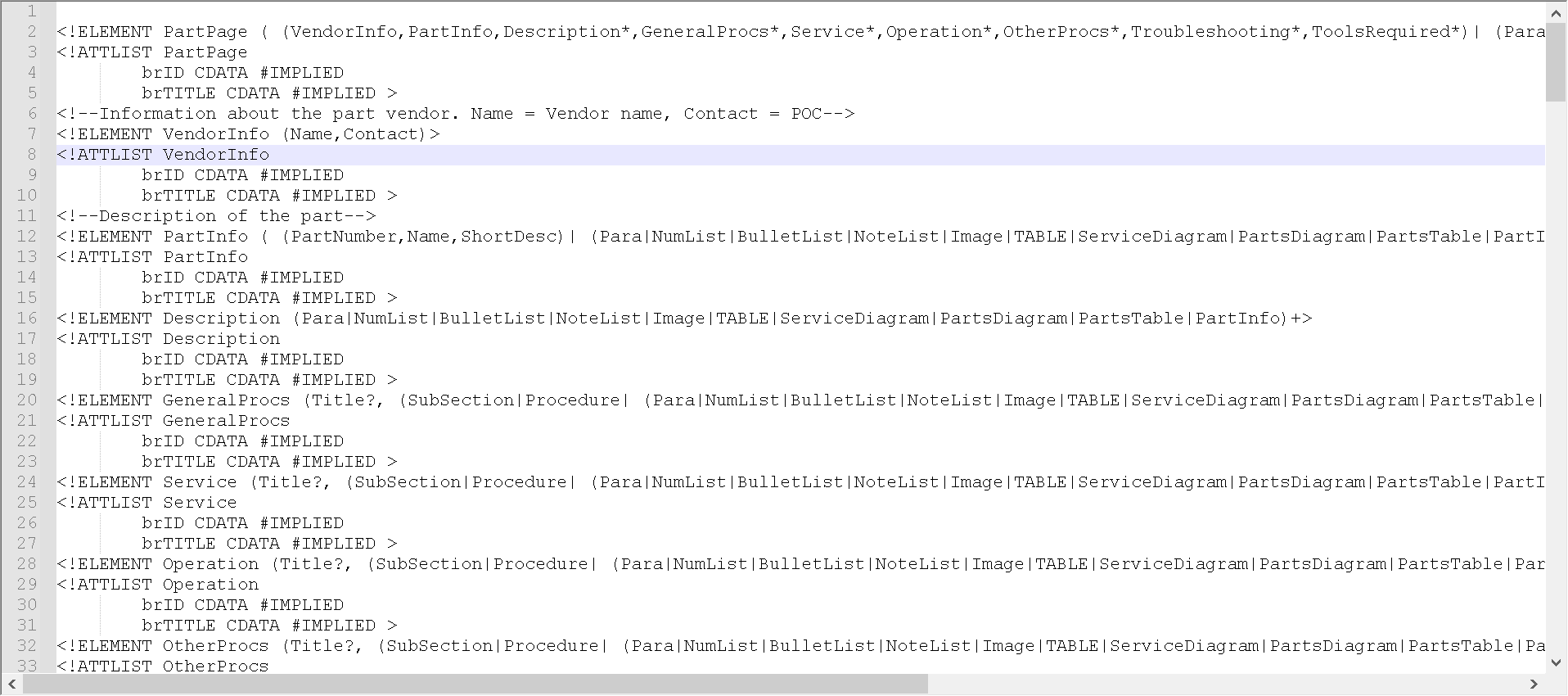
是的!如果您打开这份*.dtd文档(其实这就是一个ASCII的文本文件)——也就是包含 DTD 的 “partpage.dtd” 文件,长这样:
这就是含有DTD的XML文档,那,DTD是什么?
3.1 认识DTD
3.1.1 定义
DTD 是英文Document Type Definition的首字母缩写,中文意思为“文档类型定义”。
通过DTD我们可以验证XML是“合法”,也就是说:验证您的XML文档结构是否拥有正确语法,或者您可以理解为是否符合要求。
如果您不想知道这是什么,也可以直接往下划,直接看如何翻译含有DTD的XML,找到方法论。
那么问题来了:正确语法是什么?或者说:要求是什么?
3.1.2 DTD构成
首先,在原XML中已经声明了:<!DOCTYPE PartPage PUBLIC "-//Interleaf//DTD partpage//EN" "partpage.dtd">,您可以理解为自我介绍:
“我引入partpage文档;”

我们看一下DTD的这个构成:
3.1.2.1 元素
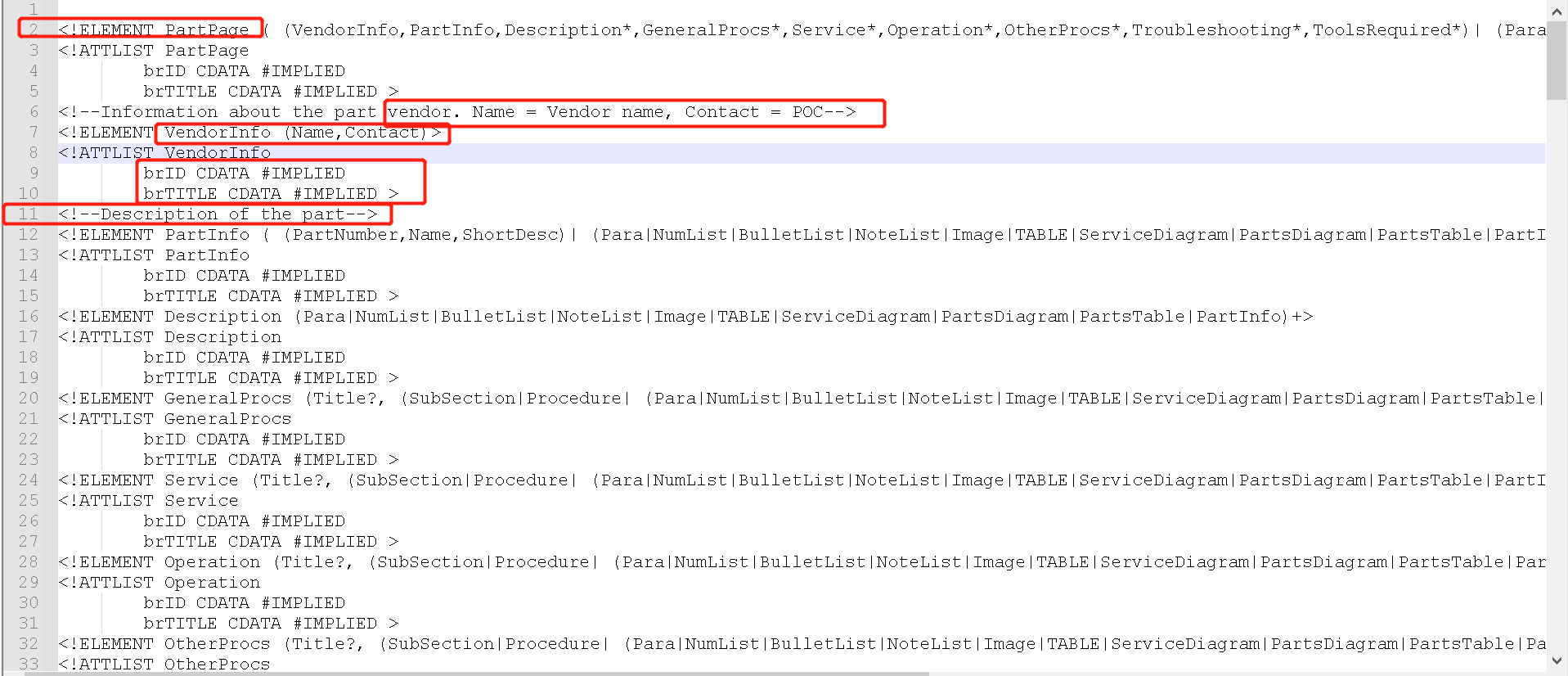
在 DTD 中,元素通过ELEMENT来进行声明。语法如下:
<!ELEMENT 元素名称 (元素内容)>
所以我们看第2行,说明了:
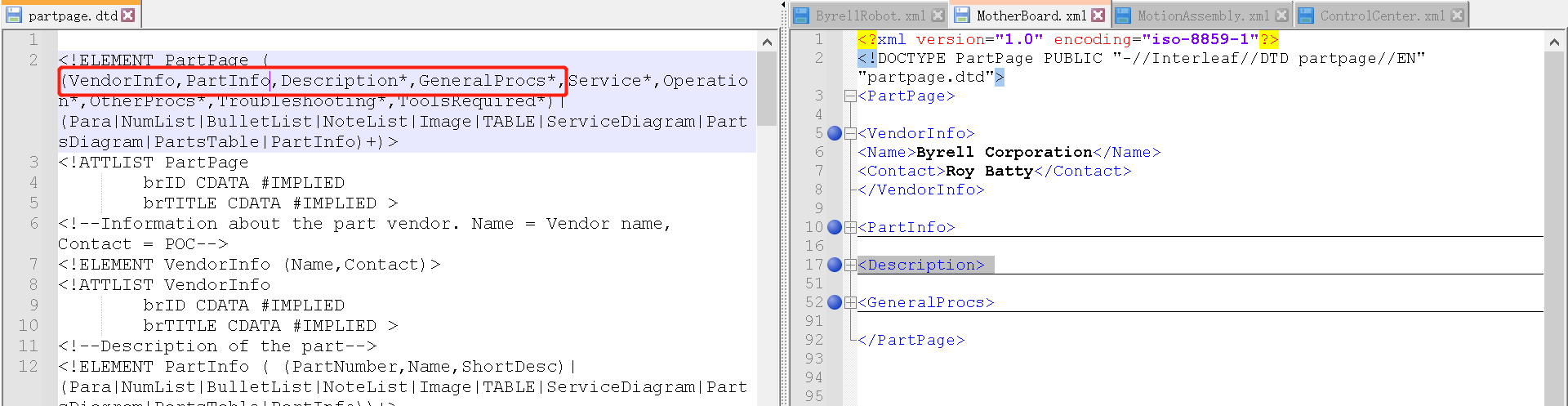
根元素PartPage元素应该包含哪几个子元素,这里有VendorInfo、PartInfo、Description、Service等。
所以您会发现,在右侧的正文XML中就是按照这几个元素及关系在定义的。
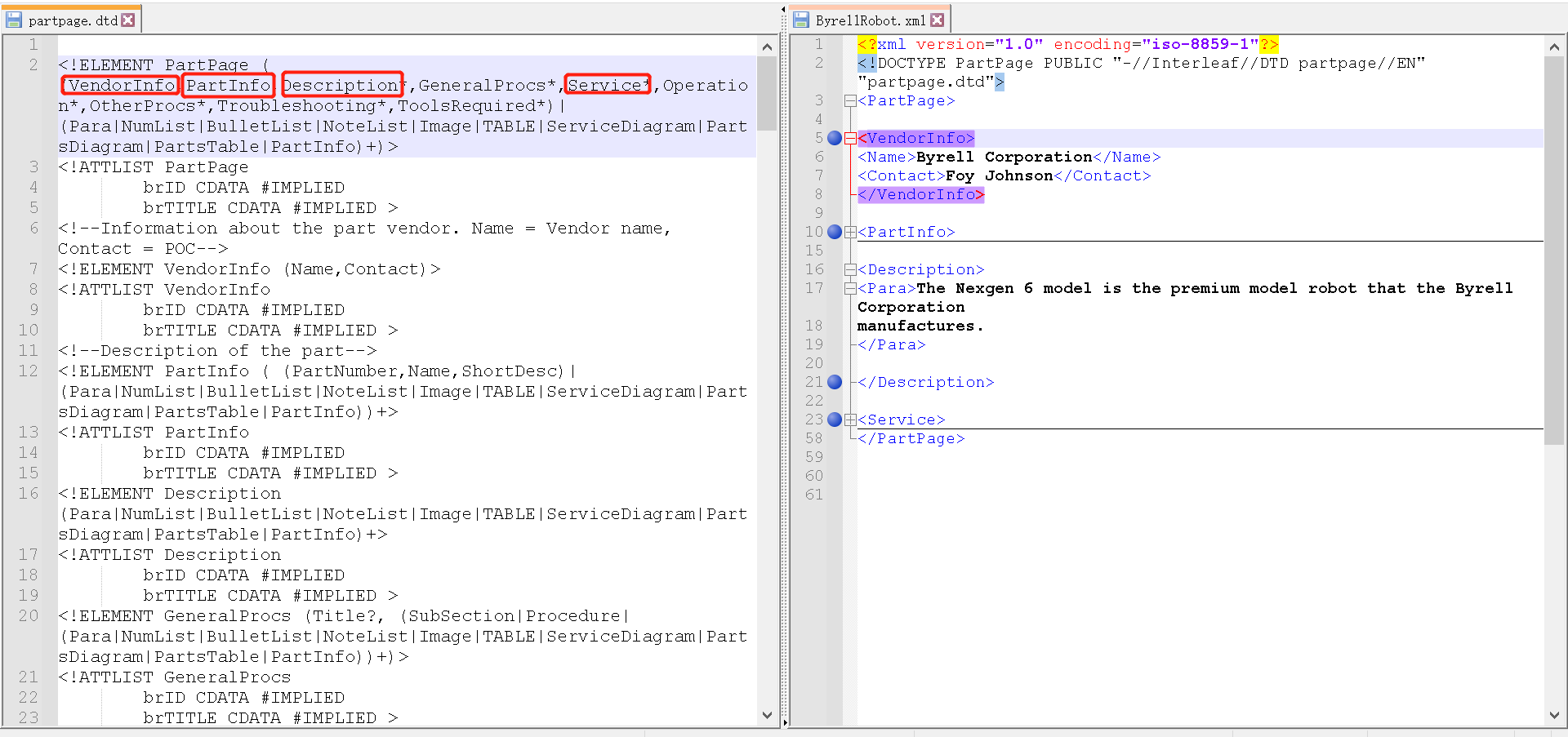
再比如第7行就定义了:父元素<VendorInfo>应该包含Name、Contact两个子元素。
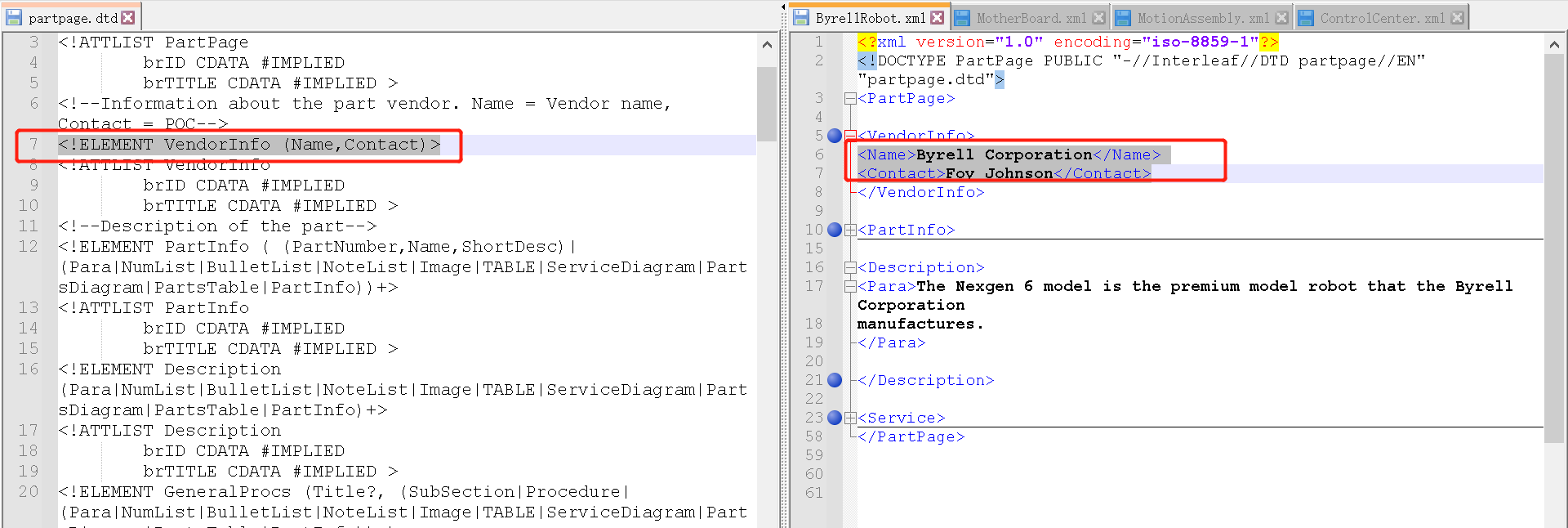
那元素名右上角的星号(*)、加号(+)号等等是什么意思呢?
类似我们前面讲的正则的符号表示,详见:常规XML文档的翻译与本地化:
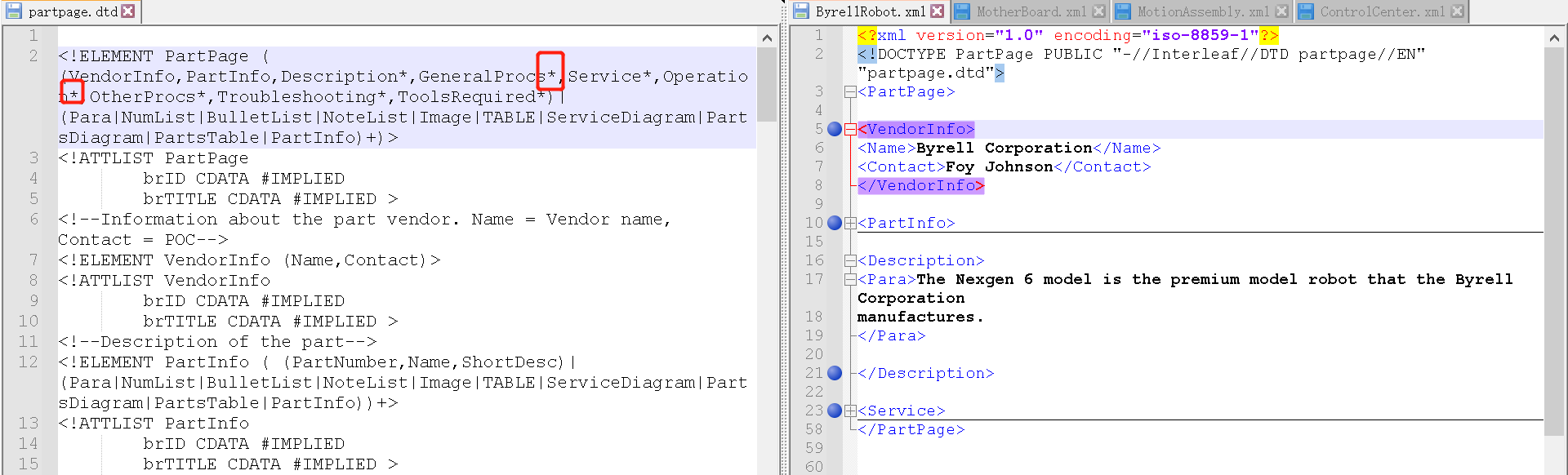
- 星号(*)表示该元素出现零次或多次。
- 理解了星号,加号就很容易理解了:加号(+)表示该元素至少出现一次,也就是一次或多次。
所以,在上图中,右侧的XML文件有VendorInfo、PartInfo、Description、Service元素,但是没有<GeneralProcs>或者<Operation>等元素。
但是我们在右图,在右侧的XML中就有了<GeneralProcs>元素,但是却没有Service元素。
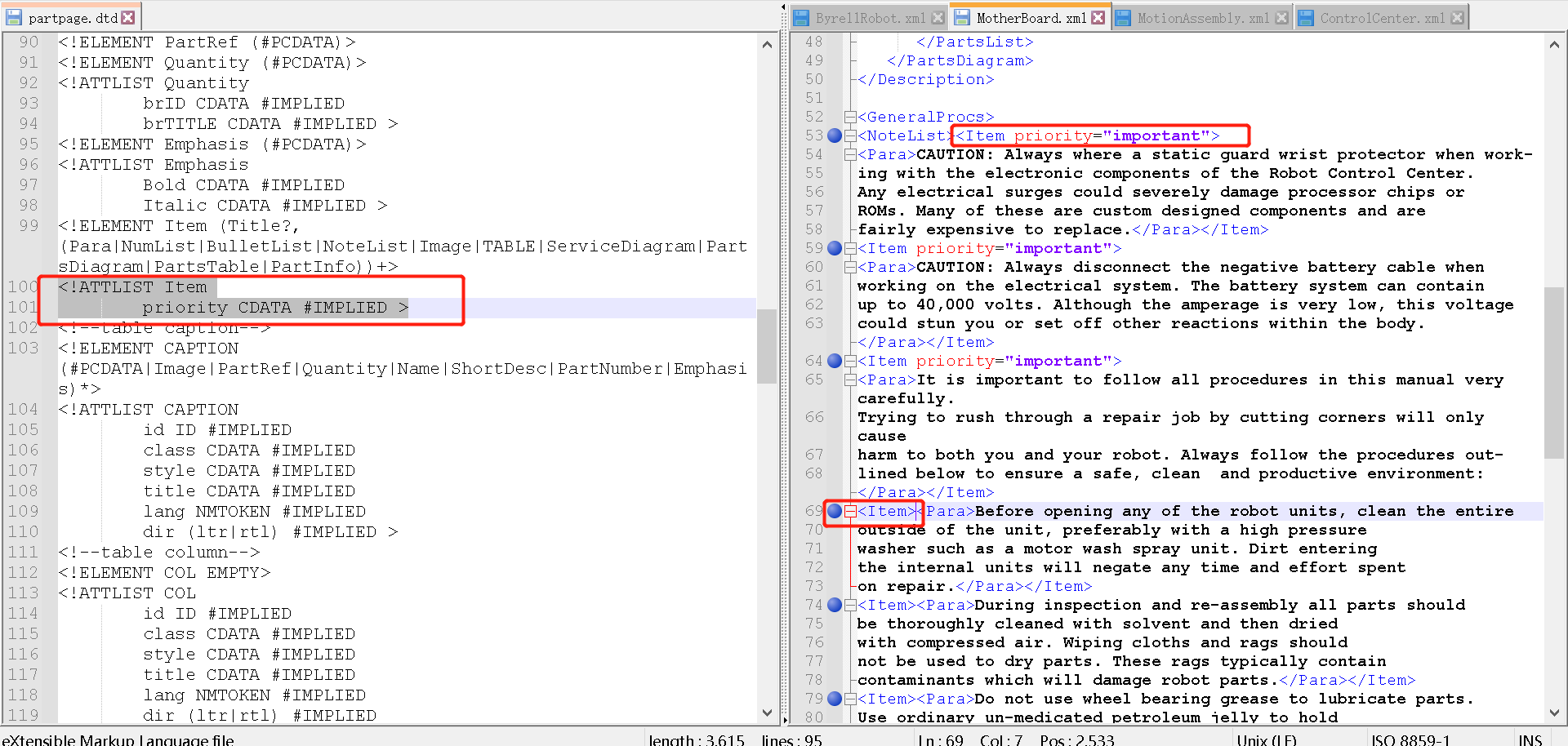
3.1.2.2 属性
在 DTD 中,属性通过 ATTLIST 声明来进行声明。语法如下:
<!ATTLIST 元素名称 属性名称 属性类型 默认值>
比如这里的第100行:
- Item元素包含了 priority 属性
<priority>属性类型是CDATA。关于CDATA,参见:翻译包含HTML样式的XML文档 (CDATA篇)- 该元素默认值
#IMPLIED,表示priority 属性不是必需的。所以第53行的Item有priority属性,但是像69行、74行、79行就没有priority属性。
3.1.2.3 实体
前面我们讲过XML的实体,详见:翻译包含HTML样式的XML文档(实体篇)。
在 DTD 中,实体通过 ENTITY 来进行声明:<!ENTITY 实体名称 "实体的值">,或者<!ENTITY 实体名称 SYSTEM "URI/URL">。
因为这个文档中没有,所以我不介绍了,大家需要的话去网络上查找
3.2 如何翻译含有DTD样式的XML文档?
在翻译包含DTD的XML时,可以有2步:
- 检查翻译包
- 配置及测试过滤器
3.2.1 翻译包检查
在正式启动翻译之前,您需要检查源文档和翻译包。
您需要检查:
1、发送过来的翻译包是单个文档还是多个文件的翻译包;如果是多个文档的翻译包,哪几个文档需要翻译?
比如这个翻译包:文件包里有4个xml文档,以及一个dtd文档。
2、检查需要翻译的XML文档,看一下源文XML文档是否有外部引用;
比如,下图中就包含了一个”partpage”的dtd引用。
3、如果XML中有有外部引用,对比翻译包中的引用文档是否和声明中的引用一致。
在本案例中,根据上面两张图,发现翻译包中的引用文档和声明中的引用是一致的。
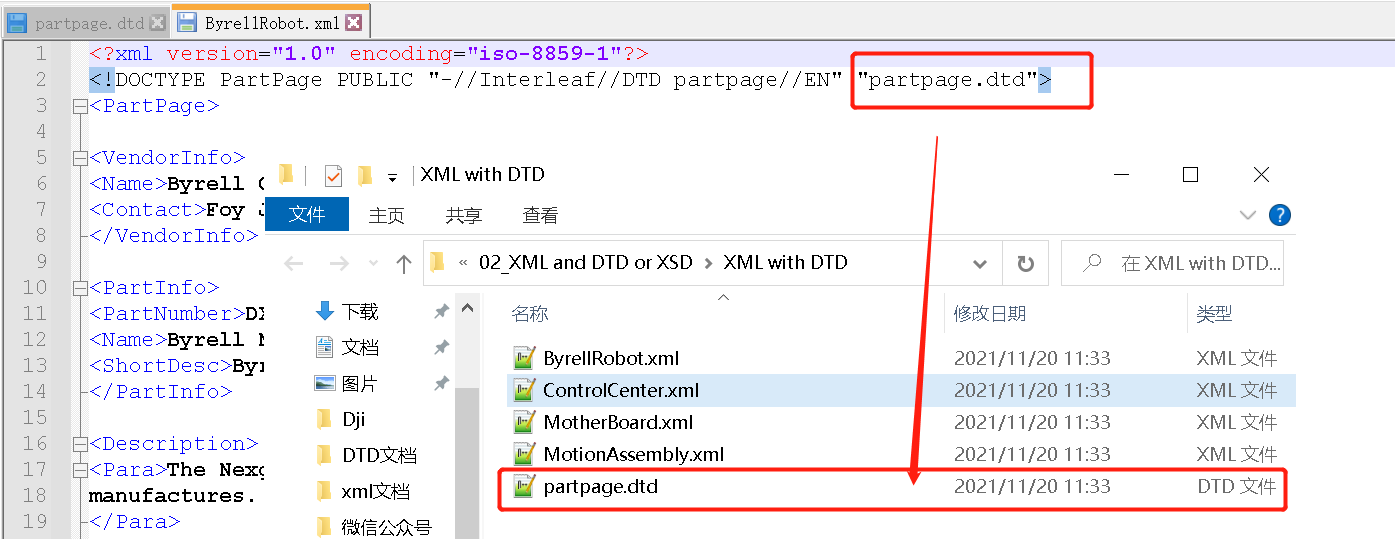
既然收到的翻译包没有明显的错误,那我们导入memoQ进行翻译
我们前面一直讲:导入翻译文档,需要设置正确的过滤器。
那么,包含DTD的XML文档应该如何配置呢?
3.2.2 为包含DTD的XML配置过滤器
当然,在CAT中,过滤器也可以叫解析器。都一样~
配置过滤器有三个步骤:
- 选择正确的过滤器
- 配置过滤器
- 检查过滤器。
3.2.2.1 选择正确的过滤器
既然是XML文档,那么我们就用XML过滤器即可。
所以在导入时,选择:导入 -> 找到需要翻译的4个XML文档 ->选择 XML 过滤器,如图所示。
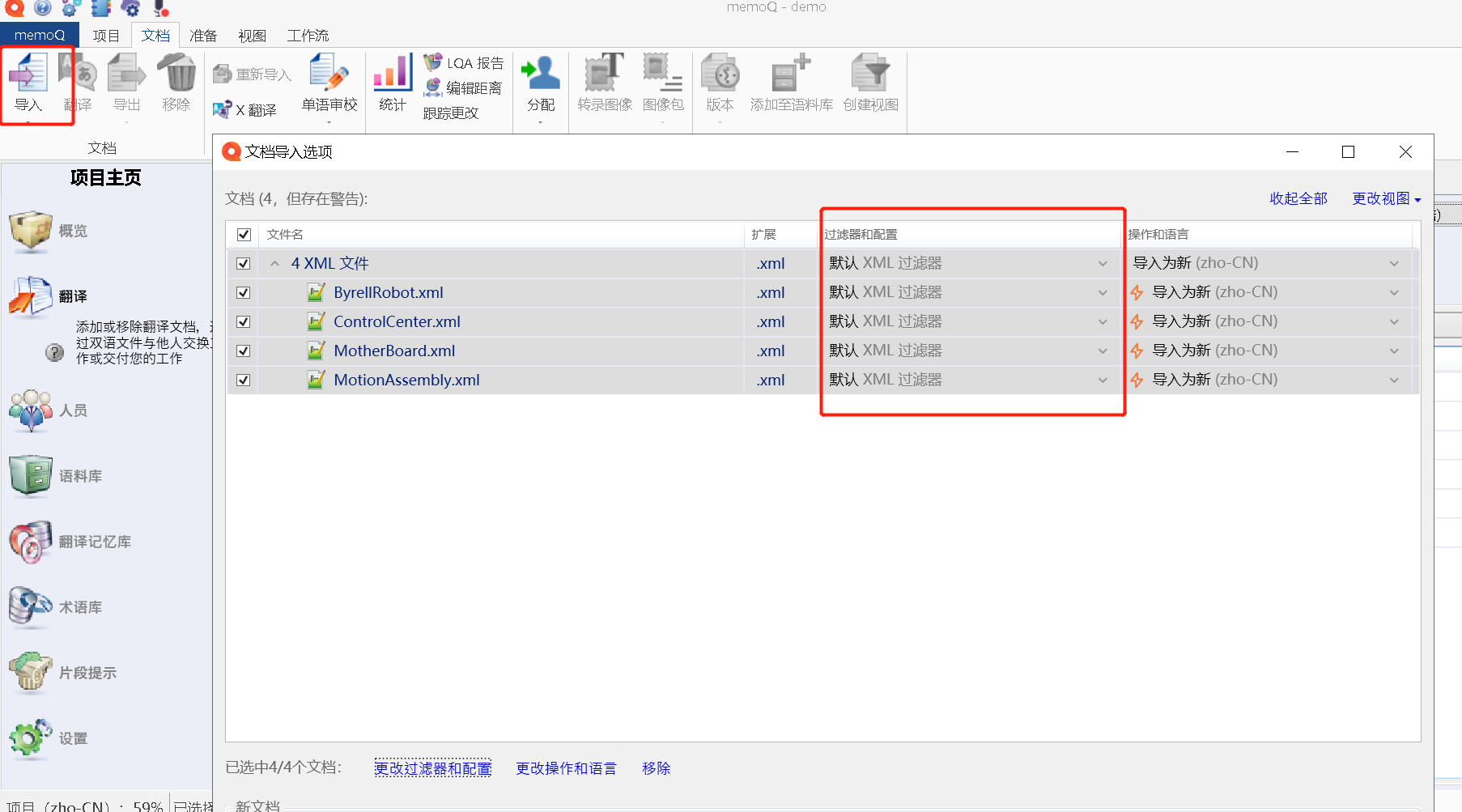
3.2.2.2 配置过滤器
默认的过滤器不能满足我们的需要,所以我们可以更改过滤器配置。
操作如下:
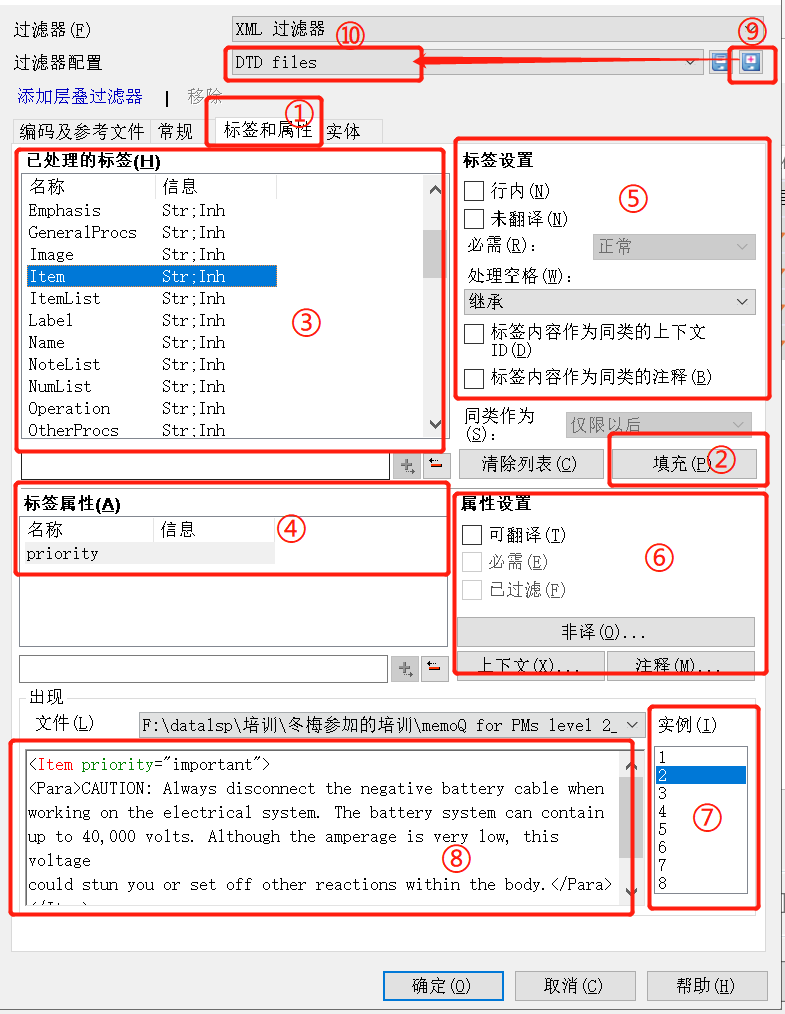
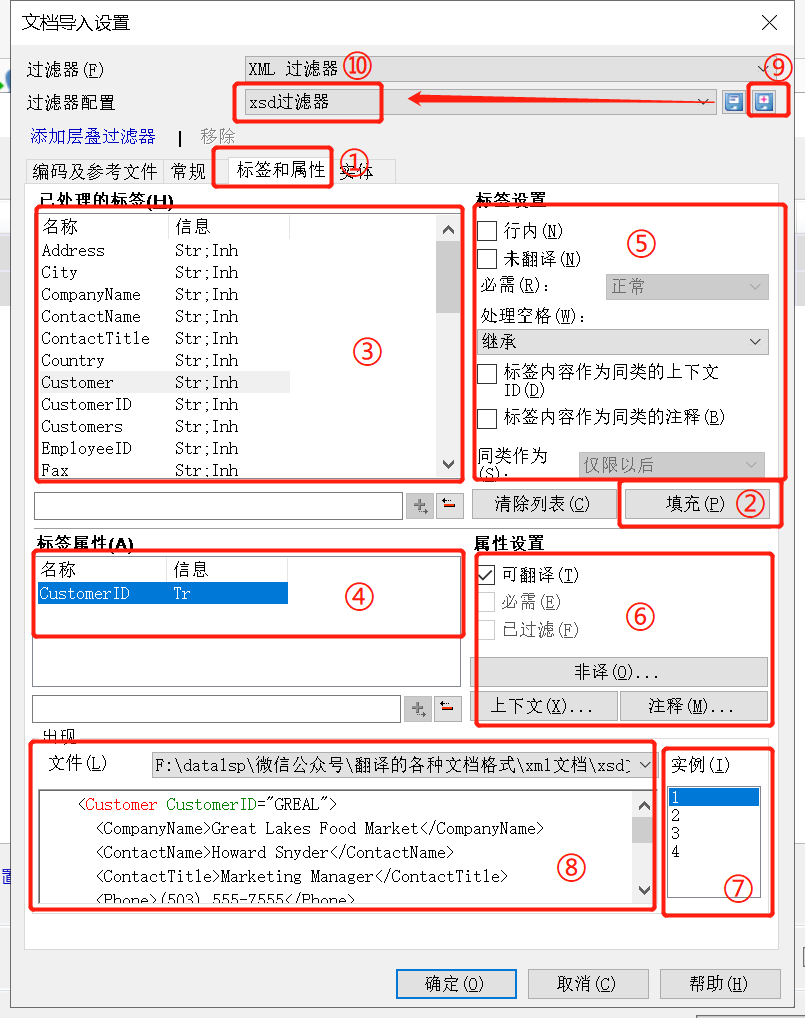
1、在文档导入选项 -> 点击“更改过滤器配置” -> 跳转出“文档导入设置”窗口;
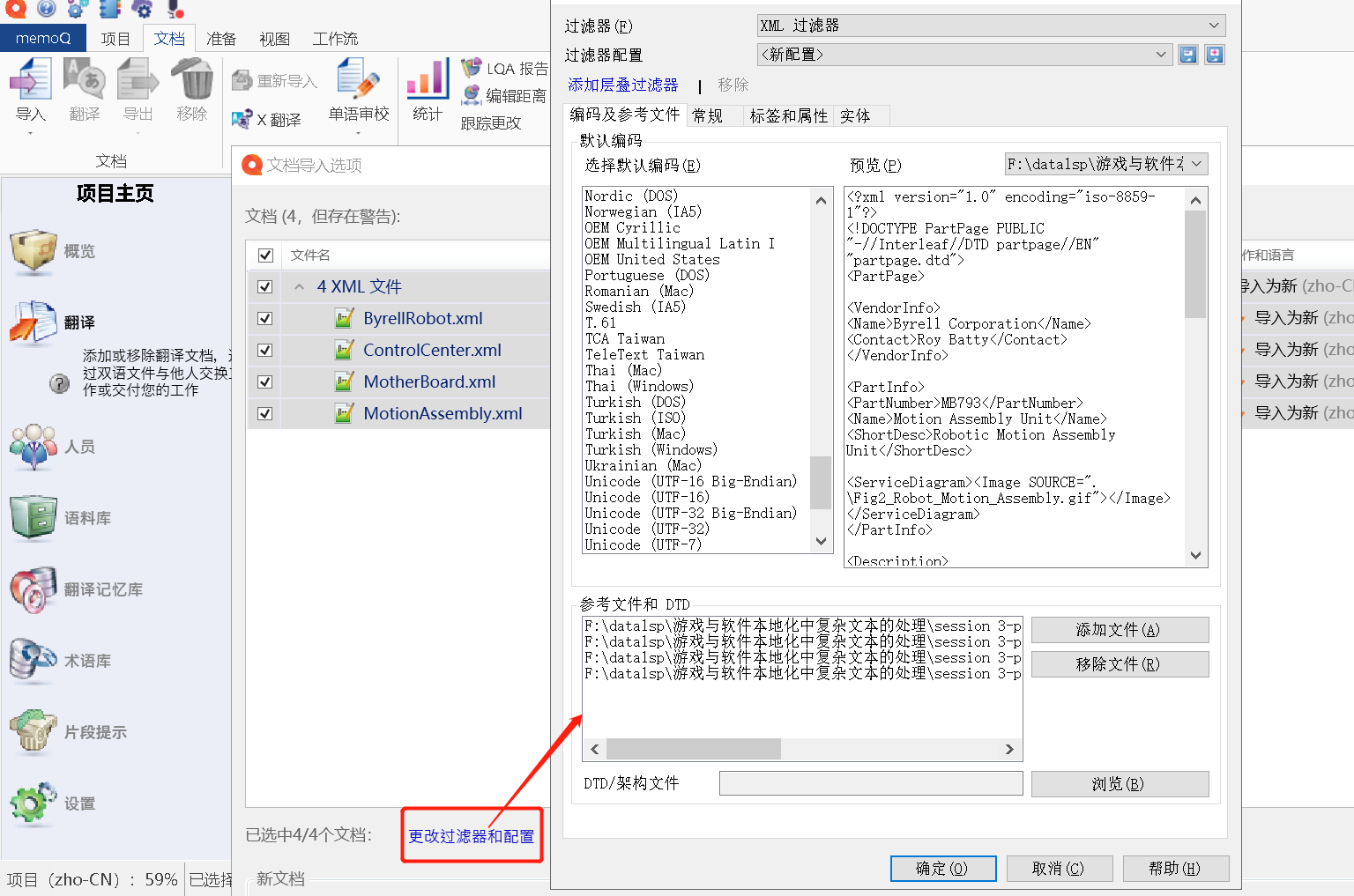
2、在“文档导入设置”窗口 -> 点击“DTD/架构文件”的“浏览” -> 选择正确的dtd文档;
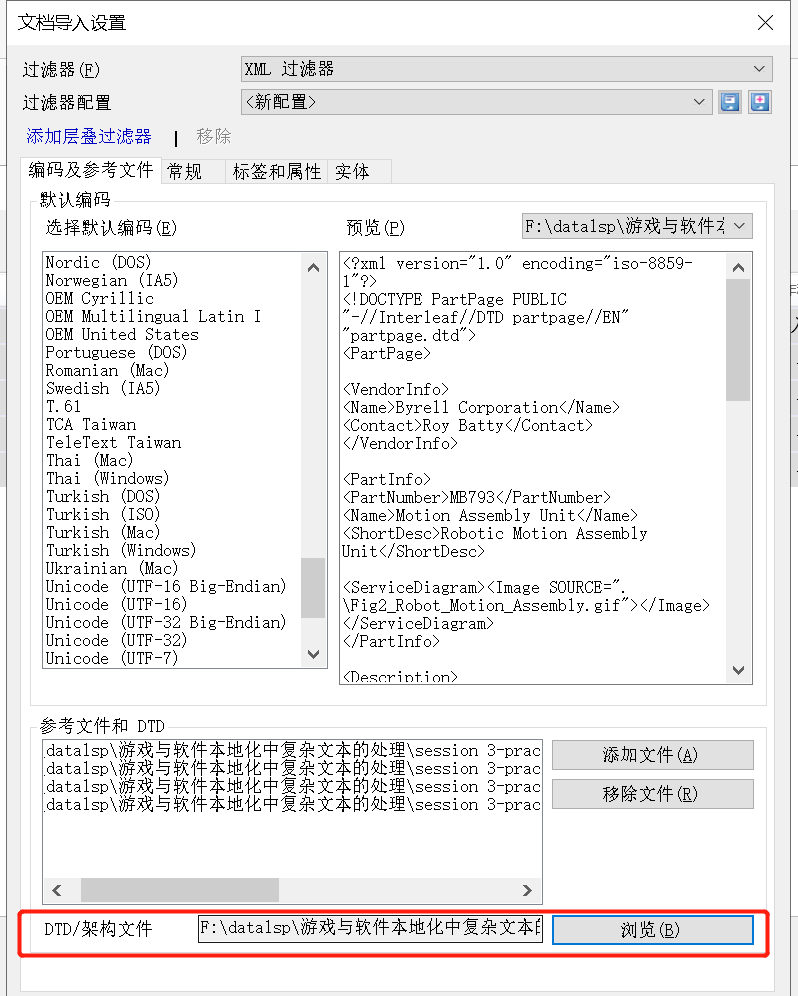
3、点击“①标签和属性” -> 配置XML过滤器。具体如下:
- 点击 “②填充” -> 自动填充 ③标签 和 ④标签属性
- 在 ⑤标签设置” -> 设置哪些标签需要翻译、哪些标签属于行内标签
- 在 ⑥属性设置” -> 设置哪些标签属性需要翻译、哪些标签属于非译元素或上下文等条件
- 可以参考 ⑦实例 为每一个 ③标签 和 ④标签属性单独设置不同条件
- 还可以在 ⑧预览区预览实际文件内容
- 您还可以点击 ⑨保存过滤器,保存并 ⑩重命名一个新的过滤器,供下次使用。
更多关于XML翻译的解析器设置,请参考:常规XML文档的翻译与本地化-如何翻译单语XML文档?
4、过滤器配置完成后,点击确定即可导入翻译文档
3.2.2.3 检查过滤器
按照配置过滤器的操作,导入后如图所示:
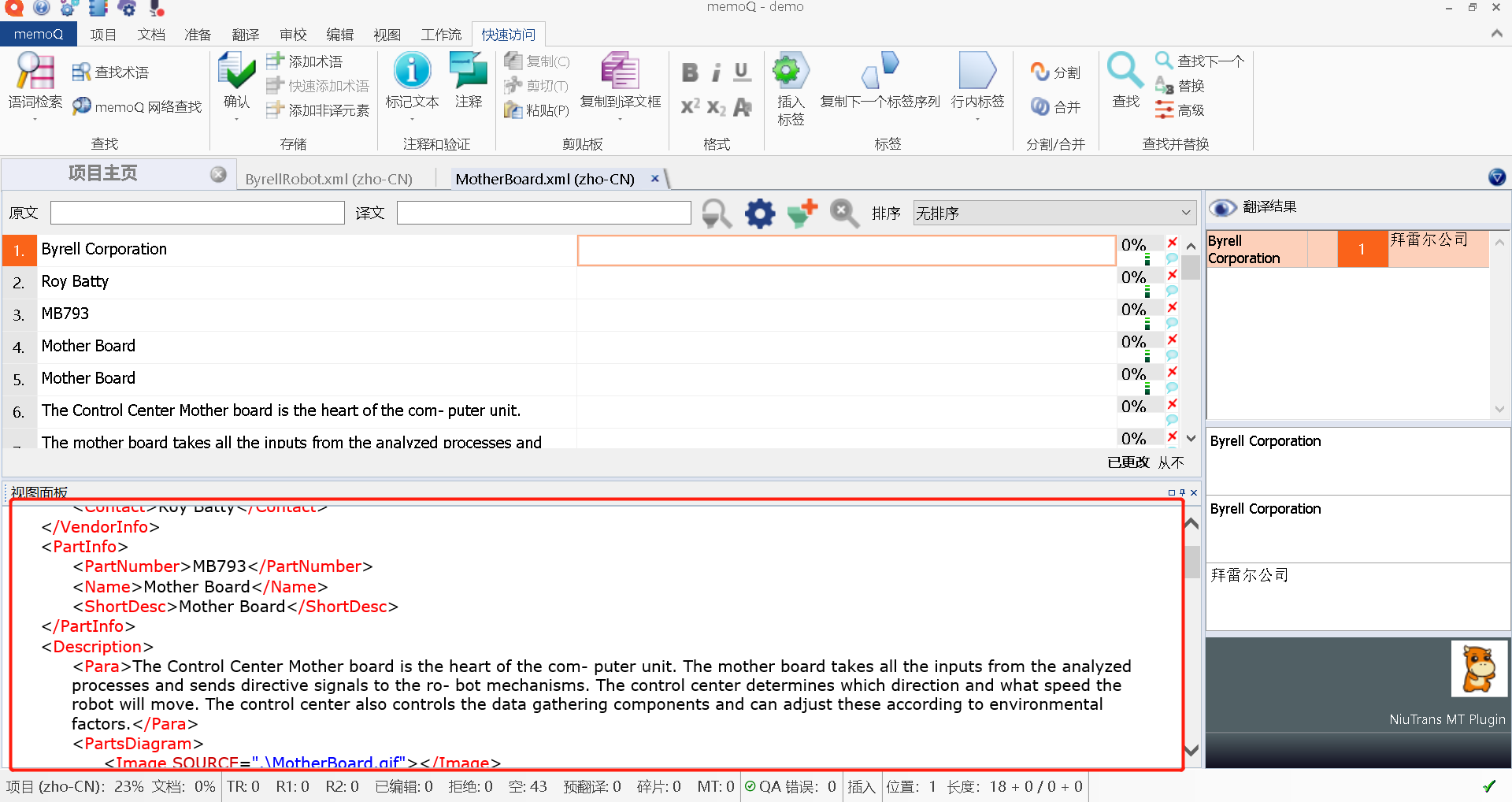
为了保障译文的格式准确性,我们要测试,看一下译文是否可以按照目标语言顺利导出
比如在这里,您可以借助小牛机器翻译,利用MT进行预翻译。
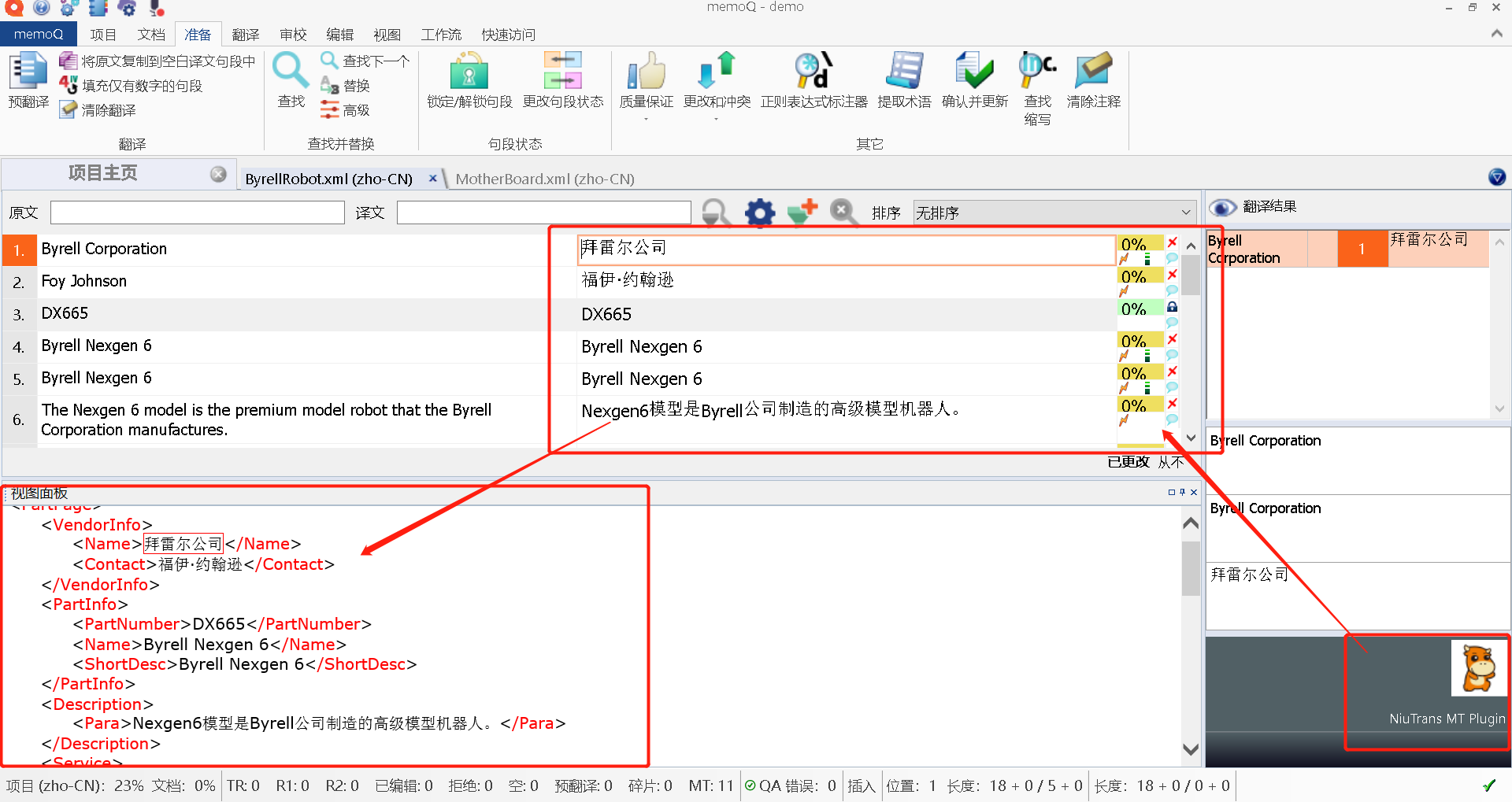
并把MT的译文导出检查一下~如果导出后的译文如图所示,可以顺利显示,就说明是成功的:
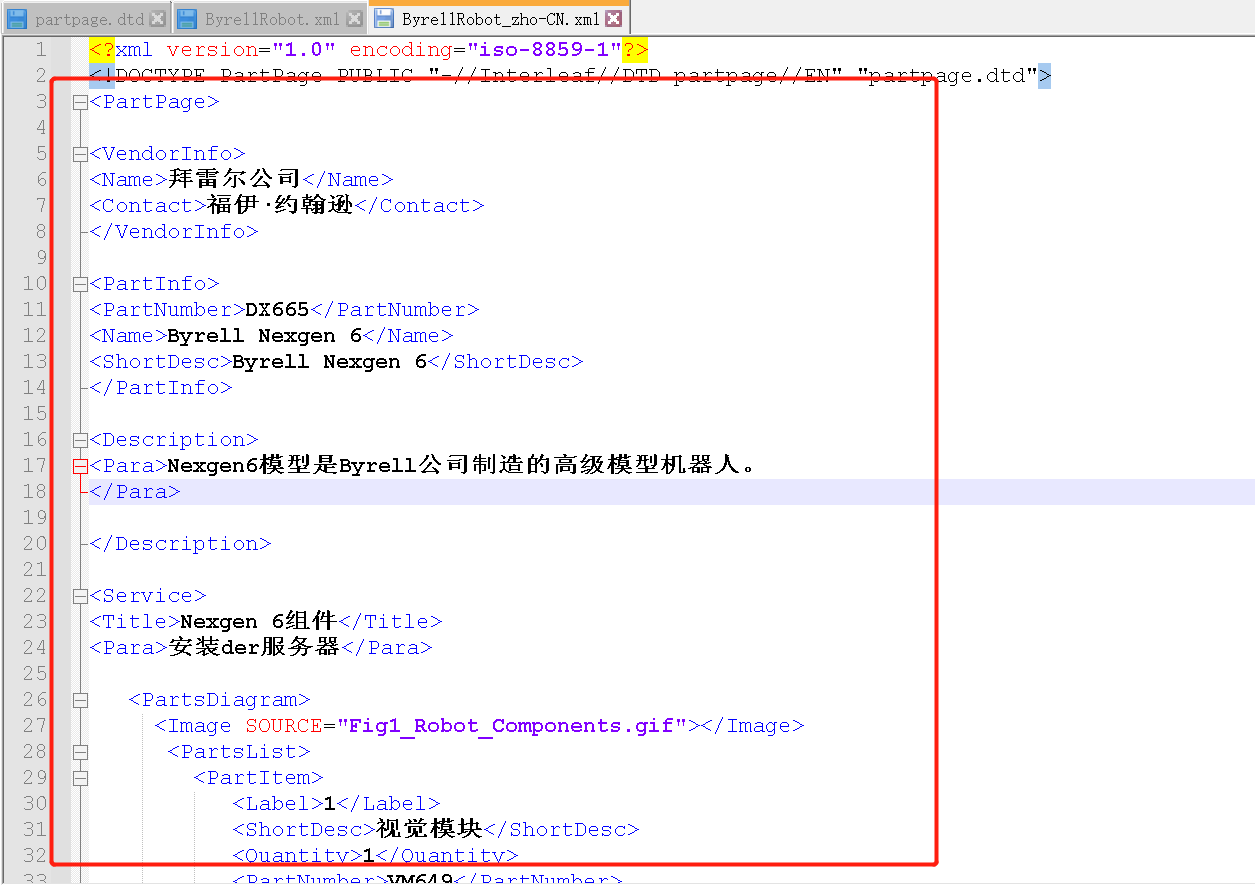
如果没问题,那就可以正式启动翻译了
更多关于memoQ翻译的操作,详见:memoQ入门指南。
操作视频
四、翻译XSD文档
4.1 认识XSD文档
XML Schema Definition(XSD),也是定义 XML 文档的合法构建模块,非常类似 XSD,也是应用程序本地化中常见的文档。
所以,我们来简单了解一下XML Schema Definition(XSD)。
在看本文前,请确保您已经:
4.1.1 XSD定义
XML Schema 的作用是定义 XML 文档的合法构建模块。
其实真的定义跟XSD也差不多~
通过XSD我们可以验证XML是“合法”,同理,我们通过xsd也是为了验证XML是否“合法”。
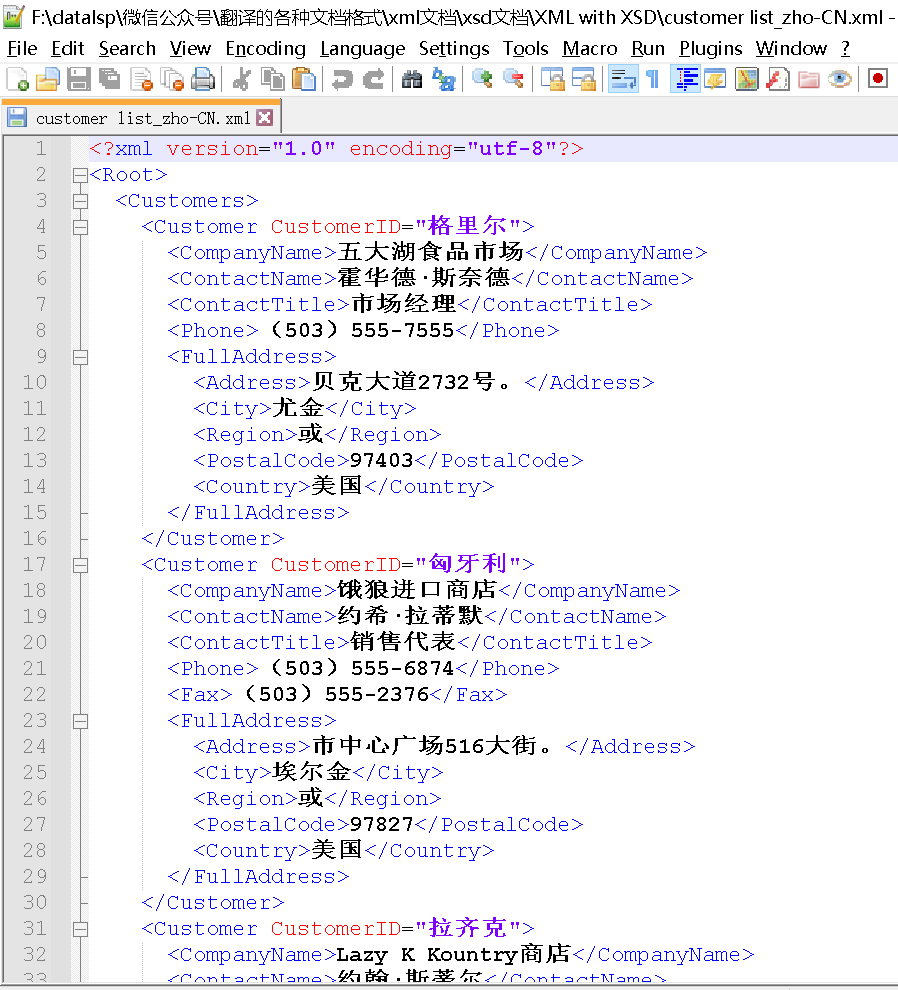
在这里我用一个翻译包给大家看一下:
文件包里既有xml文档,又有一个 *.xsd 文档。

打开这两个文档,如图所示。
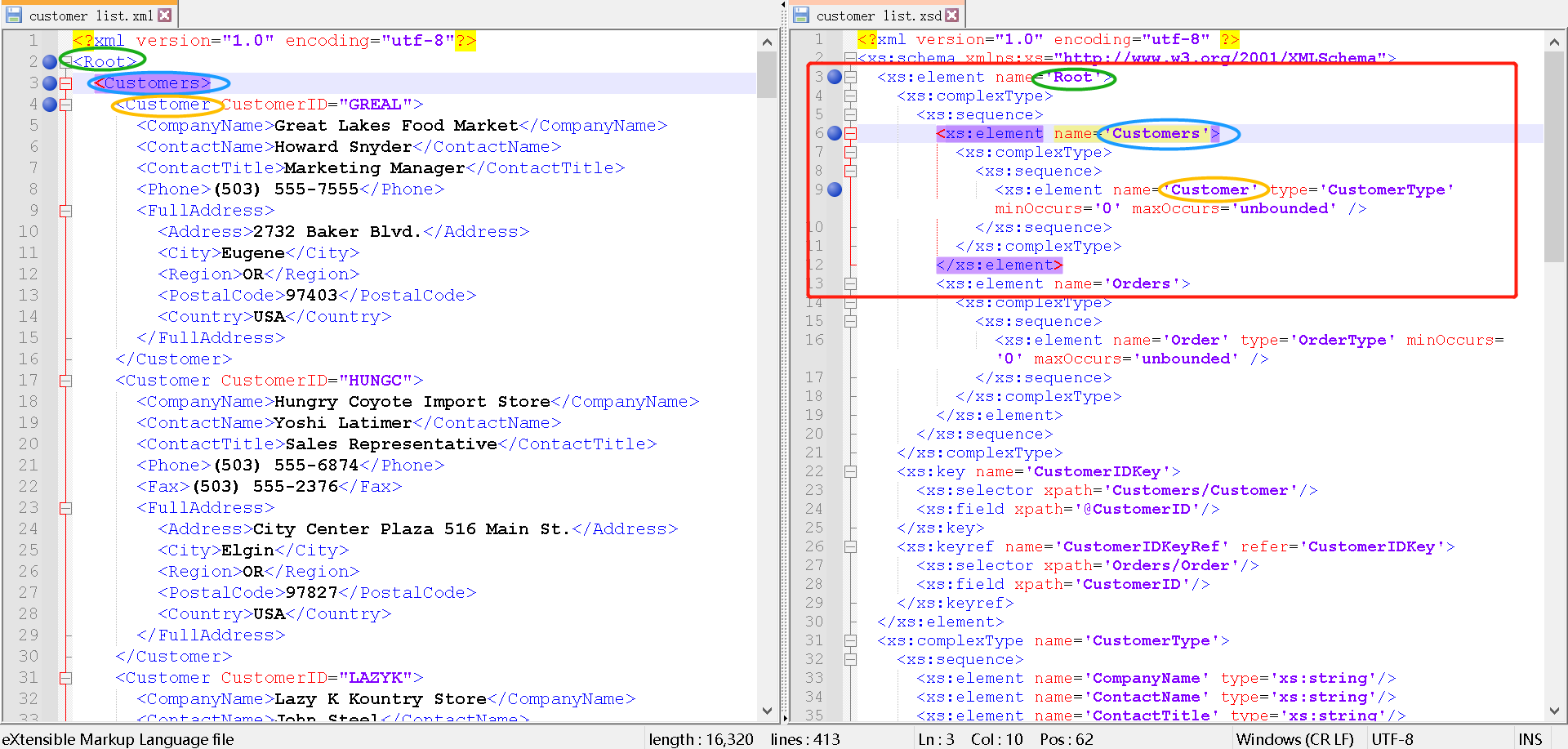
我们发现:
- XML中的元素名就是右侧XSD文档中定义好的,比如:
- XML第2行的根元素
<Root>,是右侧XSD文档第3行的name属性值; - XML第3行的元素
<Customers>,是右侧XSD文档第6行的name属性值; - XML第4行的元素
<Customer>,是右侧XSD文档第9行的name属性值。
- XML第2行的根元素
- 左侧XML的结构是按照右侧XSD定义的,比如:
- 在右侧XSD文档中,第一个根元素
<xs:element>属性值Root,就是左侧的XML的根元素<Root>; - 在右侧XSD文档中,第二行子元素
<xs:element>属性值Customers,就是左侧的XML的<Root>的子元素<Customers>。 - 同理,
<Customer>也是<Customers>的子元素。
- 在右侧XSD文档中,第一个根元素
- 左侧XML元素的数量是按照右侧XSD定义的,比如:
- 在右侧XSD文档中,第九行就说明了XML第4行的元素
<Customer>,是可以出现0次-无数次的。
- 在右侧XSD文档中,第九行就说明了XML第4行的元素
对XML Schema来说,它可以:
- 定义文档中的元素名,元素的属性值
- 定义元素和属性的数据类型
- 定义各个元素的关系,哪个元素是子元素,哪些元素是兄弟元素
- 定义子元素的次序
- 定义子元素的数目等
所以说 XML Schema 比 XSD 更强大,而且据说很快会在大部分网络应用程序中取代 XSD。
4.1.2 XSD构成
如图所示,首先,XSD也是XML文档,所以结构符合XML的文档结构:
- 第一行的
<?xml version="1.0" encoding="utf-8" ?>是声明语句。 - 从第二行开始,
<xs:schema>就是根元素<schema>元素。<schema>元素可包含属性。一个 schema 声明往往看上去类似这样:<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> - 根元素之间还有子元素
<xs:element>、<xs:complexType>等。
我们看一下XSD的构成。

4.1.2.1 元素
在 XSD 中,元素依然是通过element来进行定义。语法如下:
<xs:element name="xxx" type="yyy"/>
其中:
- name的属性值 xxx,指元素名
- type的属性值 yyy,指元素的数据类型
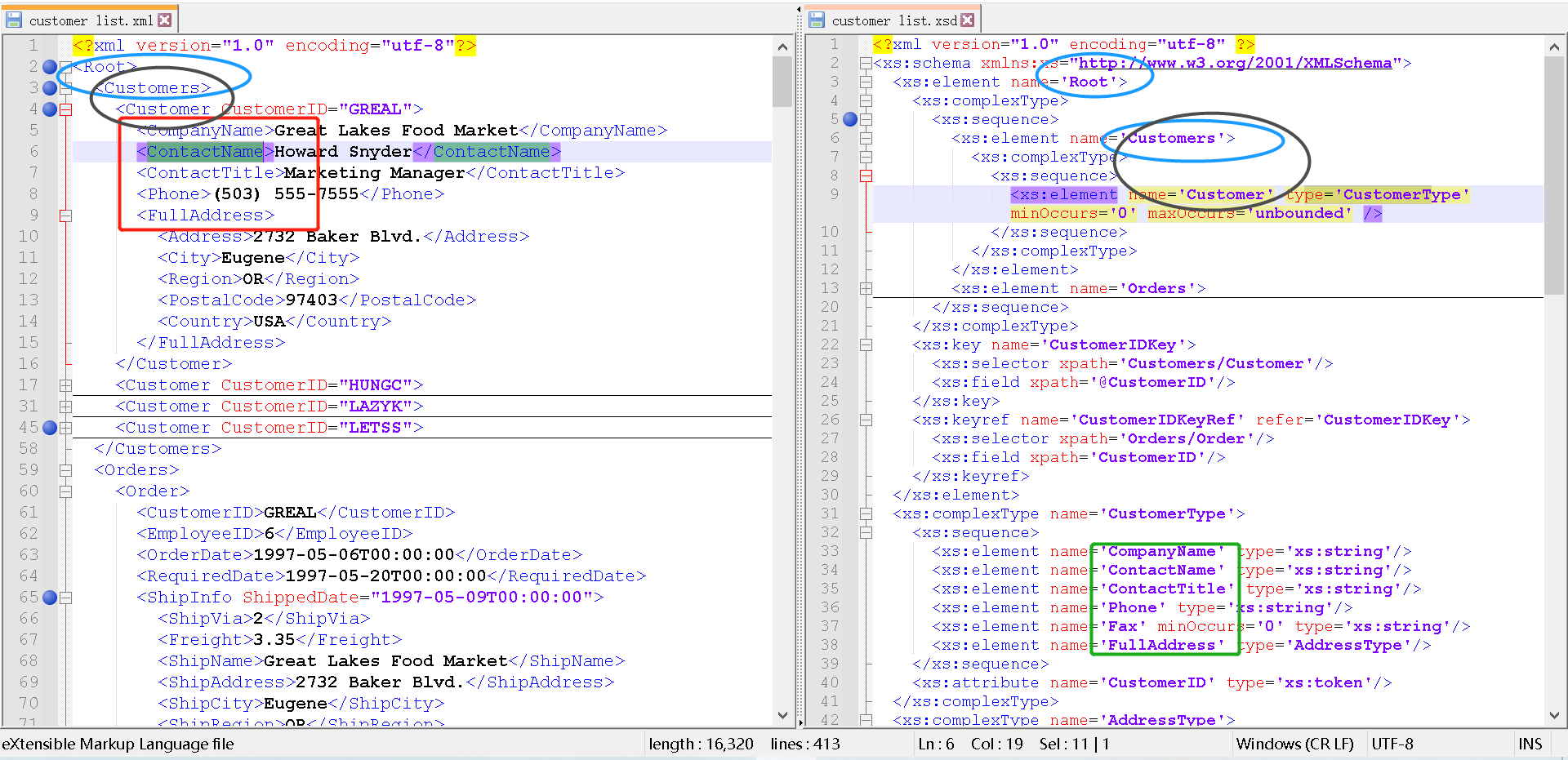
所以,如图所示,
- 在右侧xsd中(绿色方框)就定义了左侧XML的元素(红色方框)有:
<CompanyName><ContactName><ContactTitle>等; - 其中,
- 如蓝色椭圆所示,元素
<Customers>是根元素<Root>的子元素; - 如灰黑色椭圆所示,元素
<Customer>是元素<Customers>的子元素;
- 如蓝色椭圆所示,元素
更多关于XSD的元素和数据类型,您可以去网络上查找~
比如复合元素(complexType)是什么,在这个案例中,其实
<Root>、<Customers>就是复合元素。
4.1.2.2 属性
在 XSD 中,属性通过 attribute 来进行声明。语法如下:
<xs:attribute name="xxx" type="yyy"/>
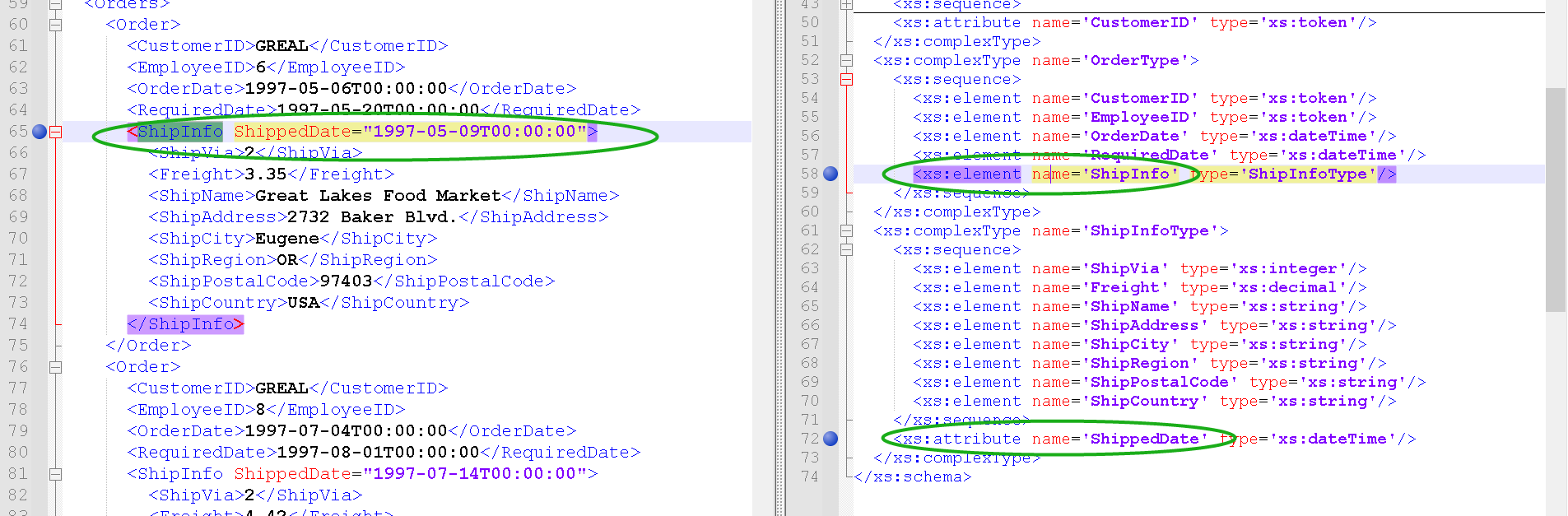
如图所示,在右侧XSD中就声明了:
元素<ShipInfo>的属性是ShippedDate,其属性值(左侧XML文档的第65行)应该是日期时间数据类型,也就是在右侧第72行看到的dateTime。
4.1.2.3 其它
当然,其它内容xsd的介绍,若您感兴趣的话可以去网络上查找,比如:
通过sequence元素来表示子元素出现的顺序,每个子元素可出现 0 到任意次数。

通过key元素来指定属性或元素值(或一组值)必须是指定范围内的键。

4.2 如何翻译XSD文档?
在翻译包含XSD的XML时,也是有2步:
- 检查翻译包
- 配置及测试过滤器
4.2.1 翻译包检查
在正式启动翻译之前,您需要检查源文档和翻译包。
您需要检查:
1、发送过来的翻译包是单个文档还是多个文件的翻译包;如果是多个文档的翻译包,哪几个文档需要翻译?
比如这个翻译包:文件包里有1个xml文档,以及一个*.xsd文档。
明确一点:xsd是架构文件,不需要翻译,需要翻译的是其XML文档
2、检查需要翻译的XML文档,看一下源文XML文档和xsd是否一致;
在这个案例中,您会发现:
- 左侧XML中的元素名和属性值和右侧XSD文档的定义是一致的,比如:XML第2行的根元素
<Root>,是右侧XSD文档第3行的name属性值; - 左侧XML的结构是按照右侧XSD定义的,比如:在右侧XSD文档中,第一个根元素
<xs:element>属性值Root,就是左侧的XML的根元素<Root>。
如果既然收到的翻译包没有明显的错误,那您就可以利用memoQ进行翻译了
我们前面一直讲:导入翻译文档,需要设置正确的过滤器。
那么,包含XSD的XML文档应该如何配置呢?
4.2.2 为包含XSD的XML配置过滤器
和配置DTD完全一致
我们在前面讲过,翻译包含DTD的XML文档,配置过滤器有三个步骤:
- 选择正确的过滤器
- 配置过滤器
- 检查过滤器。
翻译包含架构文件的XML操作也是一模一样
4.2.2.1 选择正确的过滤器
既然是XML文档,那么我们就用XML过滤器即可。
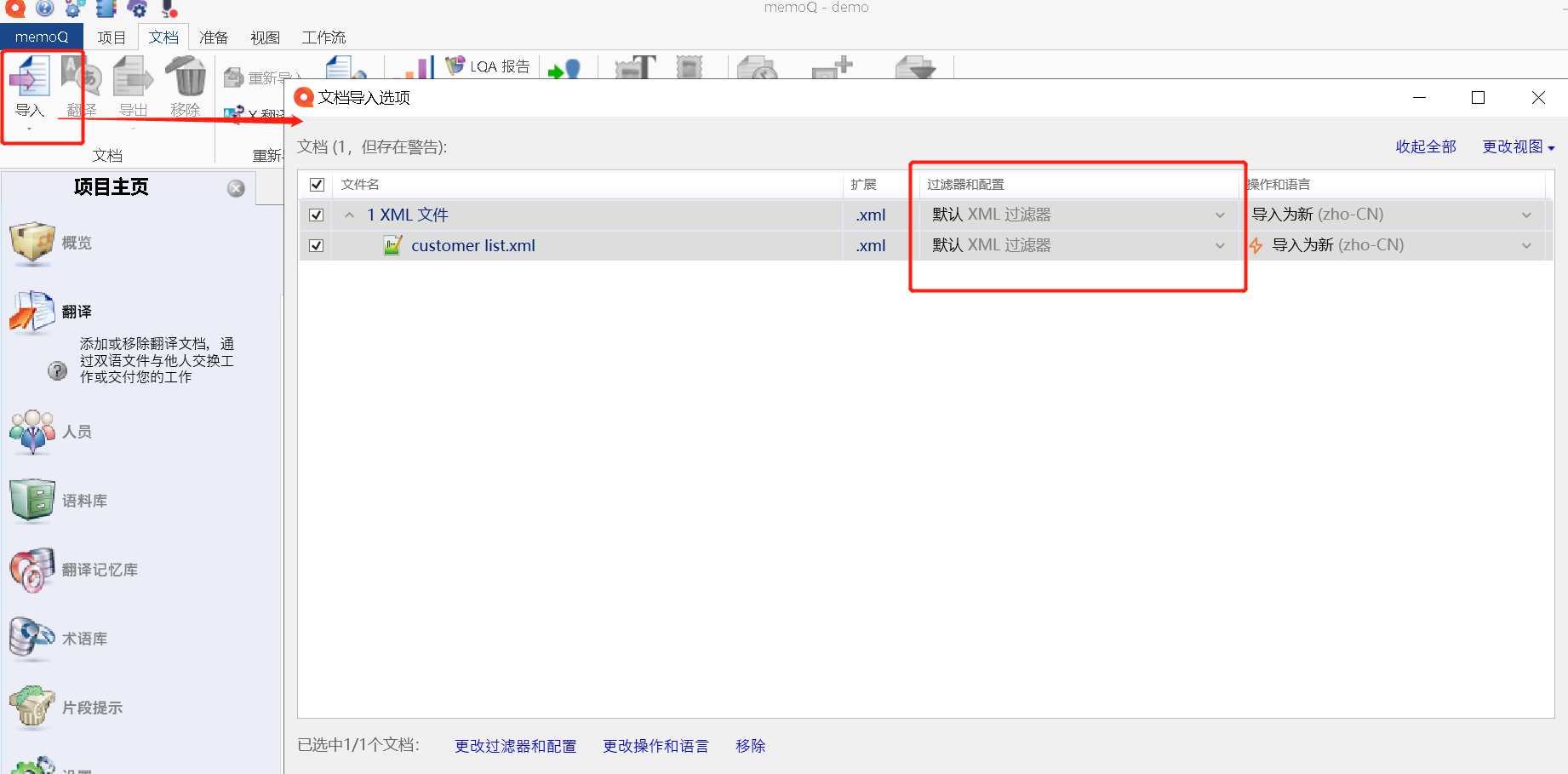
所以在导入时,选择:导入 -> 找到需要翻译的XML文档 ->选择 XML 过滤器,如图所示。
4.2.2.2 配置过滤器
默认的过滤器不能满足我们的需要,所以我们可以更改过滤器配置。
操作如下:
1、在文档导入选项 -> 点击“更改过滤器配置” -> 跳转出“文档导入设置”窗口;
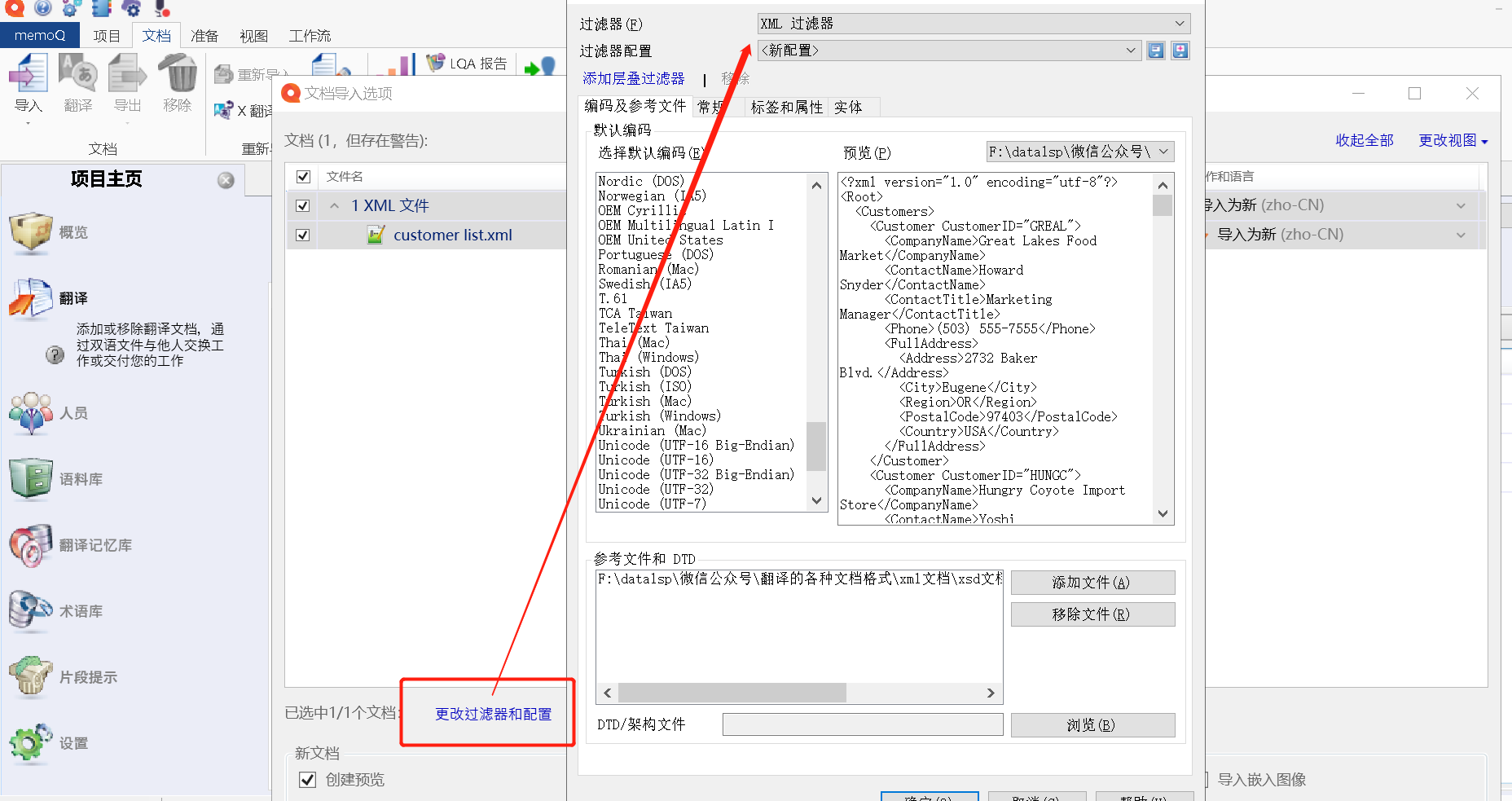
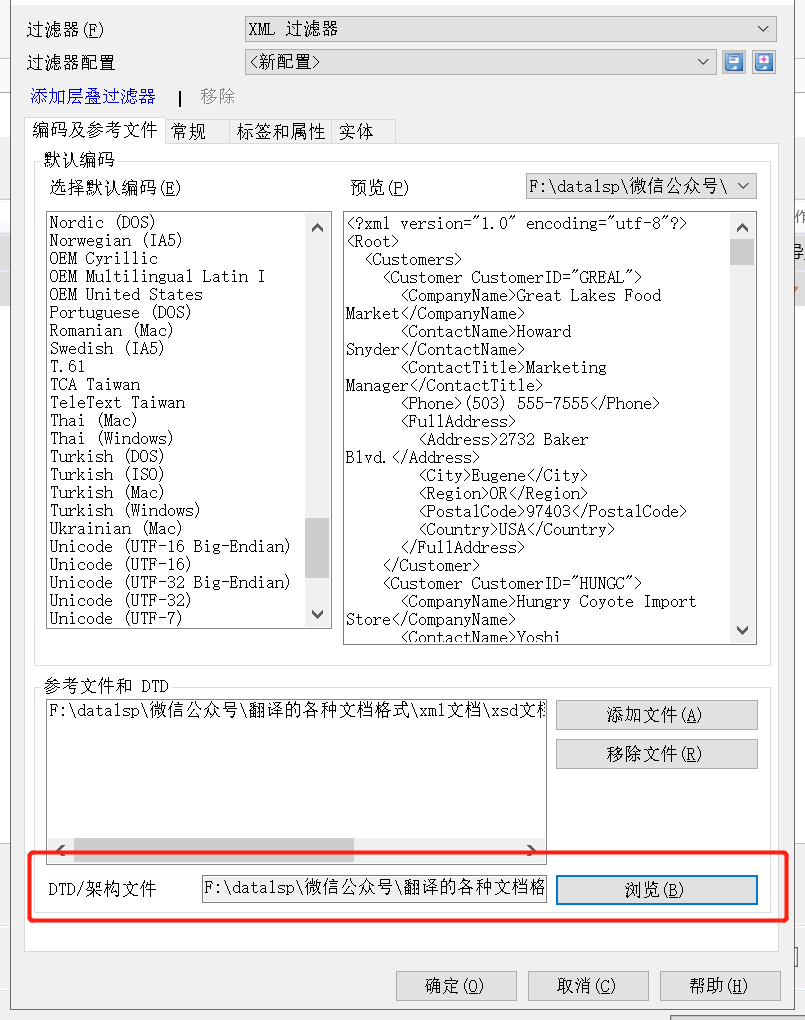
2、在“文档导入设置”窗口 -> 点击“DTD/架构文件”的“浏览” -> 选择正确的XSD文档;
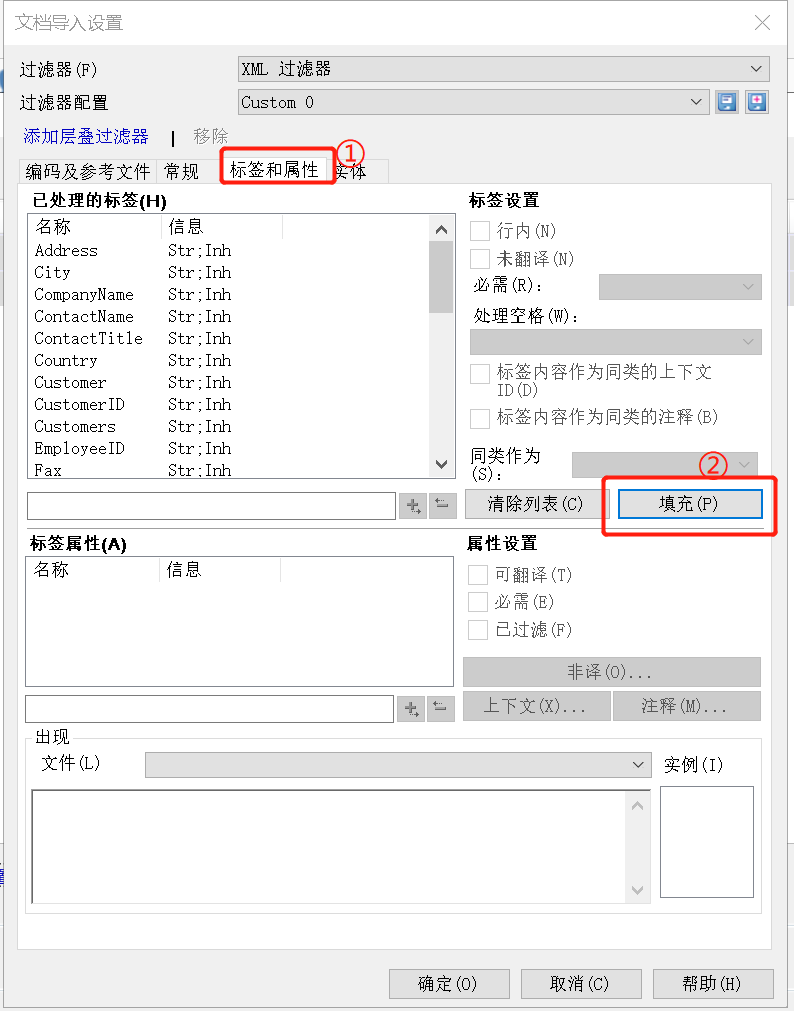
3、点击“①标签和属性” -> “②填充”
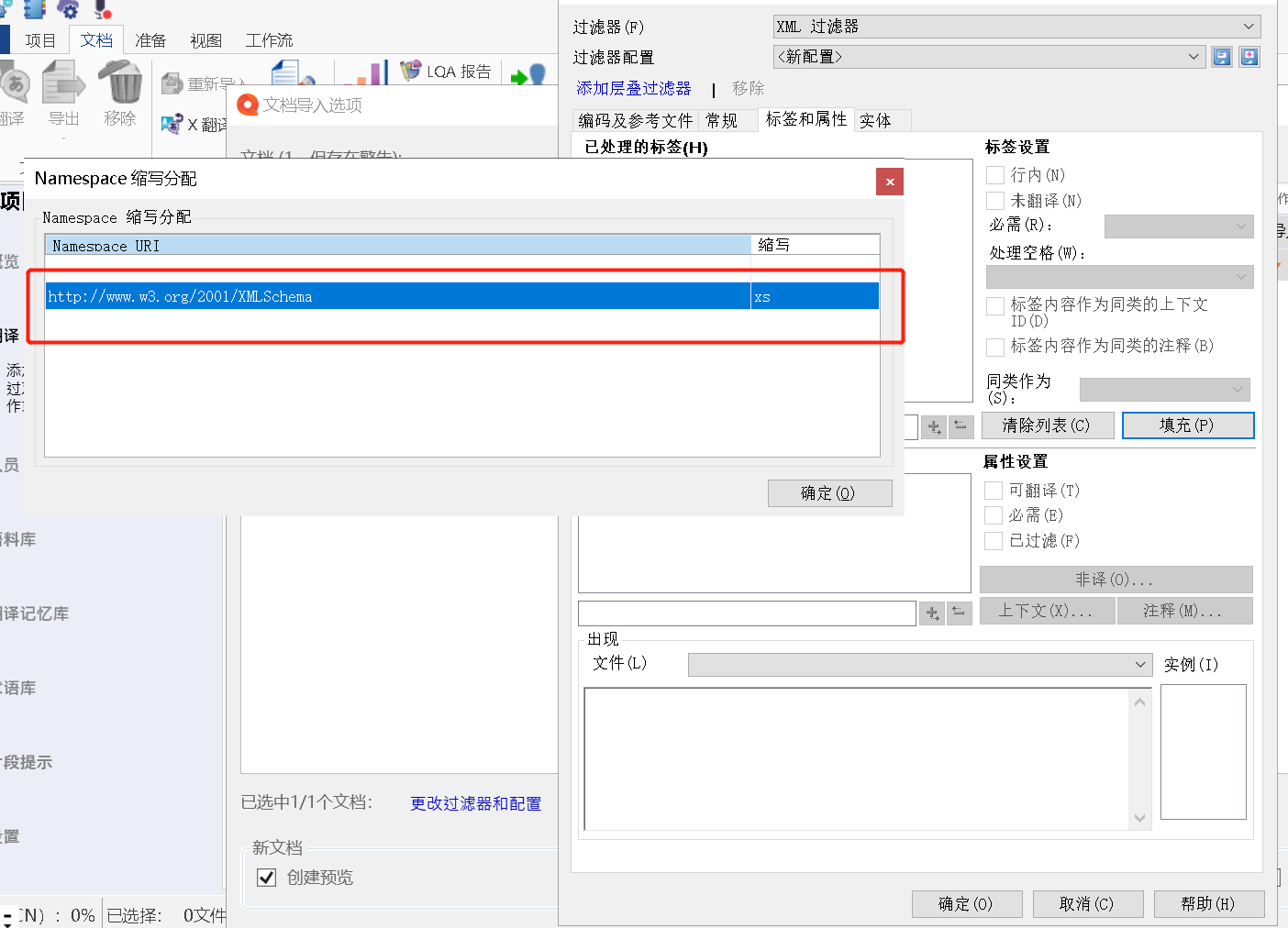
4、自动弹出Namespace URL -> 点击确定
5、配置如图所示的 ③标签 和 ④标签属性
- 在 ⑤标签设置” -> 设置哪些标签需要翻译、哪些标签属于行内标签
- 在 ⑥属性设置” -> 设置哪些标签属性需要翻译、哪些标签属于非译元素或上下文等条件
- 可以参考 ⑦实例 为每一个 ③标签 和 ④标签属性单独设置不同条件
- 还可以在 ⑧预览区预览实际文件内容
- 您还可以点击 ⑨保存过滤器,保存并 ⑩重命名一个新的过滤器,供下次使用。
更多关于XML翻译的解析器设置,请参考:如何翻译单语XML文档?
6、过滤器配置完成后,点击确定即可导入翻译文档~
4.2.2.3 检查过滤器
按照配置过滤器的操作,导入后如下图所示:
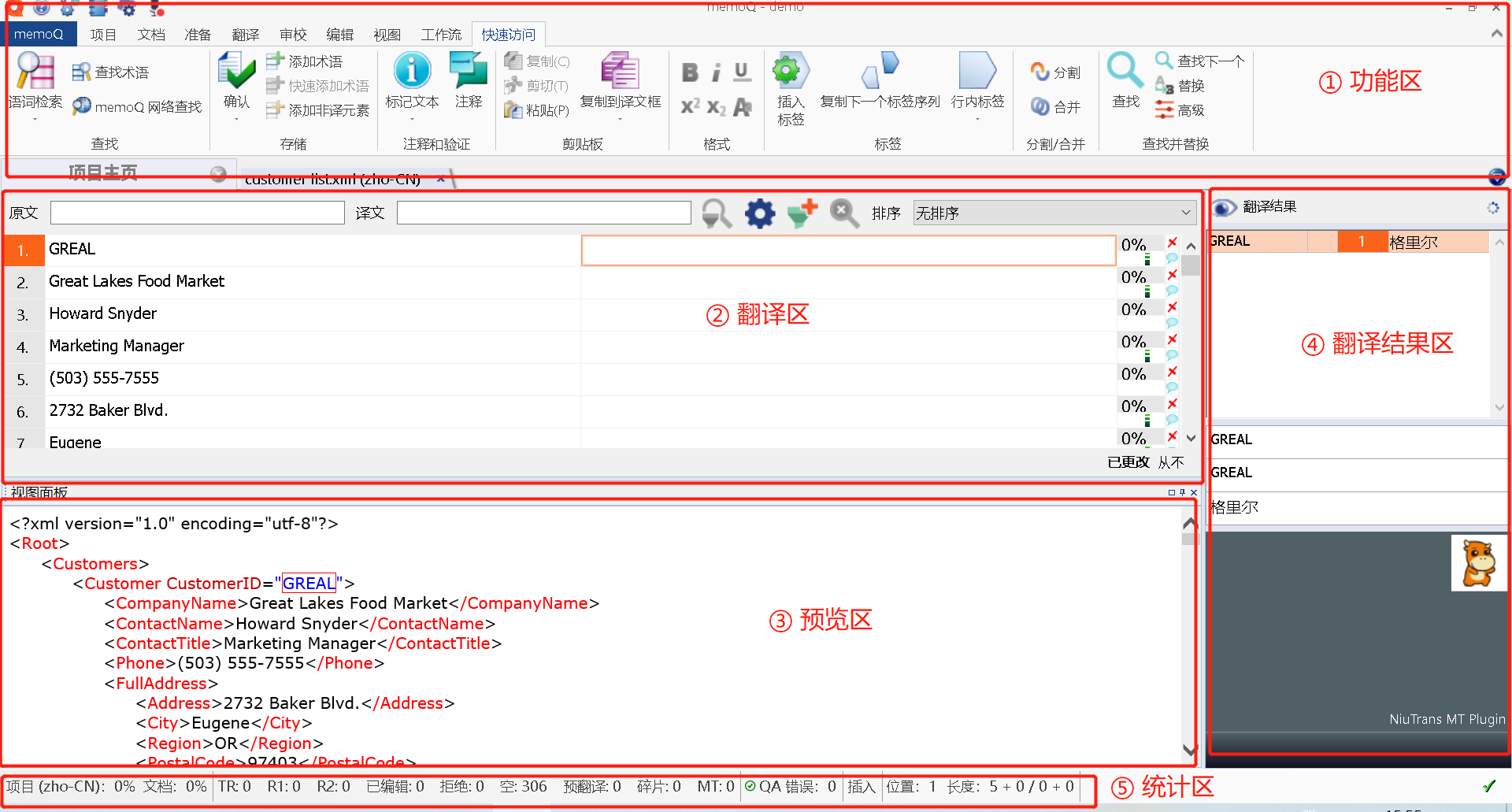
我们发现:编辑器的界面看上去都是正常的,比如:
- ① 是memoQ的功能区;
- ② 是memoQ的翻译区,我们可以在这里翻译;
- ③ 是memoQ的预览区,我们可以在这里预览原文;
- ④ 是memoQ的翻译结果区,所有的翻译结果(机器翻译、术语库、记忆库、片段提示等)都在这里呈现;
- ⑤ 是文档的统计栏,我可以看项目和文档的统计情况,比如进度、已编辑的句段统计、QA统计、原文译文的长度比例和字符数量等等。
4.2.3 测试译文
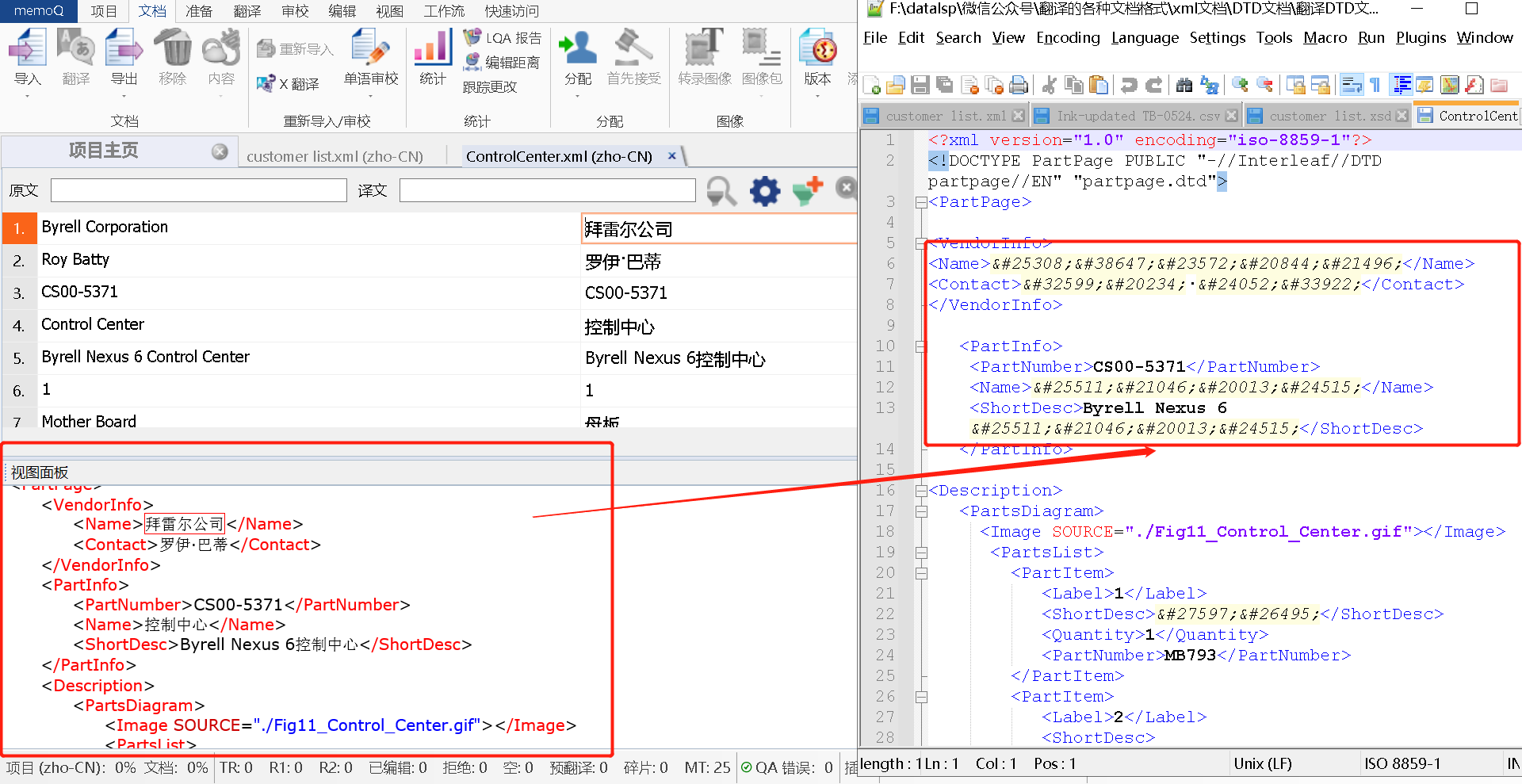
但是,过滤器配置完,不代表万事大吉
记得我们之前讲过的编码问题吗?如图所示,虽然翻译好了,但是导出后的编码有问题。
所以,为了保障译文的格式准确性,我们要测试,看一下译文是否可以按照目标语言顺利导出
比如在这里,我依然借助小牛机器翻译,利用MT进行了预翻译。
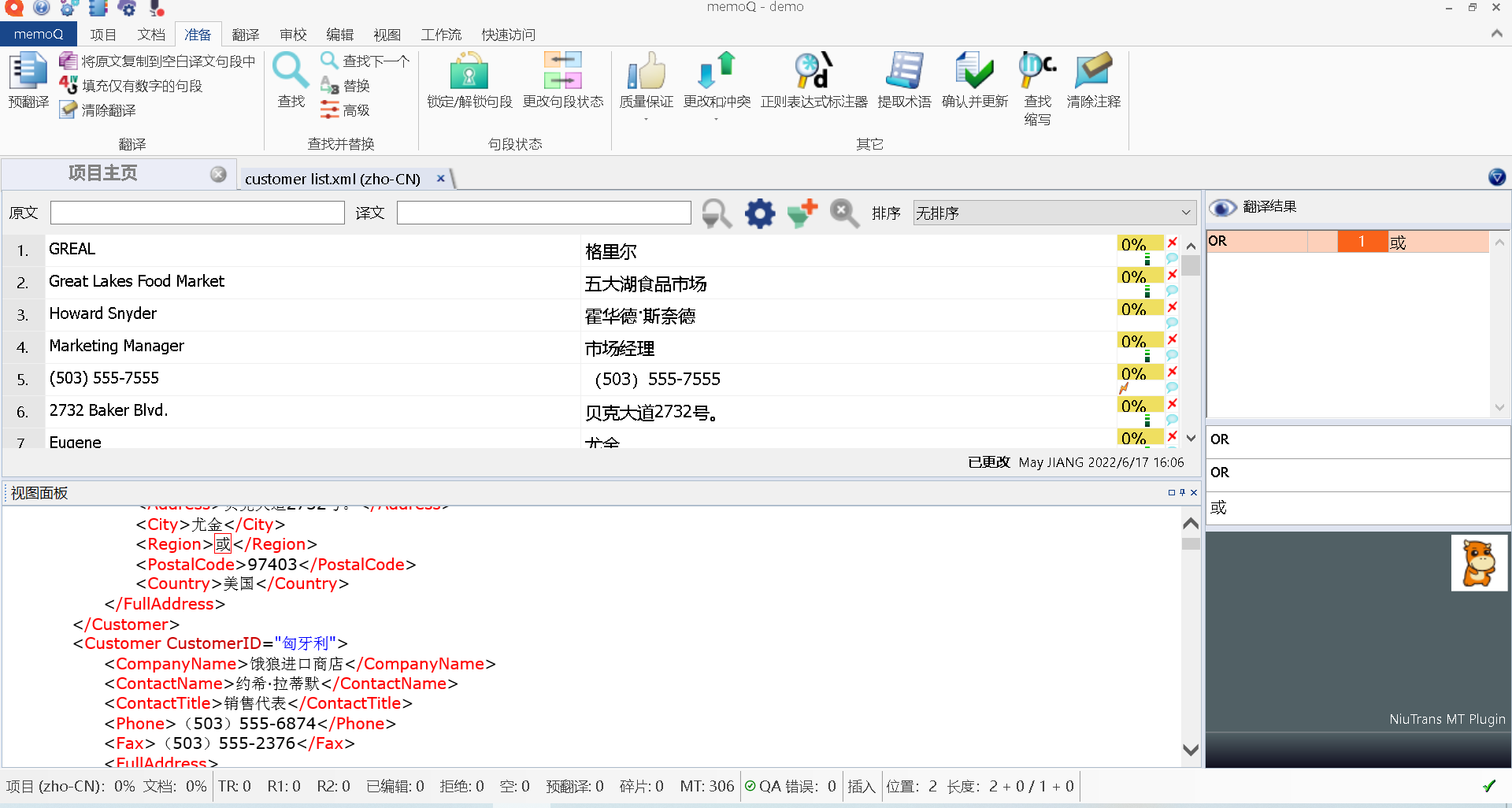
并把MT的译文导出检查一下~如果导出后的译文如图所示,可以顺利显示,就说明是OK的:
果然没问题,那我们就可以正式启动翻译啦~
更多关于memoQ翻译的操作,详见:memoQ 入门指南。
操作视频
© Copyright 2023. 大辞科技 沪ICP备17050550号  沪公网安备 31011402006110号
沪公网安备 31011402006110号




